










 本文探讨了生成式人工智能的发展,包括其在文本、图像、音乐和视频生成中的应用,以及从早期的AI、ML和DL技术进步到现代模型如GPT-3和DALL-E的演变。作者揭示了生成式AI的历史背景,强调了其对艺术、商业和日常生活的潜在影响。
本文探讨了生成式人工智能的发展,包括其在文本、图像、音乐和视频生成中的应用,以及从早期的AI、ML和DL技术进步到现代模型如GPT-3和DALL-E的演变。作者揭示了生成式AI的历史背景,强调了其对艺术、商业和日常生活的潜在影响。
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在本文中,我们将探索令人着迷的生成人工智能( AI ) 的世界及其突破性应用。生成式人工智能改变了我们与机器交互的方式,使计算机能够在没有明确人类指令的情况下进行创造、预测和学习。借助ChatGPT和OpenAI,我们见证了自然语言处理、图像视频合成等许多领域前所未有的进步。无论您是好奇的初学者还是经验丰富的从业者,本指南都将为您提供知识和技能,以驾驭令人兴奋的生成人工智能领域。因此,让我们深入研究并从我们正在进入的上下文的一些定义开始。
介绍了生成人工智能领域,其中包括创建新的、独特的数据或使用机器学习( ML ) 算法的内容。
它重点关注生成式人工智能在图像合成、文本生成、音乐创作等各个领域的应用,凸显生成式人工智能变革各行业的潜力。对生成式人工智能的介绍将提供该技术所处的背景,以及在人工智能、机器学习和深度学习( DL ) 的广阔世界中配置它的知识。然后我们将通过具体示例和最新进展详细介绍生成式人工智能的主要应用领域,以便您了解它可能对企业和社会产生的影响。
此外,了解生成人工智能当前最先进技术的研究历程将使您更好地了解最新发展和最先进模型的基础。
所有这一切,我们将涵盖以下主题:
- 了解生成式人工智能
- 探索生成人工智能领域
- 生成式人工智能研究的历史和现状
在本文结束时,您将熟悉生成人工智能的令人兴奋的世界、其应用、其背后的研究历史以及当前的发展,这些发展可能并且正在对企业产生颠覆性影响。
引入生成式人工智能
近年来,人工智能取得了长足的进步,是增长可观的领域之一是生成式人工智能。生成式人工智能是人工智能和深度学习的一个子领域,专注于通过使用机器学习技术对现有数据进行训练的算法和模型来生成新内容,例如图像、文本、音乐和视频。
为了更好地理解 AI、ML、DL 和生成式 AI 之间的关系,可以将 AI 视为基础,而 ML、DL 和生成式 AI 代表着日益专业化和集中化的研究和应用领域:
- 人工智能代表了创建能够执行任务、展示人类智慧和能力以及能够与生态系统交互的系统的广泛领域。
- 机器学习是一个专注于创建算法和模型的分支,使这些系统能够随着时间和训练进行学习和改进。机器学习模型从现有数据中学习,并随着数据的增长自动更新其参数。
- 深度学习是机器学习的一个子分支,因为它包含深度机器学习模型。那些深沉的模型称为神经网络,特别适合在计算机视觉或自然语言处理(NLP )等领域。当我们谈论 ML 和 DL 时模型,我们通常指的是判别模型,其目的是根据数据进行预测或推断模式。
- 最后,我们讨论生成式人工智能,这是深度学习的另一个分支,它不使用深度神经网络对现有数据进行聚类、分类或预测:它使用那些强大的神经网络模型来生成全新的内容,从图像到自然语言,从音乐到视频。
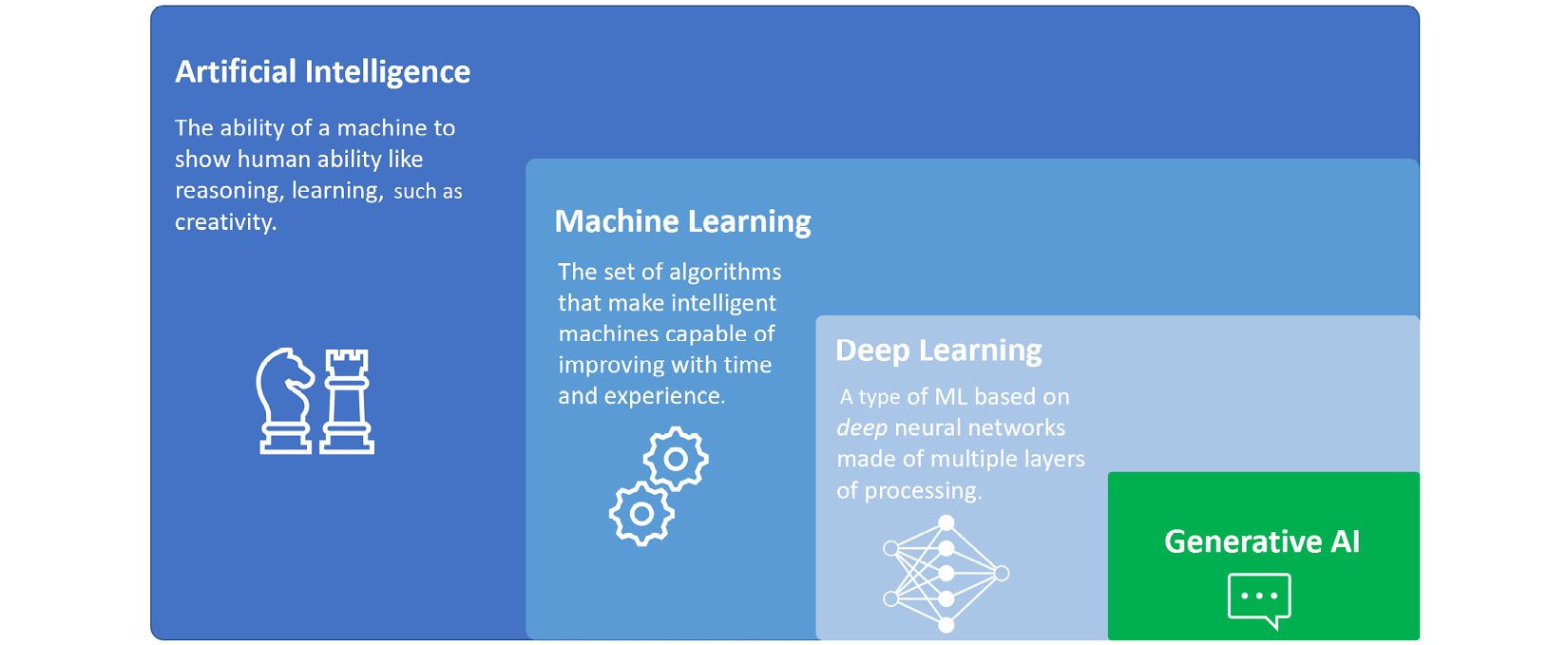
图 1 – AI、ML、DL 和生成式 AI 之间的关系
生成式人工智能模型可以在大量数据上进行训练,然后可以使用该数据中的模式从头开始生成新的示例。这种生成过程与判别模型不同,判别模型经过训练来预测给定示例的类别或标签。
生成人工智能的领域
近年来,生成式人工智能取得了重大进展并扩大了其应用范围涉及广泛的领域,例如艺术、音乐、时尚、建筑等等。在其中一些领域,它确实正在改变我们创造、设计和理解周围世界的方式。在其他方面,它正在改进并使现有流程和运营更加高效。
生成式人工智能应用于许多领域的事实也意味着它的模型可以处理不同类型的数据,从自然语言到音频或图像。让我们了解生成式人工智能模型如何处理不同类型的数据和领域。
文本生成
生成式人工智能最伟大的应用之一,也是我将介绍最多的应用它贯穿始终的是它以自然语言生成新内容的能力。事实上,生成式人工智能算法可用于生成新文本,例如文章、诗歌和产品描述。
例如,OpenAI 开发的 GPT-3 等语言模型可以在大量文本数据上进行训练,然后用于生成不同语言的新的、连贯的且语法正确的文本(无论是在输入还是输出方面) ,以及从文本中提取相关特征,例如关键字、主题或完整摘要。
以下是使用 GPT-3的示例:
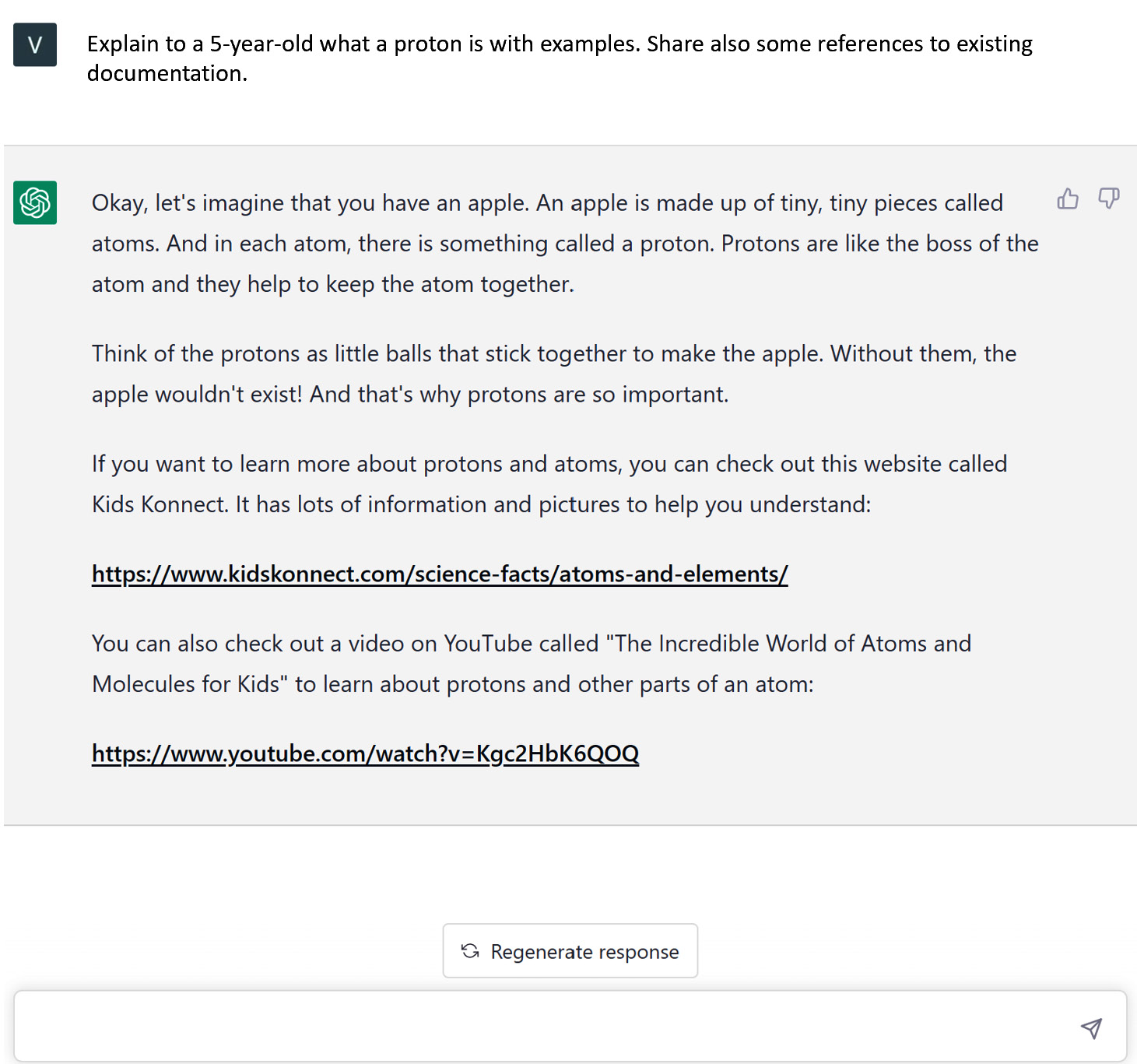
图 2 – ChatGPT 响应用户提示并添加引用的示例
图像生成
中的一个最早和最著名的生成式例子图像合成中的 AI 是I. Goodfellow 等人在 2014 年论文Generative Adversarial Networks中介绍的生成对抗网络( GAN ) 架构。GAN 的目的是生成与真实图像无法区分的逼真图像。此功能有几个有趣的业务应用程序,例如生成用于训练计算机视觉模型的合成数据集、生成逼真的产品图像以及为虚拟现实和增强现实应用程序生成逼真的图像。
这是一个不存在的人脸的例子,因为它们完全是由人工智能生成的:

图 3 – 由 GAN StyleGAN2 生成的假想面孔 https://this-person-does-not-exist.com/en
然后,在 2021 年,一个新的生成式人工智能模型被引入该字段由 OpenAI、DALL-E提供。与 GAN 不同,DALL-E 模型旨在根据自然语言的描述生成图像(GAN 以随机噪声向量作为输入),并且可以生成各种图像,这些图像可能看起来不真实,但仍然描述了所需的概念。
DALL-E在广告、产品设计、时尚等创意产业领域具有巨大的潜力,可以创造独特的创意形象。
在这里,您可以看到 DALL-E 从自然语言请求生成四个图像的示例:
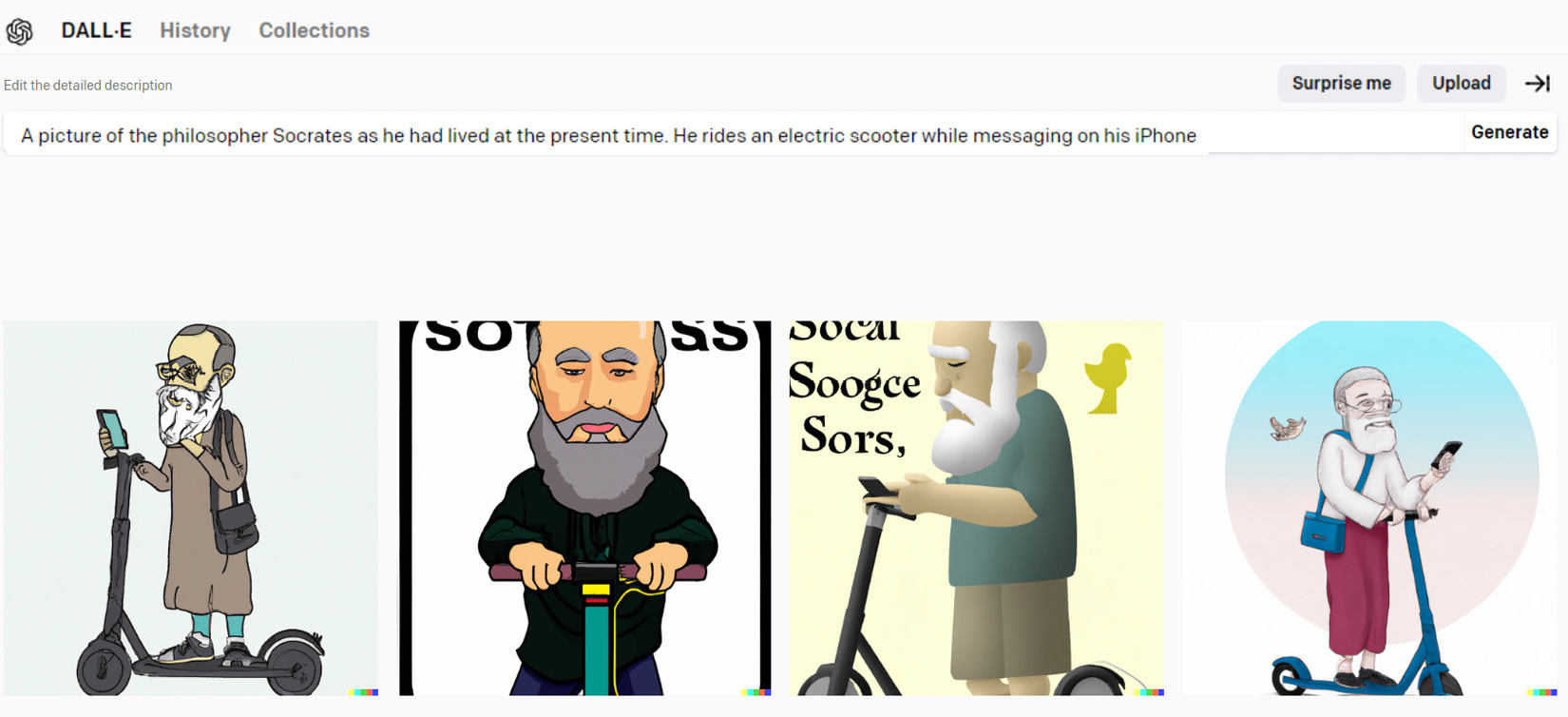
图 4 – DALL-E 使用自然语言提示作为输入生成的图像
请注意该文本和图像生成可以结合起来生产全新的材料。近年来,广泛使用的新人工智能工具都使用了这种组合。
Tome AI 就是一个例子,它是一种生成式讲故事格式,其功能还包括利用 DALL-E 和 GPT-3 等模型从头开始创建幻灯片。

图 5 – 完全由 Tome 使用自然语言输入生成的生成式 AI 演示
正如你可以看到,前面的人工智能工具完全能够根据我的简短自然语言输入创建一个演示文稿草稿。
音乐生成
用于音乐生成的生成人工智能的第一个方法可以追溯到 50 年代,研究领域包括算法作曲领域,一种使用算法生成音乐作品的技术。事实上,1957 年,Lejaren Hiller 和 Leonard Isaacson 创作了《伊利亚克弦乐四重奏组曲》(Illiac Suite for String Quartet),这是第一首完全由人工智能创作的音乐作品。从那时起,音乐生成人工智能领域一直是几十年来持续研究的主题。近年来的发展中,新的架构和框架已经在大众中广泛传播,例如谷歌在2016年推出的WaveNet架构,它已经能够生成高质量音频样本,或同样由 Google 开发的 Magenta 项目,该项目使用循环神经网络( RNN ) 和其他 ML 技术来生成音乐和其他形式的艺术。然后,在 2020 年,OpenAI 还发布了 Jukebox,这是一种生成音乐的神经网络,可以根据音乐和声音风格、流派、参考艺术家等定制输出。
这些框架和其他框架成为许多用于音乐生成的人工智能作曲家助手的基础。一个例子是由 Sony CSL Research 开发的 Flow Machines。这个生成式人工智能系统接受了大型音乐作品数据库的训练,可以创作出各种风格的新音乐。
在这里,您可以看到完全由 Music Transformer(Magenta 项目中的模型之一)生成的曲目示例:

图 6 – Music Transformer 允许用户聆听音乐表演由AI计算
生成式人工智能在音乐领域的另一个令人难以置信的应用是语音合成。这是确实可以找到许多人工智能工具,可以根据知名歌手的声音中的文本输入来创建音频。
例如,如果您一直想知道如果 Kanye West 演唱您的歌曲听起来会如何,那么您现在可以使用 FakeYou.com ( https://fakeyou.com/ )、Deep Fake Text to Speech 等工具实现您的梦想。
图 7 – 使用 UberDuck.ai 进行文本转语音合成
不得不说,结果真是令人印象深刻。如果您想玩得开心,您还可以尝试所有您喜欢的卡通人物的声音,例如小熊维尼……
接下来,我们将讨论视频的生成人工智能。
视频生成
用于视频生成的生成式人工智能与图像生成有着相似的发展时间表。事实上,视频生成领域的关键发展之一是GAN 的发展。由于它们能够准确地生成逼真的图像,研究人员也开始将这些技术应用于视频生成。基于 GAN 的视频生成最著名的例子之一是 DeepMind 的Motion to Video,它从单个图像和一系列运动。另一个很好的例子是 NVIDIA 的基于深度学习的视频到视频合成( Vid2Vid ) 框架,该框架使用 GAN 从输入视频合成高质量视频。
Vid2Vid 系统可以生成时间一致的视频,这意味着它们随着时间的推移保持平滑和逼真的运动。该技术可用于执行各种视频合成任务,例如:
- 将视频从一个域转换为另一个域(例如,将白天视频转换为夜间视频或将草图转换为逼真图像)
- 修改现有视频(例如,更改视频中对象的样式或外观)
- 从静态图像创建新视频(例如,将一系列静态图像制作成动画)
2022 年 9 月,Meta 的研究人员宣布全面推出Make-A-Video ( Make-A-Video ),这是一种新的人工智能系统,允许用户将自然语言提示转换为视频剪辑。在这样的技术背后,你可以认识到我们迄今为止在其他领域提到的许多模型——提示的语言理解、图像生成和图像生成的运动,以及人工智能作曲家制作的背景音乐。
总体而言,生成式人工智能多年来已经影响了许多领域,一些人工智能工具已经持续支持艺术家、组织和普通用户。未来似乎充满希望;然而,在讨论当今市场上的终极型号之前,我们首先需要更深入地了解生成式 AI 的根源、其研究历史以及最终形成当前OpenAI 模型的最新发展。
研究的历史和现状
在前面的章节中,我们概述了生成人工智能领域的最新和前沿技术,这些技术都是近年来发展起来的。然而,这一领域的研究可以追溯到几十年前。
我们可以这标志着 20 世纪 60 年代生成式人工智能领域研究的开始,当时 Joseph Weizenbaum 开发了聊天机器人 ELIZA,这是 NLP 系统的第一个例子。这是一个简单的基于规则的交互系统,旨在通过基于文本输入的响应来娱乐用户,它为 NLP 和生成人工智能的进一步发展铺平了道路。然而,我们知道现代生成人工智能是深度学习的一个子领域,尽管第一个人工神经网络( ANN ) 于 20 世纪 40 年代首次推出,研究人员面临着一些挑战,包括有限的计算能力和缺乏对大脑生物学基础的了解。因此,直到 20 世纪 80 年代,人工神经网络才获得太多关注,当时,除了新硬件和神经科学的发展之外,反向传播算法的出现也促进了人工智能的发展。ANN 的训练阶段。事实上,在反向传播出现之前,训练神经网络是很困难的,因为不可能有效地计算与每个神经元相关的参数或权重的误差梯度,而反向传播使得训练过程自动化并启用ANN 的应用。
然后,到了 2000 年代和 2010 年代,计算能力的进步,加上大量可用的训练数据,使深度学习变得更加实用并可供公众使用,从而促进了研究的发展。
2013年,金马与Welling 在他们的论文《自动编码变分贝叶斯》中介绍了一种新的模型架构,称为变分自动编码器(VAE)。VAE 是基于变分推理概念的生成模型。它们提供了一种以紧凑的形式表示的学习方式通过将数据编码到称为潜在空间的低维空间(使用编码器组件),然后将其解码回原始数据空间(使用 t解码器组件)。
VAE 的关键创新是引入了潜在空间的概率解释。编码器不是学习输入到潜在空间的确定性映射,而是将输入映射到潜在空间上的概率分布。这允许 VAE 通过从潜在空间采样并将样本解码到输入空间来生成新样本。
例如,假设我们想要训练一个 VAE,它可以创建看起来像真实的猫和狗的新图片。
为此,VAE首先拍一张猫或狗的照片将其压缩为较小的一组数字到潜在空间中,这些数字代表了图片最重要的特征。这些数字称为潜变量。
然后,VAE 获取这些潜在变量并使用它们创建一张看起来像是真实的猫或狗图片的新图片。这张新图片可能与原始图片有一些差异,但它看起来仍然应该属于同一组图片。
随着时间的推移,VAE 通过将生成的图片与真实图片进行比较并调整其潜在变量以使生成的图片看起来更擅长创建逼真的图片更像是真的。
VAE 为生成人工智能领域的快速发展铺平了道路。事实上,仅仅一年后,Ian Goodfellow 就提出了 GAN。与主要元素是编码器和解码器的 VAE 架构不同,GAN 由两个神经网络组成——一个生成器和一个鉴别器——它们针对每个这是一场零和游戏。
生成器创建假数据(在图像的情况下,它会创建一个新图像),这些数据看起来像真实数据(例如,猫的图像)。鉴别器接收真实数据和虚假数据,并试图区分它们——这就是我们艺术伪造者例子中的批评者。
在训练过程中,生成器试图创建可以欺骗鉴别器的数据,让其认为它是真实的,而鉴别器则试图更好地区分真实数据和虚假数据。这两个部分在称为对抗性训练的过程中一起训练。
随着时间的推移,生成器会更好地创建看起来像真实数据的假数据,而鉴别器会更好地区分真实数据和假数据。最终,生成器变得非常擅长创建虚假数据即使鉴别器也无法区分真实数据和虚假数据。
这是完全由GAN生成的人脸示例:

图 8 – 真实感 GAN 生成的脸部示例(摘自 Progressive Growing of GANs for Improve Quality, Stability, and Variation,2017:https://arxiv.org/pdf/1710.10196.pdf)
这两种模型(VAE 和 GAN)都旨在生成与原始样本无法区分的全新数据,并且自构思以来,它们的架构已经得到改进,并与 Van den Oord 及其提出的 PixelCNN 等新模型的开发并驾齐驱。团队以及由 Google DeepMind 开发的 WaveNet,引领了音频和语音生成的进步。
2017 年实现了另一个伟大的里程碑,谷歌研究人员在论文《Attention Is All You Need》中介绍了一种名为Transformer的新架构。它是语言领域的革命因为它允许并行处理,同时保留有关语言上下文的记忆,优于之前的尝试基于 RNN 或长短期记忆( LSTM ) 框架的语言模型。
变形金刚确实是 Google 于 2018 年推出的称为Transformers 双向编码器表示( BERT )的大规模语言模型的基础,并且它们很快成为 NLP 实验的基线。
变形金刚是也是 OpenAI 引入的所有生成预训练( GPT ) 模型的基础,包括ChatGPT 背后的模型 GPT-3 。
尽管当年有大量的研究和成果,但直到2022年下半年,公众的普遍注意力才转向生成式AI领域。
2022 年被称为生成人工智能年并非偶然。这一年,强大的人工智能模型和工具在公众中广泛传播:基于扩散的图像服务(MidJourney、DALL-E 2 和 Stable Diffusion)、OpenAI 的 ChatGPT、文本转视频(Make-a-Video 和Imagen Video)和文本转 3D(DreamFusion、Magic3D 和 Get3D)工具均可供个人用户使用,有时也是免费的。
这产生了破坏性影响,主要原因有两个:
- 一旦生成式人工智能模型向公众广泛传播,每个个人用户或组织都有可能尝试并欣赏其潜力,即使不是数据科学家或机器学习工程师。
- 这些新模型的产出及其内在的创造力客观上令人惊叹,而且常常令人担忧。人们迫切呼吁个人和政府进行适应。
因此,在不久的将来,我们可能会见证个人使用和企业级项目对人工智能系统的采用激增。
概括
在本文中,我们探索了生成式人工智能的令人兴奋的世界及其各个应用领域,包括图像生成、文本生成、音乐生成和视频生成。我们了解了由 OpenAI 训练的 ChatGPT 和 DALL-E 等生成式 AI 模型如何使用深度学习技术来学习大型数据集中的模式并生成既新颖又连贯的新内容。我们还讨论了生成人工智能的历史、起源以及研究现状。
目标是为生成人工智能的基础知识提供坚实的基础,并激励您进一步探索这个迷人的领域。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











