









 本文详细介绍了StableDiffusion模型的结构、存储位置、加载方法,以及模型下载渠道,重点提及了HuggingFace和Civitai平台。文章还讨论了模型的分类,如二次元、写实和2.5D风格,以及如何通过平台找到并使用合适的模型。
本文详细介绍了StableDiffusion模型的结构、存储位置、加载方法,以及模型下载渠道,重点提及了HuggingFace和Civitai平台。文章还讨论了模型的分类,如二次元、写实和2.5D风格,以及如何通过平台找到并使用合适的模型。
目录
1 模型简介
拿图片给模型训练的这个过程,通常被叫做“喂图”。模型学习的内容不仅包括对具体事物的形象描绘,还包括对它们的呈现方式(画风)。如果我们喂给模型的图片都是二次元风格的,那你让它画人画风景,它都会画得像一幅二次元插画;如果喂的图片都是真实世界里的照片,那它生成的图片就是偏真实场景的。
使用不同风格的模型,就能生成不同风格的作品。
2 模型文件构成和加载位置
2.1 存储位置
在Stable Diffusion里,模型被存储在./models/Stable-diffusion/文件夹里,如果下载了新的模型文件,需要复制到该文件下,SD就可以自动加载该模型。模型有固定的称呼,叫做checkpoint,即检查点或者关键点模型,可以理解为游戏中的存档,模型训练到某个关键位置时,就会建立一个关键点来保持已经训练的部分,以后方便回滚和继续训练。
模型通常很大,一般占用37GB,文件名后缀通常是`.ckpt`,我们常把这种GB级别的模型叫做“大模型”。还有一种大模型的后缀是`.safetensors`,占用空间会小一点,通常12GB。SD里这两种模型都可以使用。
2.2 加载模型
如果是在WebUI打开的状态下添加了新模型,需要先点击左上角右边那个刷新按钮,新的模型才能被显示进来,再选择对应的模型即可。
需要看命令行里的加载进度,跳出这样的提示才算加载成功:
Reusing loaded model v1-5-pruned.ckpt [e1441589a6] to load v1-5-pruned-emaonly.ckpt [cc6cb27103]
Loading weights [cc6cb27103] from D:\Projects\stable-diffusion-webui\models\Stable-diffusion\v1-5-pruned-emaonly.ckpt
Applying attention optimization: Doggettx… done.
Weights loaded in 4.6s (send model to cpu: 0.8s, load weights from disk: 2.8s, apply weights to model: 0.3s, move model to device: 0.6s).
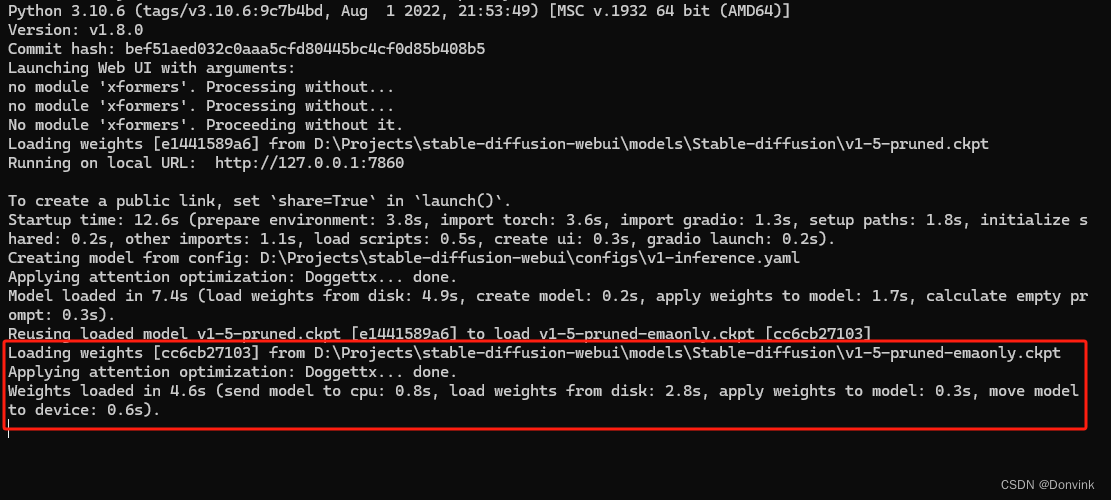
模型加载成功后才能开始生图。
有的UI页面在模型选择栏右边有个VAE的选项,全称叫做变分自编码器,负责将加噪后的数据转换成正常的图像。可以粗略理解成AI作画的一种“调色滤镜”,最直观地影响画面的色彩质感。目前大部分新的模型已经把VAE整合进大模型文件里了,少数会没有整合的会推荐使用特定的VAE,使得生成的图片质感更好。VAE文件的放置路径是同models文件下的VAE文件夹里./models/VAE/。可以将VAE模型的文件名修改成和对应大模型一样的名字,再在VAE选项里选择“自动”,这样就可以针对不同模型自动切换VAE。我们使用的UI没有VAE选项,故不做展开介绍。
3 模型下载渠道
市面上大多数SD使用者用来作图的模型,都是由个人训练并发布的,俗称“私炉模型”。大家会把训练AI学习图片生成模型这件事叫做“炼丹”,炼丹有一定的技术门槛和硬件需求,因此只有拥有一口好的“炼丹炉”才能成为炼丹师。由于版权问题,官方的炉在学习的素材来源和尺度上都有着比较大的约束,所以利用私炉作画出图时目前的主流趋势,但它的版权确实会存在争议。
目前AI绘画主流的模型下载网站有两个:Huggingface和Civitai。
3.1 HuggingFace
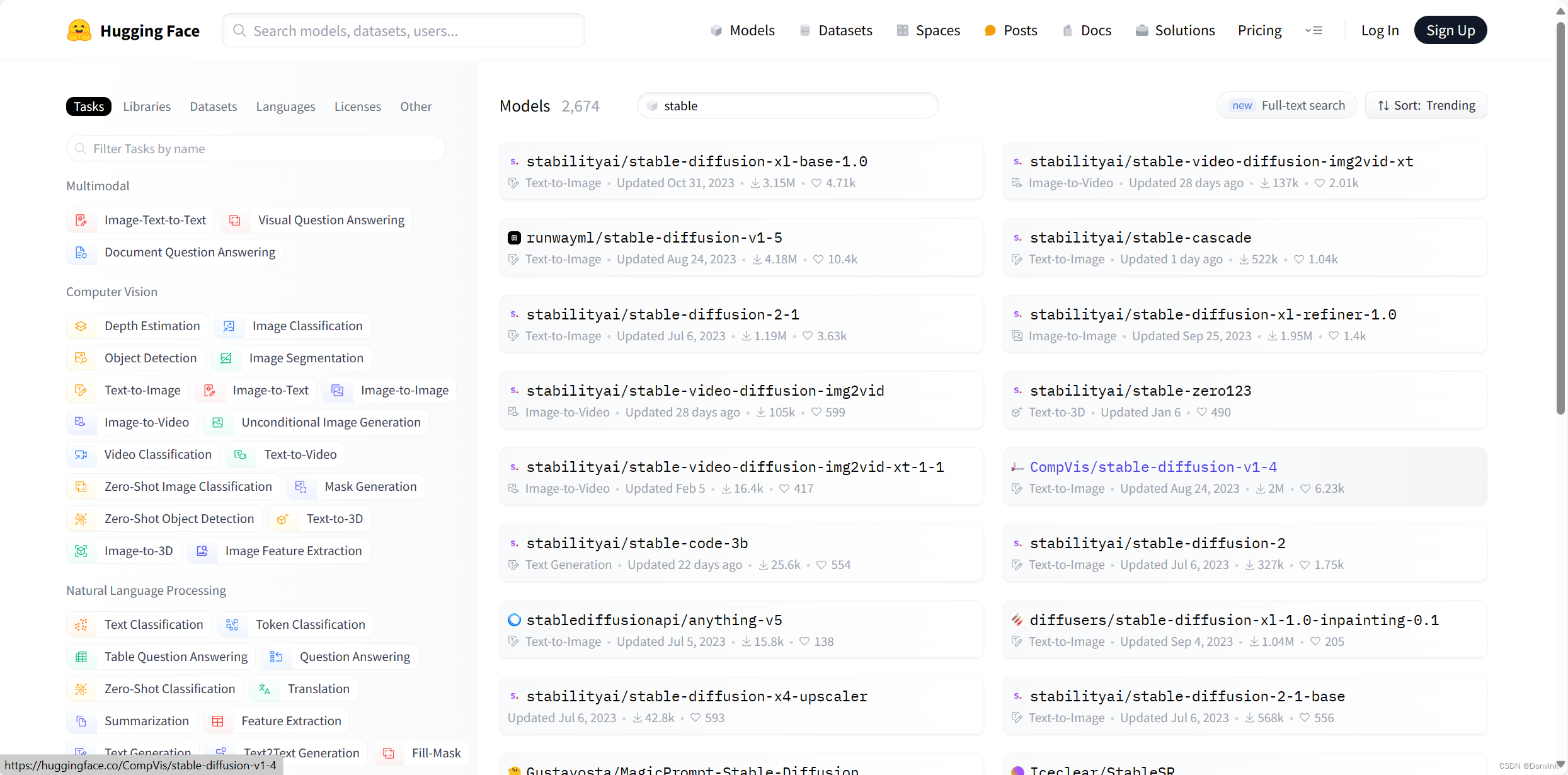
HuggingFace,俗称抱脸。它是一个允许用户共享AI学习模型和数据集的平台,包含的内容非常广:AI绘画和其他AI领域的内容。
-
在最上方的搜索栏里输入
Stable Diffusion,可以直接下载发布的历代官方模型。
-
在左边的工具栏里,点亮
Text-to-Image标签,就能筛选出其他用户发布的主要被用于AI作画的问生图模型了,包括许多老牌知名模型:WaifuDiffusion、Anything、DreamShaper等。
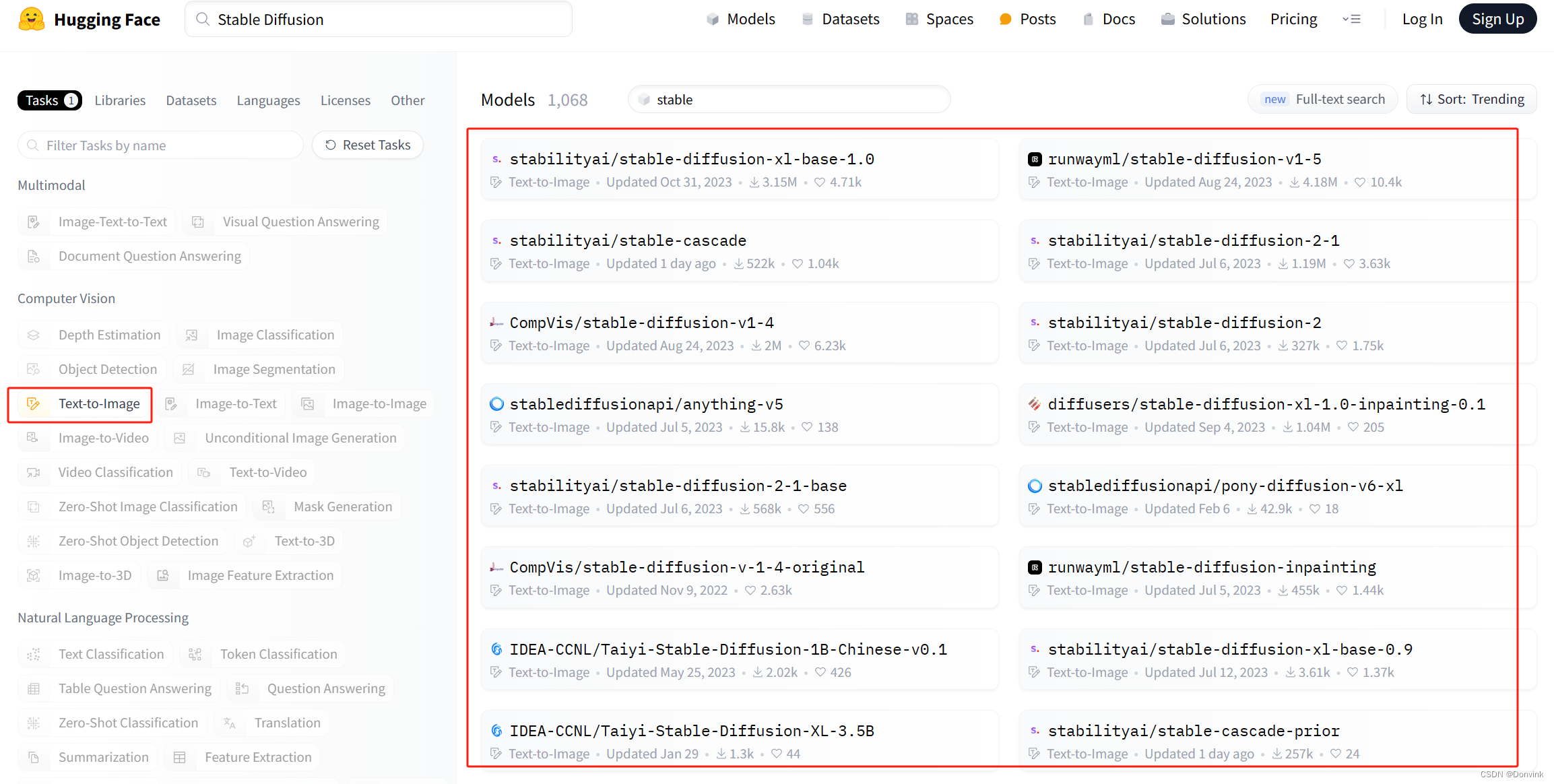
-
选择其中一个点进去,会有一个“Model Card”,相当于这个模型的介绍页面;
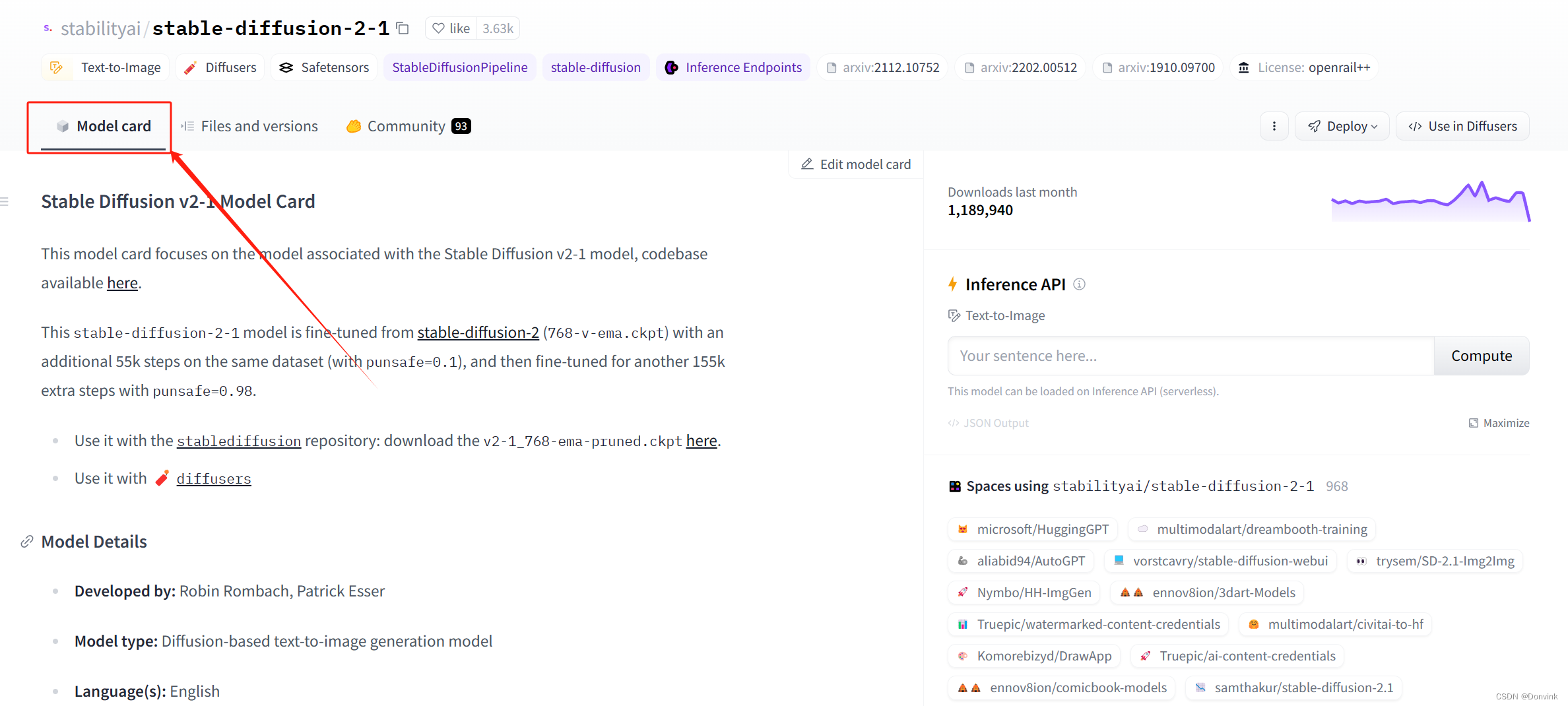
-
切换到第二个标签“Files and versions”,制作者们会把文件、源代码等文件放到不同的文件夹里。
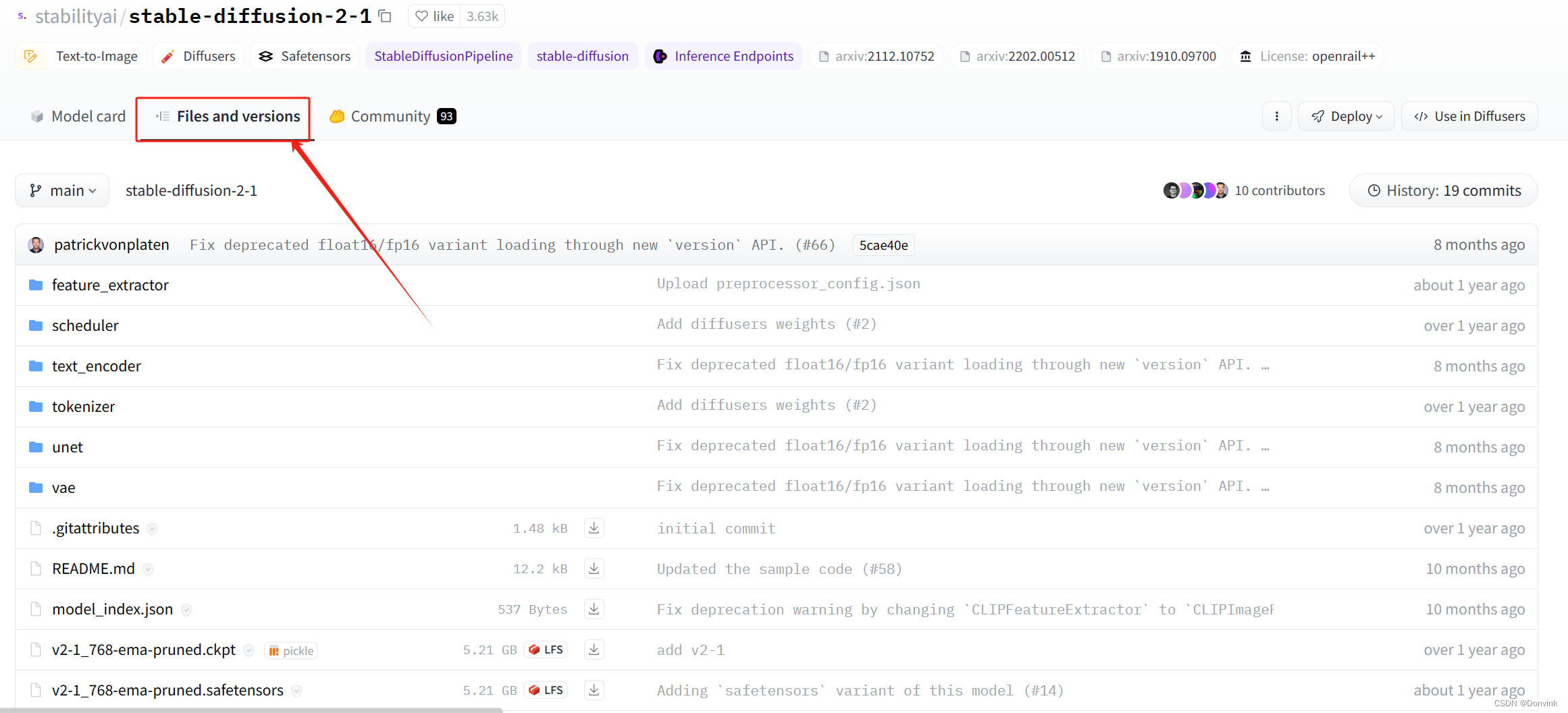
-
到对应的文件夹里寻找需要的文件,点击就可以下载。
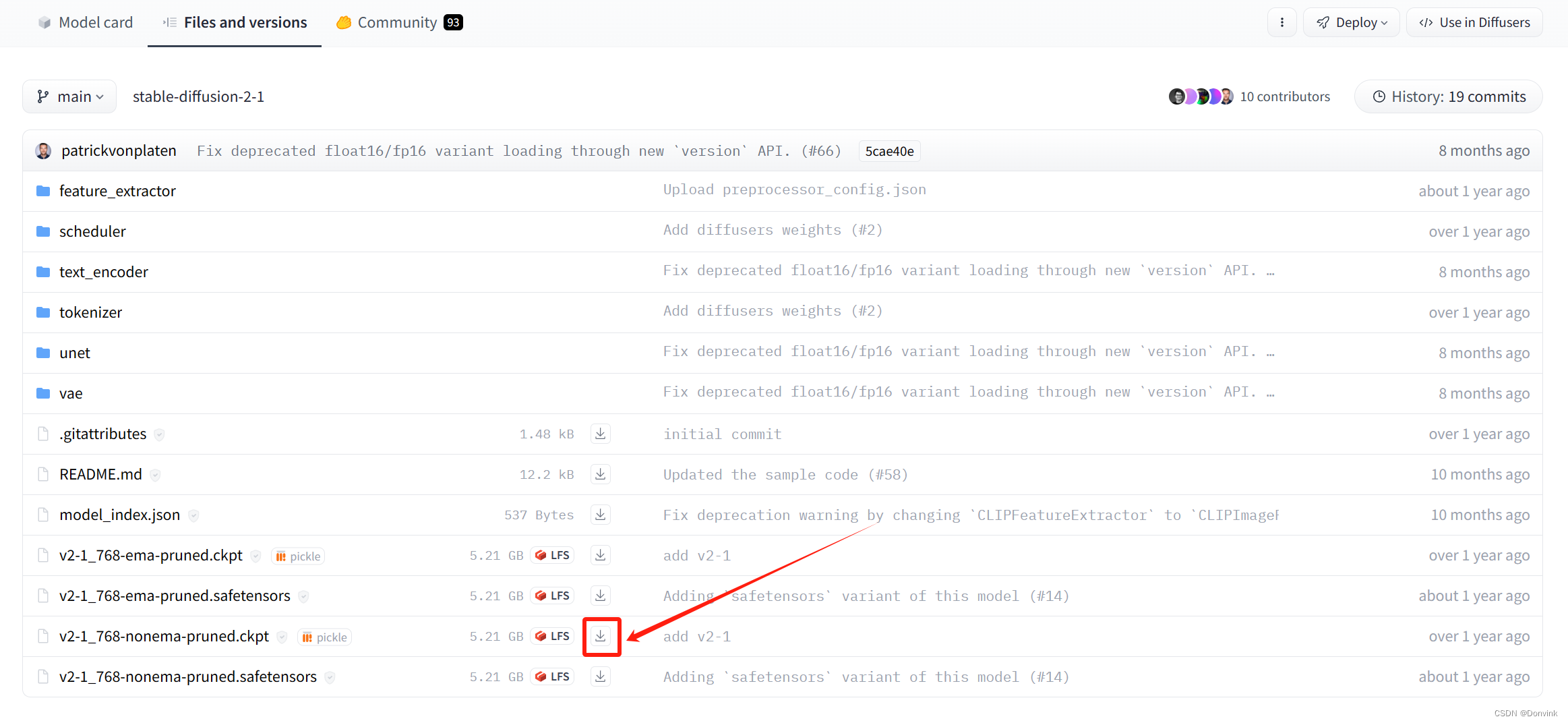
-
切换到“Community”,可以进入对这个模型感兴趣的使用者们的交流区,如果有什么建议,或者遇到什么bug,可以到交流区里看看是否有解决方式,或者点击左边的
PR & discussions documentation发起讨论。
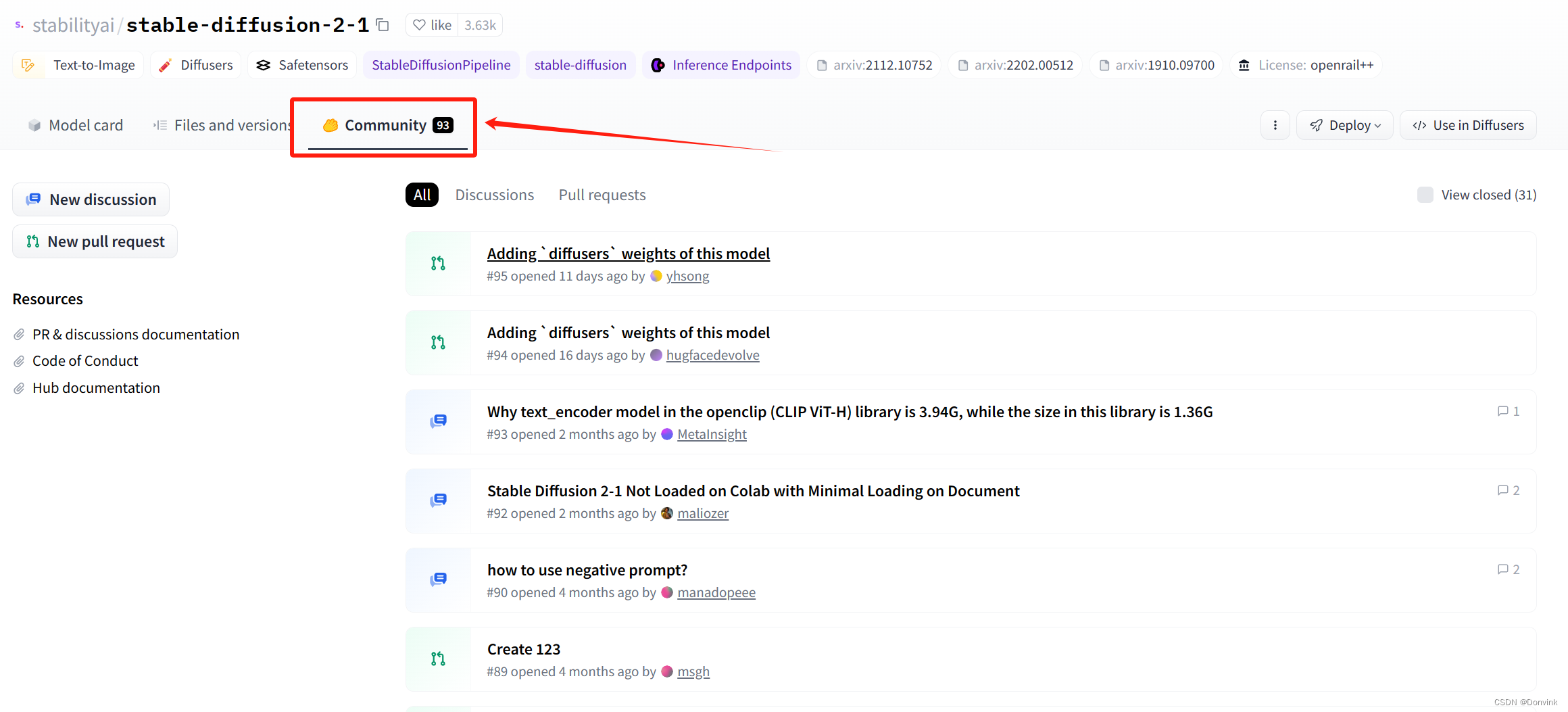
市面上一些知名的模型,都可以来Huggingface搜一下看看。
3.2 Civitai
Civitai,俗称C站,是一个AI绘画模型的分享平台,里面各种模型的展示是非常图像化和具体化的。在C站上访问和下载模型均不需要注册。
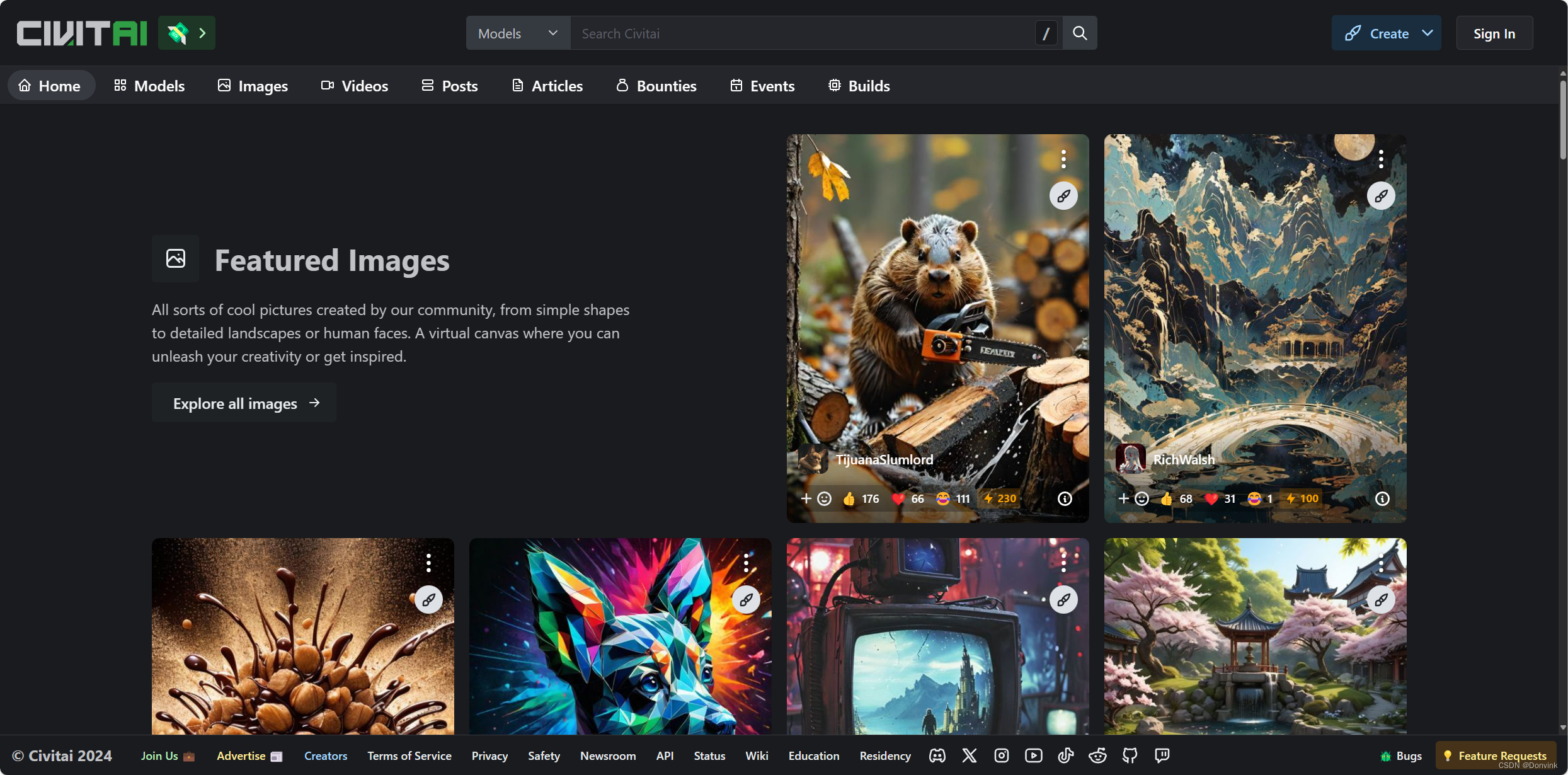
- 点击“Models”进入模型页面,点击右上方模型排序选项,选择“Highest Rate”或者“Most Downloaded”,就可以看到目前最火热的一系列AI绘画模型了。
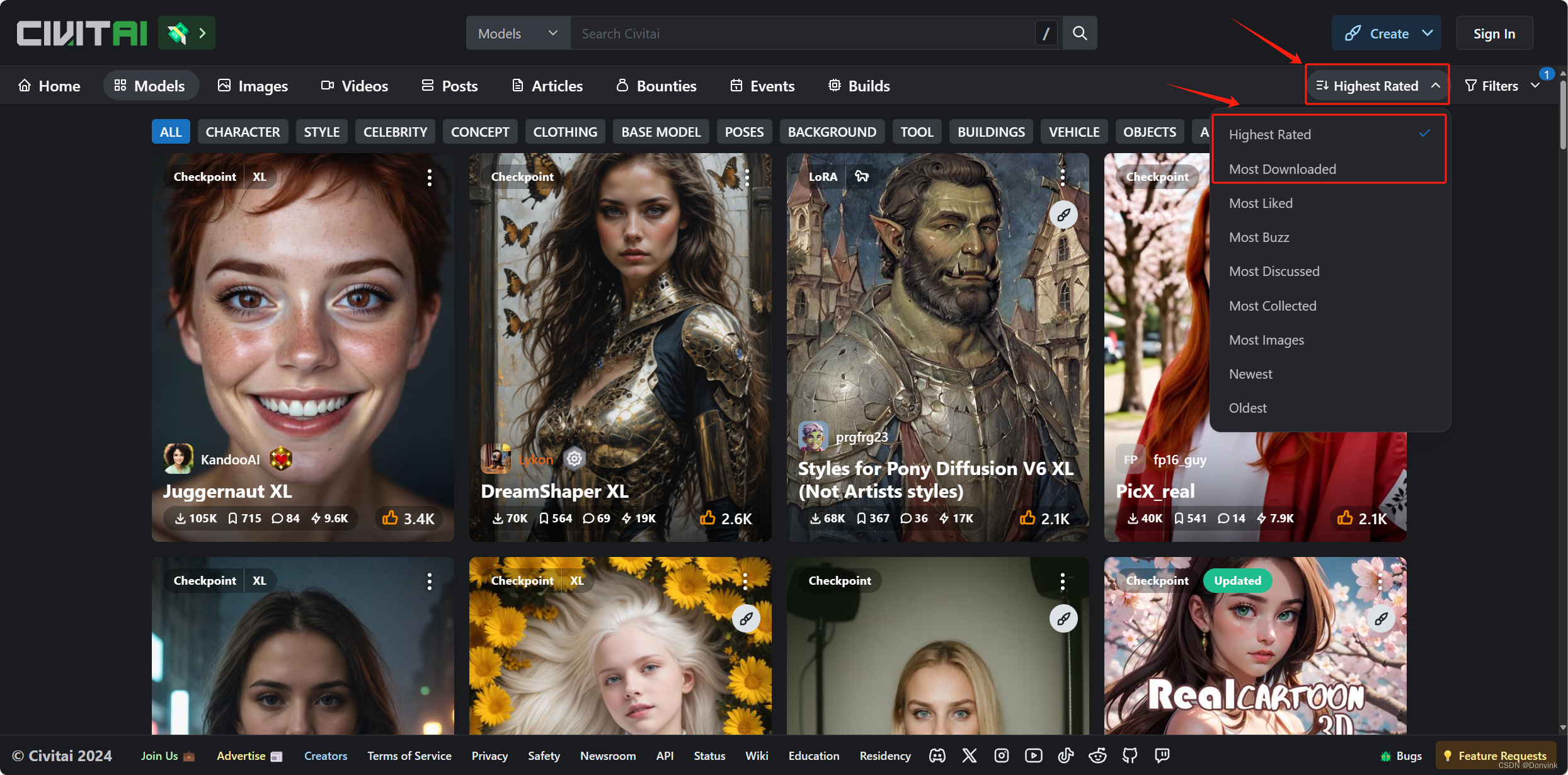
- 可以对这些模型进一步细分筛选:
– 基于模型类型,点击右上角小漏斗按钮,可以根据不同选项对模型进行筛选。
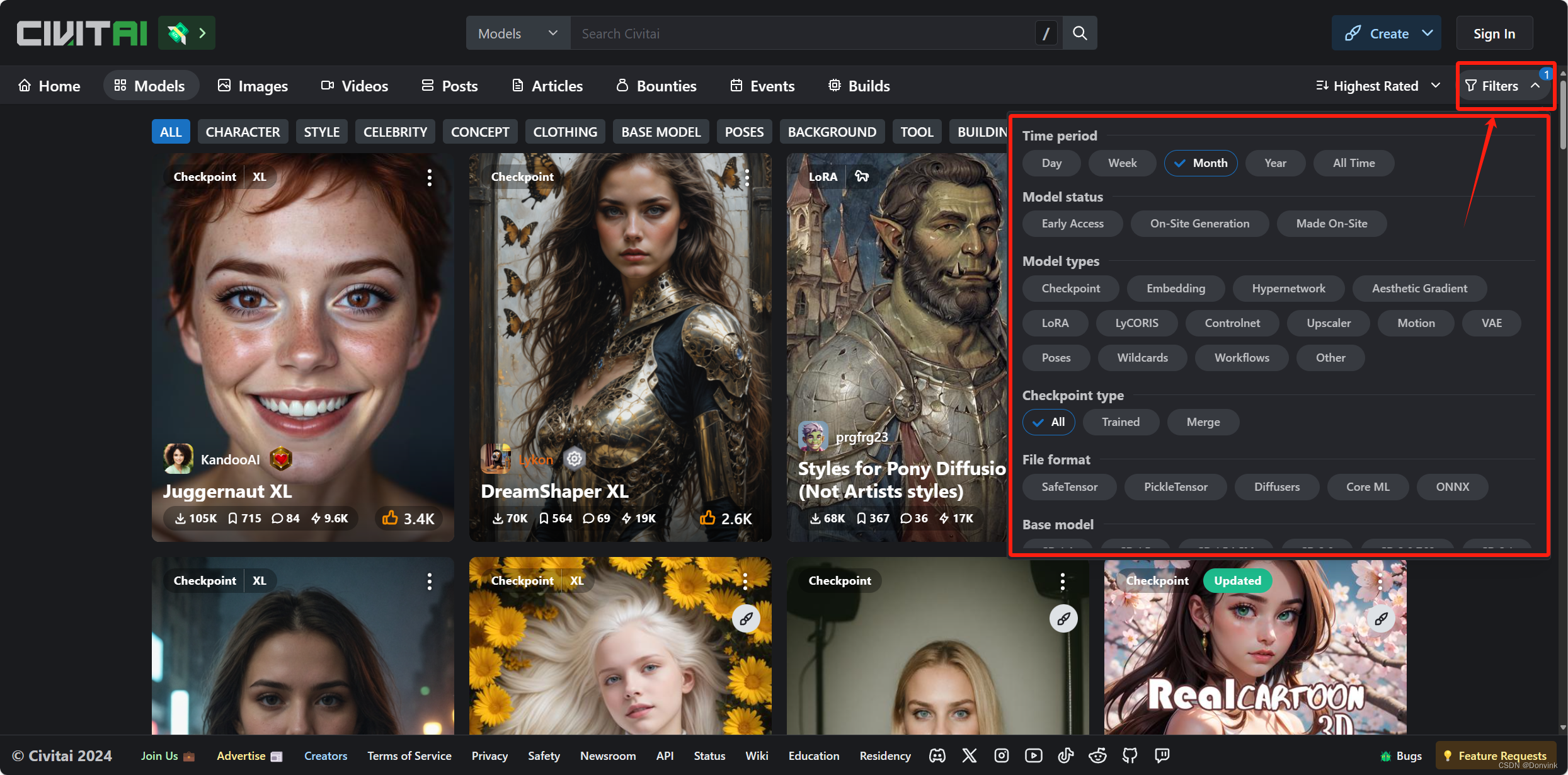
– 基于特定内容类型,页面上方有一系列标签,代表着不同的风格类目和内容方向,例如:动画、角色设计、女性、名人、插画、卡通、男性、自然景观等。
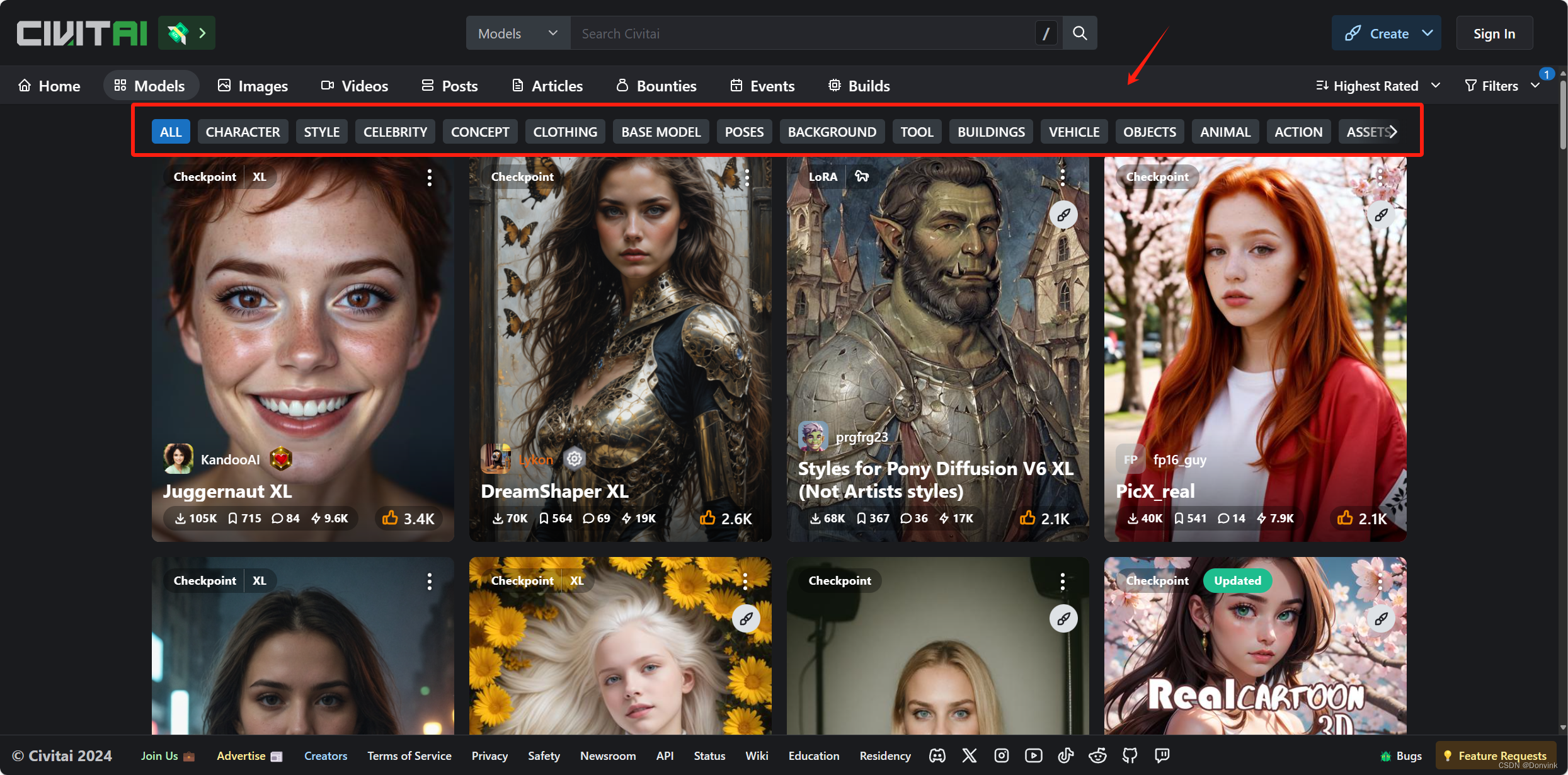
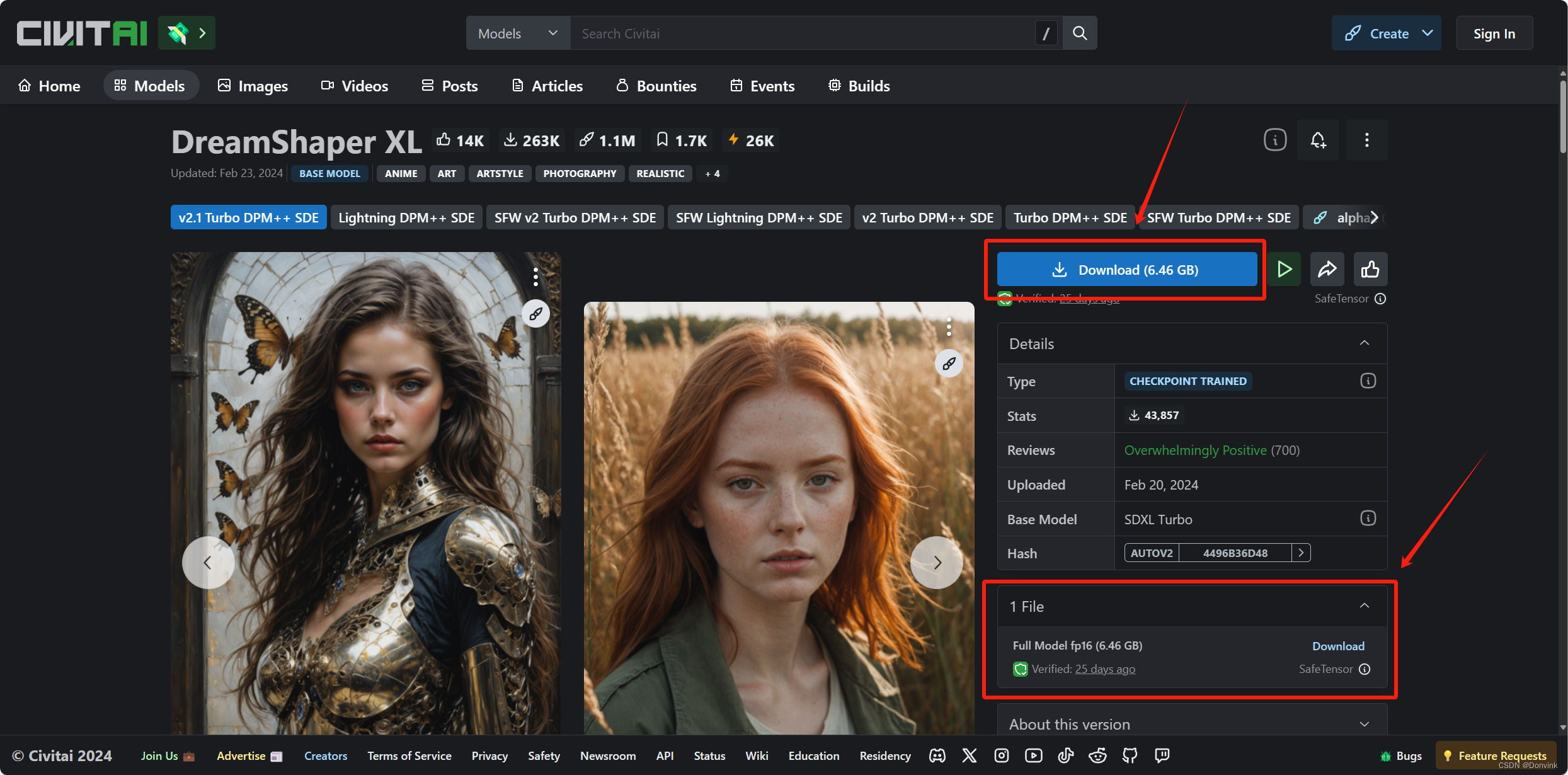
- 选择其中一个模组,进入后右边是下载按钮,如果有不同的版本,可以到下面的Files选择下载哪个。页面底下的模组介绍,相当于Huggingface里的Model Card,最好在作图前仔细阅读一遍,作者会从很多方面指导你如何使用该模型,例如:适合的风格、关键词、分辨率以及VAE,点击其中的链接都可以直接跳转下载。
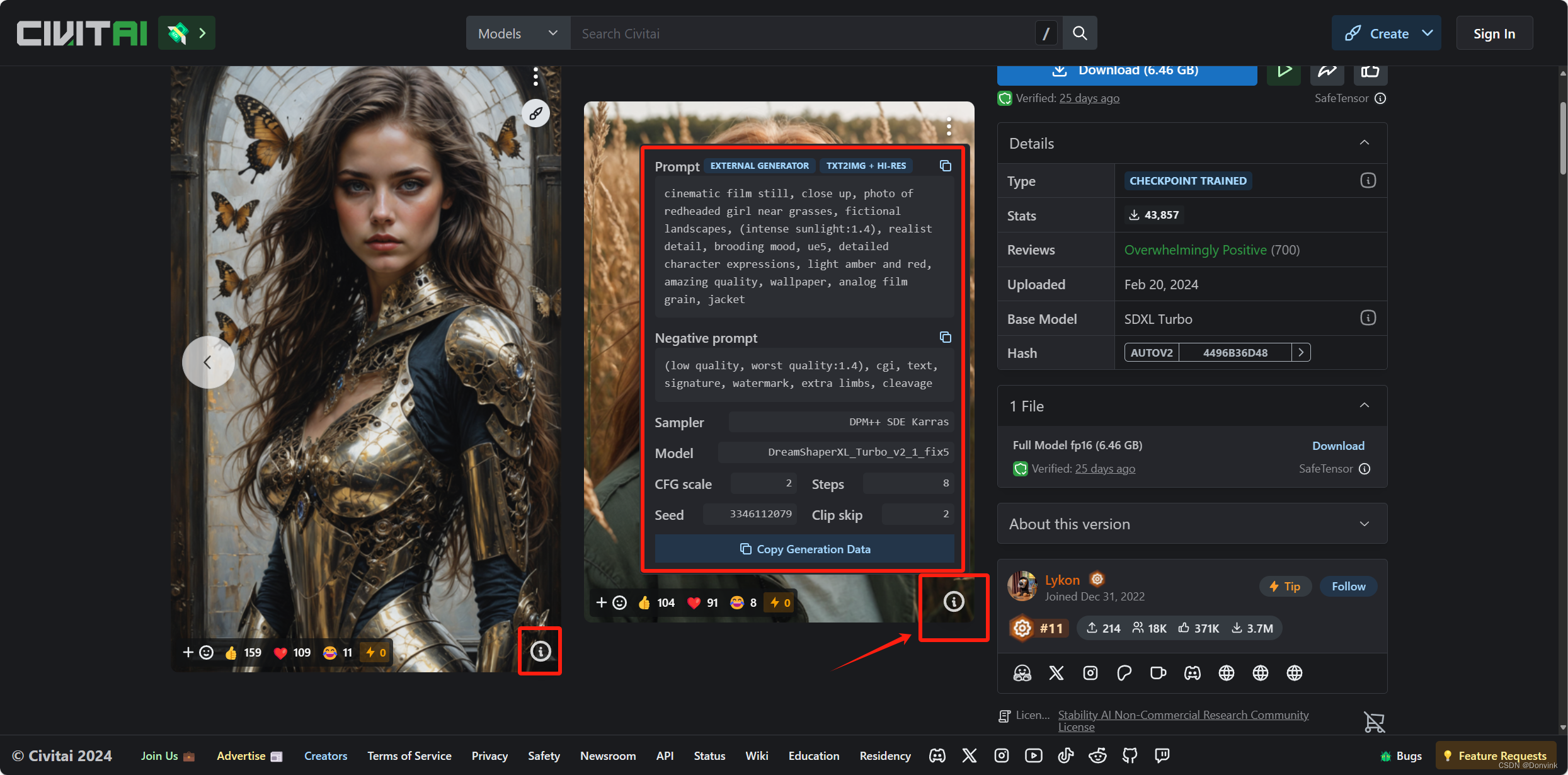
- C站作为模型分享网站,不仅仅分享模型,还分享用这些模型做出来的作品。模型页面的正上方,都有一系列作者使用这个模型生成的例图,点击图片右下方的信息按钮,就会跳出对应的提示词、采样方法、随机种子等等详细的参数。如果你要抄作业,那这就是一份参考答案,可以给你产出最接近模型作者理想中的效果。
-
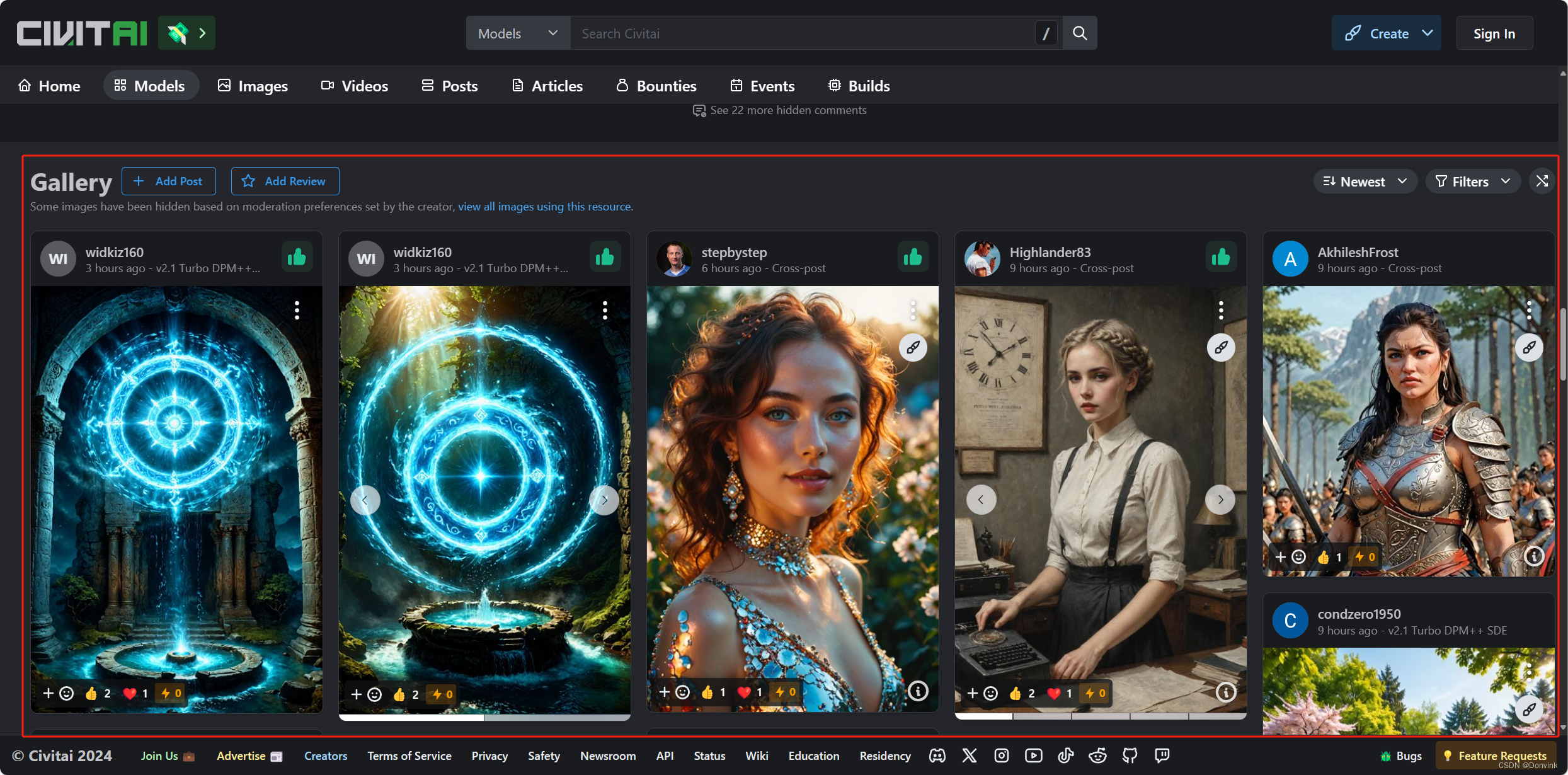
再往下翻,可以看到C站上其他用户上传的基于这个模型产出的图片,里面大部分都会同样附上提示词和参数。
-
C站的首页还有一系列页面,例如:“Image”页面,点进去,可以欣赏到那些高赞好评的AI绘画作品,并找到它们对应的使用模型和提示词、参数。其他的页面也是一些高赞的作品。
4 模型分类
下面介绍几种不同类型模型对应的代表模型和搜索关键词,也可以使用这些搜索关键词在Prompt中激活模型风格特性。
4.1 二次元模型
偏漫画、插画风格的,具有鲜明的绘画笔触质感,代表作:Anything、Counterfeit、Dreamlike Diffusion等。
搜索标签与风格关键词:illustration, painting, sketch, drawing, comic, anime, cartoon.
4.2 写实模型
偏真实系、拟真化程度高的、对现实世界还原强,代表作:Deliberate、Realistic Vision、LOFI等。
搜索标签与风格关键词:photography, photo, realistic, photorealistic, RAW photo.
4.3 2.5D模型
介于二次元和写实模型之间,还原出来的质感效果类似于一些建模软件里能制作出来的三维渲染图,接近目前一些游戏和3D动画的风格,代表作:NeverEnding Dream、Protogen、国风V3等。
搜索标签与风格关键词:3D, render, chibi, digital art, concept art, {realistic}.

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









