







这个其实是遇到的一道面试题,其题目描述也很简单,BIO和NIO消耗的cpu和内存哪个比较大。因为确实从来没遇到过去从这个角度去比较NIO和BIO的,所以我尝试变解释原理边分析,但是整个过程对方三次认为我跑题了,强调回到他问题的本身,我猜他认为是我在炫面试技巧,回避直接回答他的问题,多次强调先给出答案,所以整个过程其实并没有真的深入去分析。但我觉得这个问题有点意思,就记录一下,从我掌握的知识来分析一下。
基础概念对其
首先来说,我们如何去分析一个cpu的使用量的问题,通常cpu使用量有两个指标:使用率和负载。而这两个指标又有两个维度:系统层面和进程层面。
cpu消耗衡量指标
1. cpu使用率:
线程维度的cpu使用率,描述的是在统计周期内,当前线程占用的cpu时间。在linux中使用百分比来呈现,但是背后的统计方式简单粗暴理解就是当前线程占用的cpu的tick数和总的tick数的归一化比值。100%的含义是这个进程在统计窗口内完整占用了1个逻辑核心。50%就表示统计窗口内,当前进程只是占用了一个逻辑核心的一般时间的cpu,比如统计周期为1s,100%就表示当前线程在这1s内完整占用了一个cpu、200%表示在这1s内完整占用了2个cpu,50%表示在这1s内,只占用了一个cpu的500ms的cpu时间。
系统维度:其实就是看各个阶段(场景)使用的cpu,比如内耗占用的cpu、用户态占用的cpu、空闲、中断处理占用的cpu等。同样是百分比呈现,但是这里的百分比的含义和进程视角就有些不一样,这里的百分比是各个场景对cpu使用的一个占比。比如用户态占用cpu是10%,空闲90%,表示的是在这1s内,用户态消耗了100ms的cpu时间片,而其他900ms,cpu都是空闲的。
2. cpu的load(负载)
其实要理解好cpu的load,就要理解下操作系统通过抽象进程/线程来管理cpu后,进程/线程的状态。在unix操作系统中,对cpu的load的计算其实就是当前系统中处于可运行状态的线程数(运行态+就绪态),但是在linux中,有个大佬觉得不合理,通过补丁的方式将阻塞态的线程也计算进来了。即linux中cpu的load是当前系统中可运行态+阻塞态的线程数。
如何分析:
线程是cpu调度的最小单位,要分析cpu的使用情况,说白了,着手点就是线程。分析cpu的使用率,那就看有多少线程真正占用了cpu时间片的;分析cpu的load,就看线程的状态。
内存消耗衡量指标
内存的指标其实就简单直观很多,就是看占用内存的大小。对于内存分析,其实我理解更多的就是看操作系统内存管理,以及在对应场景会使用到什么样的内存。比如这里分析IO内存,那可能涉及到的内存就有内核空间内存、文件系统的page cache、用户态的缓冲区等。
NIO、BIO概念理解
要回答上面的问题,第二个需要明确的NIO和BIO的概念。
为什么这么说,因为10个人对NIO和BIO就会有11中不同的理解,所以如果不达成一致理解的前提,就会有11中结论,且相互不服气。
早期的BIO,其实整个IO过程都需要cpu的参与的,在IO过程中,cpu就只能一直等待IO结束,IO的过程就会大大浪费CPU。众所周知,IO的效率远远低于CPU,所以这样就会大大浪费cpu。为了解决这个问题,其实引入的就是DMA,CPU只是发起IO请求,然后整个IO过程都是在DMA的控制下进行,这就有个问题了,cpu怎么知道DMA什么时候IO已经执行完成了呢?一种方式就是IO没结束,发起IO的线程就阻塞住,直到IO就绪。
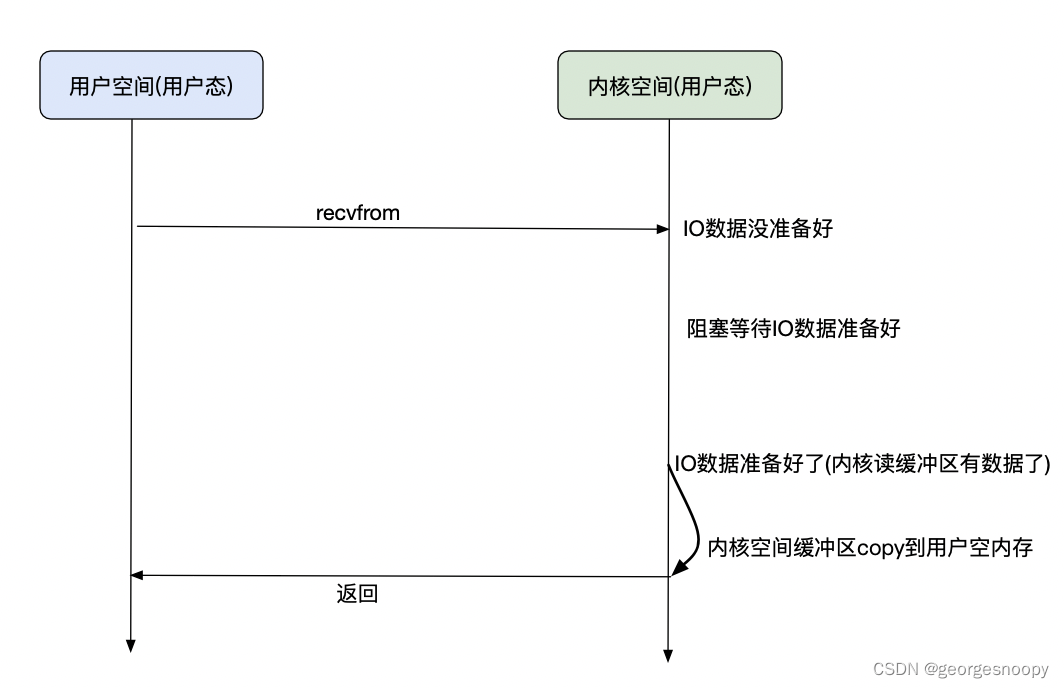
NIO就是非阻塞式IO,这里就特指是当应用线程发起IO调用后,IO没有完成,也会立即返回EWOULDBLOCK,而不会阻塞线程。那剩下的问题就是当IO完成后,应用线程如何知道IO就绪了呢?一个朴素的想法就是轮询,而NIO也是这么干的,不断的去轮询。
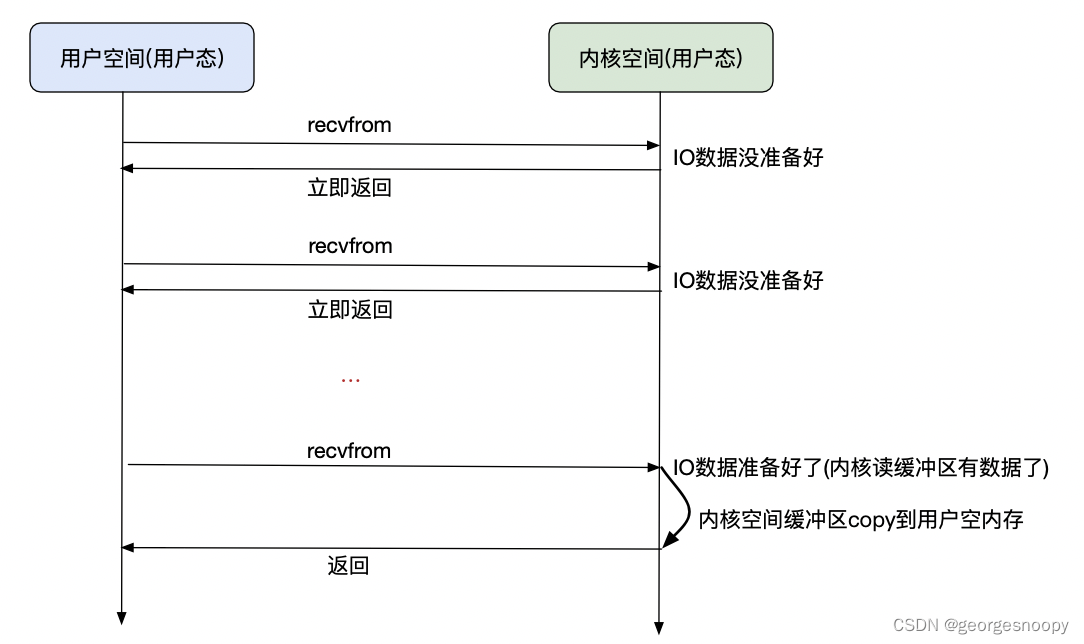
用户线程轮询其实也是调用国内recvFrom系统调用,这个系统调用就是IO就绪了就会将内核空间缓存copy到用户空间;如果IO没有就绪,要么就是阻塞当前线程、要么就是返回EWOULDBLOCK。因为轮询其实是在执行系统调用,所以每次轮询都是用户态-->内核态-->用户态,这就会有大量的线程上下文切换。
对于BIO,发起recvFrom系统内调用的时候,如果IO没就绪,那么当前线程就会被内核态阻塞,其实这个时候是会释放出cpu的,cpu依然可以是给其他线程使用,只是说当前线程不能做其他的事情。
对于NIO,无非是发起recvFrom系统内调用的时候,如果IO没就绪,不阻塞当前线程,而是立即返回EWOULDBLOCK,而用户线程不断的去调用recvFrom轮询。
仅仅从这个过程上看,是不是看起来NIO还不如BIO,因为NIO反而多了不断轮询系统调用的开销,而BIO反而是阻塞了当前线程,少了轮芯系统调用的开销。看起来BIO效率更高。但实时上,现在几乎是没有生产环境使用BIO了,反而都是NIO。因为NIO可以利用多路复用,大大提升IO的吞吐量。
如果要支持大量并发的IO请求,如果使用BIO,那么就只能是一个IO请求过来,创建一个线程来支持,但是一个系统支持的线程数是有限的,所以这种方式这种方式能够支撑的IO吞吐量是有限的。
如果使用的是NIO,如果直接让发起用户IO请求的线程去轮询,那么跟BIO没有区别,甚至更差,所以我们就自己想办法,我们自己:用户线程发起IO请求后,将fd记录下来,然后专门搞个线程去轮询:
while(true){
foreach(fd){
if(recvFrom(fd)==EWOULDBLOCK){// 已经就绪。前提是fd是非阻塞的
read(fd) // IO已经就绪了,那么read()读取io数据就不会阻塞了
}
}
}这就有个问题,如果IO都没有就绪,那么这个线程只要获得cpu时间片,那就无限去轮询。这样的话,就有有个问题,轮询的线程的cpu使用率就会飙升,就会发现这个轮询线程的cpu使用率是100%(统计周期沾满一个cpu),而且线程上线文切换也就非常频繁。所以这样就在轮询的的时候sleep一段时间
while(true){
foreach(fd){
if(recvFrom(fd)==EWOULDBLOCK){// 已经就绪。前提是fd是非阻塞的
read(fd) // IO已经就绪了,那么read()读取io数据就不会阻塞了
sleep(1)
}
}
}但是这个会导致吞吐能力极差,因为很可能在刚好要 sleep 的时候,所有的 fd 都准备好 IO 数据,而这个时候却要硬生生的等待 1s,才能读取到IO数据。
所以怎么办,一个更好的办法就是,这个轮询让操作系统内核去做,这样操作系统内核就可以有有一些优化操作。而对于linux系统,就是select、poll、epoll三个多路IO复用相关的系统调用。
也就是说,当用户线程发起IO请求,是调用了select、poll、epoll的一个,操作系统内核会使用reactor模式,来实现多路复用,这样就避免了用户线程轮询导致的频繁的用户态-->内核态-->用户态的切换,导致大量的线程上下文切换。
另外,因为IO都是在内核完成的,实际上select、poll、epoll也的实现也不是无限轮询,而是当有IO就绪的时候,才会唤醒轮询线程。
select、poll、epoll的本质其实就是一个fd的池子,然后有一个轮询线程会去不断检查池子里的fd,当fd就绪后,就会将io数据从内核空间copy到用户空间,这样用户线程就能够不阻塞的读取到io数据了。
对于select、poll系统调用,当用户线程调用后,其实就是提交了一个fd给这个池子,然后当有fd就绪后,操作系统内核就会唤醒这个轮询线程,但是这个时候轮询线程不知道是哪个fd就绪了,所以就要轮询一遍所有的fd,才知道是哪个就绪了。虽然这个轮询是在内核执行,避免了线程上下文的切换,但是其内部是使用了数组结构,所以需要O(N)的遍历。所以效率不高。
而epoll就更进一步了,其内部管理fd采用了红黑树+队列。当IO就绪的时候,会将就素的fd放在队列中,那么轮询线程实际上就不需要轮询了,效率提高。另外使用红黑树替代了数组,那么fd的管理效率也就变成了O(lgN)了。所以整体上epoll的多路复用的效率是非常高的。
但是epoll的使用是有限制的,因为当IO就绪的时候,将fd放到就绪队列中,是依赖回调来完成的,这就要求文件系统实现poll接口,这样才能实现回调。参考深入理解 Linux 的 epoll 机制及epoll原理 - 知乎
- ext2,ext4,xfs 等这种常见文件系统,没有实现poll接口,所以通过这些文件系统的IO,是没办法使用epoll多路复用的。
- socket fd,eventfd,timerfd 这些实现了 poll 接口,所以是可以使用epoll多路复用的。
- select/poll来说,发起IO请求,fd会先加入到用户态的集合汇总,然后系统调用将整个集合copy到内核空间;而epoll是将fd集合维护在内核空间,所以每次IO请求将fd添加到fd集合都是一次系统调用。
- select的fd集合使用的是数组;poll使用的链表;epoll使用的是红黑树+接续队列。所以select/poll当io就绪后就只能遍历整个fd集合来判断有哪些fd就绪了;而epoll不需要,只是从就绪队列中获取就好。
- 总结起来:当IO并发量小(监测的fd数量少),并且io比较快,fd集合中大部分都是就绪的,这种情况select/poll反而效率比较高,比如redis这种其实更适合poll;但当监听的fd数量较多,且单位时间仅部分fd活跃的情况下,使用epoll的性能会很好。
所以,我们会发现,java的文件IO是不支持多路复用的,而Socket是实现了epoll实现多路复用的,所以java的nio会发现只有Socket支持SelectableChannel,linux版本的jvm底层使用的就是epoll
多路复用本质上还是轮询,即便是epoll,通过内核的优化后,利用了DMA的中断信号,通过回调将就绪的IO放到了队列中,只不过轮询线程去轮询的是就绪队列,大大减少了无效轮询。对于这种方式的本质,还是轮询线程轮询ft,发现就绪后,将内核空间IO数据copy到用户空间。所以一次IO,最少要调用两次IO。
AIO就是真正实现异步IO的,简答粗暴理解AIO就是,用户线程发起IO后立即返回,当IO就绪后,内核会主动将内核空间数据copy到用户空间,所以这个时候用户线程就直接在用户空间读取数据就好了,不需要再次调用IO了。
总结起来:
- BIO:用户线程发起IO后,IO就绪前,内核空间的逻辑会让线程进入阻塞状态。所以如果要实现并发IO,就只能为每个IO都启动一个线程处理。
- NIO:用户线程发起IO后,会直接返回EWOULDBLOCK,而不会让用户线程进入阻塞状态。这个时候用户线程改做什么事情,就是由程序员决定的。可以啥也不干就不断去轮询(这中方式效果比BIO还差)、也可以周期轮询,轮询间隙可以干其他事情(效果也不好其实)。真正发挥NIO的是多路复用。用户态实现的多路复用因为轮询因为涉及用户态、内核态切换,所以效果也不好。要改善这个局面,就只能是操作系统内核来实现多路复用,因为整个IO都是内核控制完成的,所以内核是可以感知IO的状态的。所以对于linux提供了三个多路复用:select、poll、epoll。epoll效率最高,它已经利用了中断信号,通过回调将就绪IO统一管理了,所以epoll的轮询其实就么有无效轮询的。但是epoll有使用限制,即要求必须实现poll。
- AIO:这个是真正实现异步IO。和NIO最大的区别:NIO当io就绪,是坐等用户线程来读取数据的时候才会将数据从内核空间copy到用户空间,然后应用才能真正使用。而AIO是IO就绪会直接将IO数据推送到用户空间,通过回调的方式告诉用户线程。linux目前对api的支持非常有限的,所以现在解决C10K的问题的最主要的方式还是IO多路复用。
- 所以阻塞还是非阻塞指的是IO准备过程(从磁盘/socket读取数据到内核缓冲区)是否挂起阻塞当前线程;同步还是异步指的是从内核空间copy到用户空间的过程。
这里必须的说明一下:只要于速度差异,不阻塞那就是不可能的,快的必须得等慢的,只是说在IO等待过程中,是不是阻塞cpu来等待而已。DMA技术就是用成本小得多、性能小得多大DMA芯片来控制IO过程,阻塞等待的是DMA,不是cpu罢了。(IO和cpu的性能gap是引入DMA,将阻塞等待转嫁到了DMA、cpu和内存的新能gap的处理是咋搞的呢?还是转嫁么?)所以真正一个单核cpu能够支撑成千上百的IO的根本原因,其实是DMA+进程/线程调度:DMA技术使得cpu能够在IO过程中解放出来,而进程/线程计算的出现使得多任务并发成为可能。
BIO、NIO、AIO个人理解这都是IO过程的管理方式,它并不向SSD技术、文件系统技术那样,真正去提升了IO过程的性能。只是通过不同的管理方式,节约cpu的使用。比如从磁盘中一次读取512字节数据要花10ms,BIO、NIO都要花10ms,这个时间BIO、NIO没有任何差别,只是通过IO过程的管理,这10ms内,cpu可以干其他的事情
基本概念的文章很多了,随便贴一篇在这里:
Java后端面试高频问题:BIO、NIO、AIO的区别?_Java烟雨的博客-CSDN博客_aio nio
NIO、BIO的cpu、内存消耗分析
cpu消耗分析
下面从cpu使用率、cpu的负载来分析一下BIO和NIO对cpu消耗的差异。
1. 单线程。即一个IO请求发起后,必须完成后,才能处理第二个IO请求。这个时候线程处于阻塞状态,所以cpu时间片的消耗就是发起IO请求的时候消耗cpu,处于阻塞态后就释放了cpu,所以cpu使用率几乎为0,而cpu的负载为1.
2. 对于每一个IO请求,都创建一个新的线程去处理。而每个线程都发起IO请求后就进入阻塞状态了,所以cpu使用率就是发起IO请求对cpu的消耗,所以使用率也会非常低。但是cpu的laod就会一致飙升。
再来看NIO
nio最朴素的就是使用费阻塞fd,即发起io请求后,不阻塞当前线程,而是立即返回
1. 线程池用户态实现reactor模式的方式,实现多路复用。搞一个dispatcher线程专门处理IO请求,它来负责IO的轮训。所有的IO请求都会先交个他。当IO就绪后然后回调给实际发起IO请求的线程。因为dispatcher线程会不停的轮询,所以这个dispatcher线程cpu的使用率会是100%,并且因为轮询使用了系统调用,会发现有大量的线程上下文切换。而对于cpu的load缺反而不高,就是dispatcher线程一直会是可运行态,即负载会是1
2. 使用linux内核的多路复用。如果使用的是select、poll,相比于用户态的轮询,效率会高很多,因为它也利用了操作系统能够感知IO事件,只有当有IO就绪的时候才会开始轮询,所以大大减少了无效轮询,所以cpu使用率会比用户态实现的轮询小很多,而load也会更小,因为没有IO就绪的时候,轮询线程也是处于阻塞状态的。当使用epoll多路复用的时候,因为进一步减少无效轮询,所以cpu使用率会更小,而load和select、poll没有什么明显的区别。
然后再来看BIO和NIO对cpu消耗的差异,其实就要看怎么使用了。不同的使用方式,结论当然也就不同。而且即使使用了多路复用技术,不同的用法对那么也会有不同的效果的,所以就得具体问题具体分析了。
另外,多路复用技术,并不是NIO技术,多路复用一样可以管理BIO的,而且多路复用管理BIO的时候,同样可以达到非常大的并发的。所以解决C10K问题的关键技术是多路复用技术(C10K问题描述的就是一个物理机的IO并发如何达到1w)
内存消耗分析
如果仅仅是从IO过程上看,其实NIO和BIO内存消耗是差不多的。如果是通过Socket的网络IO,那么接收数据过程都是tcp/ip协议栈将从网络接收到的数据放到读缓冲区(/proc/sys/net/ipv4/tcp_rmen就是配置读缓冲区的大小),当我们调用read()方法的时候,就是从内核的读缓冲区将数据copy到用户空间的空间中。而对于发送数据,write()方法也只是将数据写到写入缓冲区(proc/sys/net/ipv4/tcp_wmen就是配置写缓冲区的大小),然后tcp/ip根据网络情况(网卡带宽、流控、拥塞控制等)不断的从写缓冲区拉取数据,通过网卡发送到网络中。
阻塞和非阻塞的都是这个过程,其主要的区别就是:
- read():缓冲区为空的时候。阻塞IO就会将当前线程挂起,直到读缓冲区有数据,返回数据;而对于非阻塞IO,不会阻塞当前线程,而是会立即返回,并且通过EWOULDBLOCK/EAGAIN错误来告诉当前线程,
- write():当缓冲区没有足够的空间放下本次要写入的数据的时候,对于阻塞IO,就会阻塞当前线程,当缓冲区有一定的空闲空间的时候,会唤醒阻塞在读缓冲区上的线程,然后完成本次所有写入后返货;对于非阻塞IO,如果写缓冲区满了,直接返回并且通过EWOULDBLOCK/EAGAIN错误来告诉当前线程,如果写缓冲区没满但是放不下本次写入的数据,那么就是能写下多少就写入多少,然后write()函数返回值就是本次写入的字节数
ps:对于阻塞IO,write()要么出错不写入、要么就是都写入,所以返回的写入字节数和入参里的应该是一样的,返回写入的字节数的意义并不大。但是对于非阻塞IO的部分写入,那么返回本次写入的字节数就很有必要了。
所以,BIO和NIO在内存消耗上,其实没有什么明显的区别。但是直接内存映射技术,一般也会算成是NIO的技术,如果使用直接内存映射,那么用户空间就是直接去读取的内核空间。就少了一次内核空间到用户空间的copy,对于这种情况,NIO使用的内存会几乎减少一半。
ps:如上分析,是基于个人当前对IO、以及操作系统cpu管理、内存管理的认识分析。摸着良心说,本人对操作系统的认识、对IO的认识并不是那么的深刻。理解分析难免有偏差。希望看到这篇文章的大佬,发现有什么问题,不吝赐教,说不定随着认识的深入,分析也就更加深入一些了。
自我总结
我们在讨论一个问题的时候,首先是大家对问题本身一定要一个一致的认识,否则整个讨论过程中表面看大家对这个问题讨论的非常激烈,实际上,全都在讨论问题的题面,说白了就是还没有真正开始讨论到问题的本质已经开始面红耳赤了。我觉得这就是学习八股文的最大的意义。个人觉得在讨论BIO和NIO谁使用的cpu多、谁使用的内存多的时候,多多少少就有点陷入到这个局面了,回头想想,最大的gap可能就是在于我们对基本概念的理解上出现了一点偏差,且更多的是我们各自都有一些假设没有摆在明面上来聊,所以我说什么他都可以发现这个说法有问题。当然,当时更多的是有我的问题,我在聊的过程中,将AIO的一些特性搅在一起了,加深了理解gap。
另外一个真实发生的场景,对于一个sql:update a=a+1,众兄弟激烈的讨论了一下午,又是事务、又是隔离级别、又是幻读、又是不可重复度、又是锁,db的的概念基本都抛了一遍。讨论的核心点居然是在应用层要不要用显示的事务来控制,保证a=a+1计算的时候,读出来的a不会应为并发有问题,导致计算结果有问题。但凡大家对mysql的事务有个一致的认识,也不至于讨论得如此激烈。















 204
204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









