







之前看过的一本《pratical recommender systems》的读书笔记,这本书讲了很多网上看不到的,很实际的工程方面的考虑,规则为主,算法为辅。现在网上铺天盖地都是高大上的排序模型,这些都是大公司打出知名度的东西,实际中有几个用到的?推荐成立之初就是规则,现在的算法工程师大多都太飘了,满口的算法模型,各种模型架构的优化,忘记了最初对业务规则的理解,脚踏实地,一直是老板对我说过的最多的话。个人理解,不喜勿喷。
回顾正题,这一章主要讲了如何衡量用户对商品的喜好程度,类似item-cf,ALS,MF这类算法,大多都是要构建这种数据集的,这篇文章讲得很好,作为第一篇整理出来。
推荐系统中最常见的数据就是user-item-rating的打分数据。这里的rating可以是像豆瓣那样的显示反馈(用户手打的分数),也可以是隐式反馈,即根据用户历史行为定义的分数(淘宝的点击收藏加购行为),后者更为常见。
书中的例子定义了三种行为事件event,点击details,点击more details,购买。并且为每种行为定义一个权重,即反映用户对商品的感兴趣程度。
如果将用户购买当做最终的目标,那么隐式反馈的打分函数可以定义如下:

当然,并不是所有的权重都是正的。如果一个行为在有转化的session中发生的次数多于没有转化的session, 那么就可以给一个正的权重。 点击“不喜欢”的按钮,这类权重就是负的,而且权重可以很大。
考虑几个case:
- 是否要设置上限?当一个行为发生超过一定的次数,那他还应该加上同样的权重么?比如,看了五次和看了十次的喜好程度会差一倍么?当然不会。所以要对每个行为加上一个cut-off,公式中的#event变为min(#eventn,relevant_maxn)
- 当用户看了很多次但还没有转化(导致购买),假如浏览一次的权重是1分,购买是10分,那么看了10次但是没买,那么能说明这个商品和发生购买的商品喜好程度一样么?文中没有详细说明解决办法,在个人实践中,是将商品是否转化打上标签,最后把发生转化的商品总分乘上一个较小的权重,整体提高分数。
- 过去的行为和最近的行为对当前的兴趣点反映的程度一样么?很容易理解,要引入时间衰减机制。这也是实际中用的最多的技巧。书中使用一个简单的分数对每个event做时间衰减,这个式子对每一天的衰减水平都是一样的。实际中,大多是用指数衰减来做的,越远的行为衰减的越快,即对原始的分乘上一个指数系数:
exp(-α * days)
其中α是冷却因子,越大y的值变化就越明显;days则是想要衰减的天数。
4、大多数人都会买香蕉,很少人会买榴莲,那么一个人买了榴莲和一个人买了香蕉,哪个更能表现这个人对这个item的喜好?很显然,小众的需求包含更多的信息,这和信息论不谋而合。文中推荐的做法是,可以在计算的商品得分基础上加一个filter,提高那些比较特别的item得分。可以通过类似“term frequency–inverse document frequency(TF-IDF)”方法来找到哪些item是比较special的。如果相同的用户喜欢某些小众的item,那么这个item更能体现用户的个人品味。
TF-IDF很好理解,这是一种统计方法,主要思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来做文章的标签,区分不同文章。相似的,定义IUF(inverse user frequency):
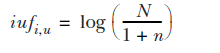
其中n是所有买过item i的用户数,N是所有的用户数。为什么用log函数呢?因为log函数能够放大变量较小的区域,变量值越大,增长的越缓慢。
放书中的两张图,上图是log函数图像,下图是IUF的图像:
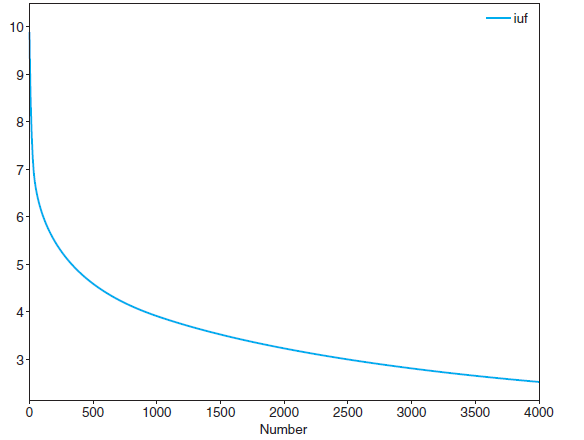
自然的,很少人买了这个item,那么对商品得分的加权会很高,反之很少。
最终的隐式反馈打分的形式为:
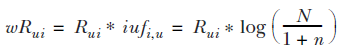
本书这一章到这里就结尾了,但还有很多实际的case以及可以优化的地方没有讲到。很显然,这里没有对人做个性化的处理,如果我这个人非常偏执,一个东西最少就要浏览5次,这5次相当于别人的2次,那我对商品的打分就明显高于其他人,这时就要考虑做人的归一化。欢迎补充不同的case,以及实际当中的trick。
当然了,最能提高算法性能的并不是说你把所有的case都考虑到,而是一定要做好数据的清洗和训练数据的定义,这才是提高算法性能的王道,本人是深有体会,写了一个超复杂的打分策略,结果没有把原始数据清理好,人家一个简单的策略就把我完爆…














 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









