







本人知乎地址:https://zhuanlan.zhihu.com/p/83382019
paper:Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
https://arxiv.org/pdf/1803.02349.pdf
花了一周时间,零零碎碎终于把阿里这篇文章研究了一下,也看了很多知乎大佬的讨论,整理总结如下,如果有哪里说得不妥当或有问题,烦请指出讨论,深表感谢。
主要参考:https://zhuanlan.zhihu.com/p/70198918
目前有以下几个小问题,列在前面。
1. 有向图 vs. 无向图?
deepwalk使用无向图,而node2vec适用于无向图和有向图。在实际应用时,n2v也是基于deepWalk产生
序列训练集,那么有向图的用法体现在哪里了?
2. 如何训练?
BGE是把item的one hot形式输入w2v模型,而EBGE是item 和 side infor的 one hot输入得到embedding取平均后得到了一个稠密向量,而w2v不是要求输入是一个one hot 形式么…
——自己理解: 得到稠密向量后并不是直接输入w2v,是把item 和n个side infor的n+1个OHE分别输入到n+1个embedding_lookup层,得到embedding,取平均后得到d维稠密向量H,输入分层softmax训练。
经典回顾
DeepWalk(2014)、LINE(2015)、node2vec(2016)
原paper中对deepwalk的描述就不写了,网上资料非常多,这里就贴个图,很容易。
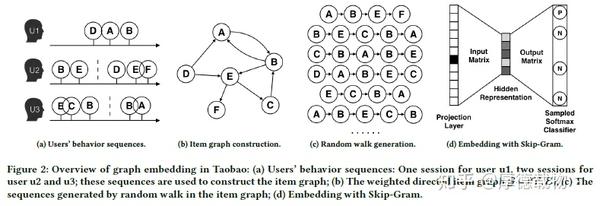

这部分主要摘录知乎的公开分享,Graph Embedding在知乎的应用实践。
- DeepWalk:总体分为两个步骤,首先通过随机游走得到节点序列,然后使用word2vec进行训练。
- LINE: 设计了新的边采样方法和损失函数。首先采样图中的边,然后使用每一个边对模型参数进行更新。
- node2vec:基于DeepWalk,只是设计了灵活的随机游走策略(DFS和BFS结合)。
各方面对比:
- 适用范围:DeepWalk只适用无向、无权重的图;LINE和node2vec适用任意类型的图。
- 模型效果:按照论文的说法,三个模型呈递进关系。
- 网络规模:DeepWalk(百万的点和百万的边);LINE(百万的点和十亿的边);node2vec(百万的点,每个点平均出度为10,它使用的数据集比较小)。
这里存疑,并不知道网络规模是哪里得到的,在公司我们使用n2v也是在一个小场景使用,一两百万的node,20轮游走,七八个小时 训练,效果还不错,查看case基本都挺令人满意,不知道有没有朋友在大场景用过,训练速度怎么样?
EGES ——2018 阿里 千亿级别GE实践
个人总结
文章主要是为了解决在图里面表征冷启动item的问题。
几个值得注意的地方有三点:
1、 每个item的side infor的权重是不同的,并且是训练得到。
2、 冷启动商品用side infor的embedding取平均作为embedding vector。
3、 假设item 有1000W,3个side infor的OHE维度分别为10,100,1000,那么模型输入的第一层稀疏向量的维度就是1000W+1110维,然后得到4个d维embedding,之后取平均得到d维item embedding H。
如何利用用户的行为构建item graph
设置时间窗口切分用户行为(session-based users’ behaviors),短时间内访问的商品更具相关性。 经验设置1小时,
item1 和 item2是两个连续的行为,那么用边相连,权重是这两个商品邻接出现的次数。
需要过滤异常和噪声数据:
- 去掉点击后停留时间少于1s的
- 过滤过度活跃的用户(三个月内购买了1000件商品,点击量超过3500次)
- 商户会对商品各项内容进行更新,更新一定次数之后应该被认为是一个新的商品。
Base GE (BGE)
基于deepWalk在加权的item graph上学习每个node item的embedding。
根据用户行为,构建以商品为node的图,然后通过random walk生成商品的序列,再利用skip-gram算法,生成商品的表示向量。
Enhance BGE (GES)
BGE无法较好的学到冷启动物品的embedding。
把那些常在ranking阶段用到的side information(也可以叫做泛化属性)用在matching阶段,如类别,店铺,价格等核心参数。
核心假设:具有这些side infor的商品,在embedding空间上should be closer.
item的embedding维度和side infor的embedding维度设置为相同经验数值。
下图是GES和EGES的通用框架,SI表示side infor,而 SI 0 表示itemid,文中用了n个 side infor,每个SI都是OHE输入,故而总共n+1个item feature field(借用FFM中的说法)。
刚开始看这个图总是迷惑item id 去哪了,原来是文章没看仔细…


个人理解就是在BGE的基础上,加上了side infor这几个OHE特征,每个item feature field(文中就是每个维度为d的W向量)得到d维的embedding vector,共n+1个 (在上图中应该是第一层的稀疏特征和第二层的稠密embedding之间的embedding操作,TF中就是一个embedding_table API)。将这n+1个特征embedding直接concat起来也就是第二层,做一个类似average-pooling layer的操作,取平均(公式6,),聚合得到该item的d维embedding vector H_v(每个特征的边权重a_i = 1),也就是文中的公式(6)。


这样,具有相似side infor的商品,他们的embedding 就会很相似。
对于冷启动的商品,没有Item id 怎么办?—— 直接将这些泛化属性的embedding取平均作为cold item的embedding。(原文3.3.2)


得到的该item 的 embedding H_v ,输入一个采样(负采样)的softmax训练即可。
Enhanced Graph Embedding with Side Information (EGES)
GES假设side infor对item的贡献是相同的,直接取平均太粗糙。注意这个泛化特征的权重不是设定死的,是模型学习得到的,不同商品的同个特征的权重可能是不同的,用a来表示这个权重。
为了保证所有边信息的权重大于0,对权重取e的指数。
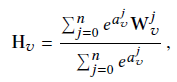

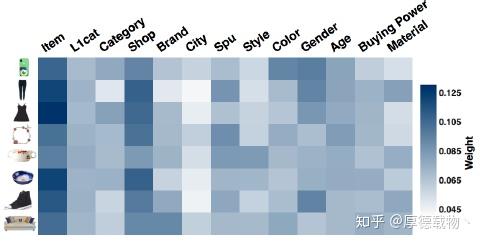
取的8个不同的商品,在各个边信息上的权重的分布。可以看到,对每个商品,不同的边信息有不同的权重。最重要的还是item本身的向量,次重要的是shop这个边信息。

算法步骤和圈中更新EGES的伪代码写的很清楚


SEQ: 对每个节点RandomWalk走l步的序列。
在加权的skipGram训练步骤:


对一个序列SEQ中的每个item v = SEQ[i],遍历v的窗口内的上下文,例如item u = SEQ[j],更新(update(v,u,1))上下文u(label = 1)的embedding,以及input v的每个side infor的权重a_v和embedding。
之后,对负采样的ns个item,例如 u,更新(update(v,u,0)),再次更新了input v的item embedding以及side infor 的embedding和权重a_v。
好了,又整理出来一篇,关于第一个问题我一直没想明白,还请各位不吝赐教!感谢。














 321
321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









