







使用vicuna7b-v0跑出来的模型,根据这个跑出来的模型,写一个小的demo展示一下,后面再完善ui和管理端
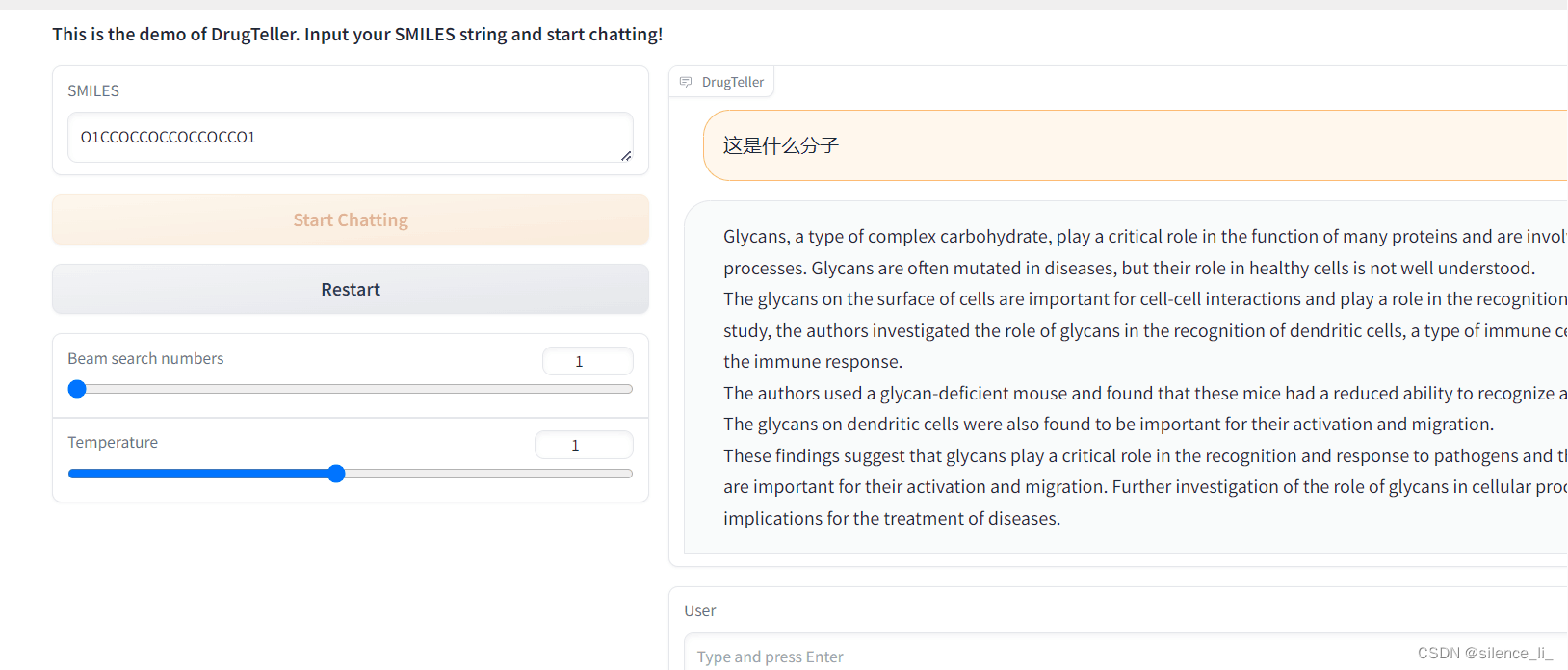
写出来的小demo大致长这个样子(简单一写,等回头写前后端的同学写好了ui再合起来)
目前可以做到给一个smiles,进行提问,回答该smiles的一些特点之类的。(但是vicuna对中文来说不太友好,建议提问的时候用英文提问会更精确一些,因为训练编的QA也是英文的)
目前有个缺点,就是7b的模型,精度不高,回答的问题有些地方有错误,还需要再调一下
import argparse
import os
import random
import numpy as np
import torch
import torch.backends.cudnn as cudnn
import gradio as gr
from pipeline.common.config import Config
from pipeline.common.dist_utils import get_rank
from pipeline.common.registry import registry
from pipeline.conversation.conversation import Chat, CONV_VISION
# imports modules for registration
from pipeline.datasets.builders import *
from pipeline.models import *
from pipeline.processors import *
from pipeline.runners import *
from pipeline.tasks import *
#定义命令参数解析函数
def parse_args():
parser = argparse.ArgumentParser(description="Demo")
parser.add_argument("--cfg-path", required=True, help="path to configuration file.")
parser.add_argument("--gpu-id", type=int, default=0, help="specify the gpu to load the model.")
parser.add_argument(
"--options",
nargs="+",
help="override some settings in the used config, the key-value pair "
"in xxx=yyy format will be merged into config file (deprecate), "
"change to --cfg-options instead.",
)
args = parser.parse_args()
return args
#随机种子
def setup_seeds(config):
seed = config.run_cfg.seed + get_rank()
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
cudnn.benchmark = False
cudnn.deterministic = True
# ========================================
# Model Initialization
# ========================================
#初始化chat
print('Initializing Chat')
args = parse_args()
cfg = Config(args)
use_amp = cfg.run_cfg.get("amp", False)
model_config = cfg.model_cfg
model_config.device_8bit = args.gpu_id
model_cls = registry.get_model_class(model_config.arch)
print(model_config)
model = model_cls.from_config(model_config)
model = model.to('cuda:{}'.format(args.gpu_id))
vis_processor_cfg = cfg.datasets_cfg.cc_sbu_align.vis_processor.train
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
chat = Chat(model, vis_processor, device='cuda:{}'.format(args.gpu_id))
print('Initialization Finished')
# ========================================
# Gradio Setting
# ========================================
def gradio_reset(chat_state, img_list):
if chat_state is not None:
chat_state.messages = []
if img_list is not None:
img_list = []
return None, gr.update(value=None, interactive=True), gr.update(placeholder='Please input your SMILES string first', interactive=False),gr.update(value="Input SMILES & Start Chat", interactive=True), chat_state, img_list
@torch.no_grad()
def upload_img(gr_img, text_input, chat_state):
if gr_img is None:
return None, None, gr.update(interactive=True), chat_state, None
chat_state = CONV_VISION.copy()
img_list = []
print(gr_img)
print(chat_state)
with torch.cuda.amp.autocast(use_amp):
llm_message = chat.upload_img(gr_img, chat_state, img_list)
return gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list
def gradio_ask(user_message, chatbot, chat_state):
if len(user_message) == 0:
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
chat.ask(user_message, chat_state)
chatbot = chatbot + [[user_message, None]]
return '', chatbot, chat_state
@torch.no_grad()
def gradio_answer(chatbot, chat_state, img_list, num_beams, temperature):
with torch.cuda.amp.autocast(use_amp):
llm_message = chat.answer(conv=chat_state,
img_list=img_list,
num_beams=num_beams,
temperature=temperature,
max_new_tokens=300,
max_length=2000)[0]
chatbot[-1][1] = llm_message
return chatbot, chat_state, img_list
title = """<h1 align="center">Demo of DrugTeller</h1>"""
description = """<h3>This is the demo of DrugTeller. Input your SMILES string and start chatting!</h3>"""
#TODO show examples below
with gr.Blocks() as demo:
gr.Markdown(title)
gr.Markdown(description)
with gr.Row():
with gr.Column(scale=0.5):
smiles = gr.Textbox(label="SMILES")
upload_button = gr.Button(value="Input SMILES & Start Chat", interactive=True, variant="primary")
clear = gr.Button("Restart")
num_beams = gr.Slider(
minimum=1,
maximum=10,
value=1,
step=1,
interactive=True,
label="Beam search numbers",
)
temperature = gr.Slider(
minimum=0.1,
maximum=2.0,
value=1.0,
step=0.1,
interactive=True,
label="Temperature",
)
with gr.Column():
chat_state = gr.State()
img_list = gr.State()
chatbot = gr.Chatbot(label='DrugTeller')
text_input = gr.Textbox(label='User', placeholder='Please input your SMILES string first', interactive=False)
upload_button.click(upload_img, [smiles, text_input, chat_state], [smiles, text_input, upload_button, chat_state, img_list])
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
gradio_answer, [chatbot, chat_state, img_list, num_beams, temperature], [chatbot, chat_state, img_list]
)
clear.click(gradio_reset, [chat_state, img_list], [chatbot, smiles, text_input, upload_button, chat_state, img_list], queue=False)
demo.launch(share=True, enable_queue=True)















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









