









逻辑回归(LR)是一个分类算法,它可以处理二元分类问题和多元分类问题。在介绍LR之前,先回顾一下线性回归(Liner Regression)。
一、线性回归
线性回归是一个回归模型,给定数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } D = \{ ({x_1},{y_1}),({x_2},{y_2}),...,({x_m},{y_m})\} D={(x1,y1),(x2,y2),...,(xm,ym)},包含 m 个样本,线性回归的假设函数为:
h θ ( x ) = θ 0 x 0 + θ 1 x 1 + . . . + θ n x n {h_\theta }(x) = {\theta _0}{x_0} + {\theta _1}{x_1} + ... + {\theta _n}{x_n} hθ(x)=θ0x0+θ1x1+...+θnxn
损失函数为:
J ( θ ) = 1 2 m ∑ i = 1 m [ h θ ( x ( i ) ) − y ( i ) ] 2 J(\theta ) = \frac{1}{{2m}}\sum\limits_{i = 1}^m {{{[{h_\theta }({x^{(i)}}) - {y^{(i)}}]}^2}} J(θ)=2m1i=1∑m[hθ(x(i))−y(i)]2
带有 L2 正则化的损失函数为:
J ( θ ) = 1 2 m { ∑ i = 1 m [ h θ ( x ( i ) ) − y ( i ) ] 2 + λ ∑ j = 1 n θ j 2 } J(\theta ) = \frac{1}{{2m}}\{ \sum\limits_{i = 1}^m {{{[{h_\theta }({x^{(i)}}) - {y^{(i)}}]}^2}} + \lambda \sum\limits_{j = 1}^n {{\theta _j}^2} \} J(θ)=2m1{i=1∑m[hθ(x(i))−y(i)]2+λj=1∑nθj2}
线性回归的求解可以使用梯度下降法,也可以使用最小二乘法,以下是使用梯度下降法求解的步骤:
(1)初始化参数
λ
\lambda
λ,
ε
\varepsilon
ε
(2)确定当前位置损失函数的梯度,对于
θ
i
{\theta _i}
θi,其梯度为:
∂
∂
θ
i
J
(
θ
0
,
θ
1
,
.
.
.
,
θ
n
)
\frac{\partial }{{\partial {\theta _i}}}J({\theta _0},{\theta _1},...,{\theta _n})
∂θi∂J(θ0,θ1,...,θn)
(3)用步长
λ
\lambda
λ 乘以梯度,得到下降的距离,即:
λ
∂
∂
θ
i
J
(
θ
0
,
θ
1
,
.
.
.
,
θ
n
)
\lambda \frac{\partial }{{\partial {\theta _i}}}J({\theta _0},{\theta _1},...,{\theta _n})
λ∂θi∂J(θ0,θ1,...,θn)
(4)确定是否对于所有的
θ
i
{\theta _i}
θi,梯度下降的距离都小于
ε
\varepsilon
ε,如果小于,算法终止;否则执行下一步;
(5)更新所有
θ
i
{\theta _i}
θi:
θ
i
:
=
θ
i
−
λ
∂
∂
θ
i
J
(
θ
0
,
θ
1
,
.
.
.
,
θ
n
)
{\theta _i}: = {\theta _i} - \lambda \frac{\partial }{{\partial {\theta _i}}}J({\theta _0},{\theta _1},...,{\theta _n})
θi:=θi−λ∂θi∂J(θ0,θ1,...,θn)
(6)循环(1)-(5);
二、逻辑回归推导
由于线性回归模型的输出是连续的实值,而逻辑回归是二分类模型,因此需要把线性回归的实值转换成 0/1 值,在逻辑回归中采用 sigmoid 函数,即:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{{1 + {e^{ - z}}}} g(z)=1+e−z1
这个函数有非常好的特性,即当 z 趋于正无穷时,函数值接近于1;当 z 趋于负无穷时,函数值接近于0,这个特性使它非常适用于 LR 模型,另外它的导数:
g ′ ( z ) = g ( z ) ( 1 − g ( z ) ) {g^\prime }(z) = g(z)(1 - g(z)) g′(z)=g(z)(1−g(z))
sigmoid函数的图像如下图:

于是得到 LR 的假设函数:
h θ ( x ) = 1 1 + e − θ T x {h_\theta }(x) = \frac{1}{{1 + {e^{ - {\theta ^T}x}}}} hθ(x)=1+e−θTx1
可以把 h θ ( x ) {h_\theta }(x) hθ(x) 理解为样本 x 为正样本的概率,那么有:
P ( y = 1 ∣ x ; θ ) = h θ ( x ) P ( y = 0 ∣ x ; θ ) = 1 − h θ ( x ) \begin{array}{l} P(y = 1|x;\theta ) = {h_\theta }(x)\\ P(y = 0|x;\theta ) = 1 - {h_\theta }(x) \end{array} P(y=1∣x;θ)=hθ(x)P(y=0∣x;θ)=1−hθ(x)
对于数据集中的 m 个样本来说,有极大似然函数:
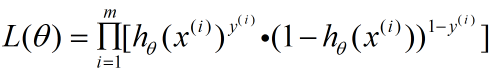
以下是求解极大似然函数的过程,也是导出 LR 模型损失函数的过程:
对上式取负的对数,有:
J ( θ ) = − L n L ( θ ) = − ∑ i = 1 m [ ( y ( i ) log h θ ( x ( i ) ) + ( 1 − y ( i ) ) log ( 1 − h θ ( x ( i ) ) ] J(\theta ) = - LnL(\theta ) = - \sum\limits_{i = 1}^m {[({y^{(i)}}\log {h_\theta }({x^{(i)}})} + (1 - {y^{(i)}})\log (1 - {h_\theta }({x^{(i)}})] J(θ)=−LnL(θ)=−i=1∑m[(y(i)loghθ(x(i))+(1−y(i))log(1−hθ(x(i))]
此式即为LR模型的损失函数,这个函数正好是一个凸函数,可以使用梯度下降法进行求解,参数更新推导如下:
∂ ∂ θ j J ( θ ) = − ( y 1 h θ ( x ) − ( 1 − y ) 1 1 − h θ ( x ) ) ∂ ∂ θ j h θ ( x ) \frac{\partial }{{\partial {\theta _j}}}J(\theta ) = - (y\frac{1}{{{h_\theta }(x)}} - (1 - y)\frac{1}{{1 - {h_\theta }(x)}})\frac{\partial }{{\partial {\theta _j}}}{h_\theta }(x) ∂θj∂J(θ)=−(yhθ(x)1−(1−y)1−hθ(x)1)∂θj∂hθ(x)
= − y ( 1 − h θ ( x ) − ( 1 − y ) h θ ( x ) ) h θ ( x ) ( 1 − h θ ( x ) ) ∂ ∂ θ j h θ ( x ) = - \frac{{y(1 - {h_\theta }(x) - (1 - y){h_\theta }(x))}}{{{h_\theta }(x)(1 - {h_\theta }(x))}}\frac{\partial }{{\partial {\theta _j}}}{h_\theta }(x) =−hθ(x)(1−hθ(x))y(1−hθ(x)−(1−y)hθ(x))∂θj∂hθ(x)
= − y − h θ ( x ) h θ ( x ) ( 1 − h θ ( x ) ) h θ ( x ) ( 1 − h θ ( x ) ) ∂ ∂ θ j h θ ( x ) = - \frac{{y - {h_\theta }(x)}}{{{h_\theta }(x)(1 - {h_\theta }(x))}}{h_\theta }(x)(1 - {h_\theta }(x))\frac{\partial }{{\partial {\theta _j}}}{h_\theta }(x) =−hθ(x)(1−hθ(x))y−hθ(x)hθ(x)(1−hθ(x))∂θj∂hθ(x)
= ( h θ ( x ) − y ) x j = ({h_\theta }(x) - y){x_j} =(hθ(x)−y)xj
即更新:
θ j : = θ j − λ ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) {\theta _j}: = {\theta _j} - \lambda ({h_\theta }({x^{(i)}}) - {y^{(i)}}){x_j}^{(i)} θj:=θj−λ(hθ(x(i))−y(i))xj(i)
根据梯度下降算法的步骤更新即可求解。















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









