







前言
最近预处理数据需要使用插值来填充; 首先是sklearn.impute.SimpleImputer方法, strategy 只有mean, median等; 我需要相邻的邻居值来做插值, 所以选中了sklearn.impute.KNNImputer
疑问
代码:imputer = KNNImputer(n_neighbors=2)
Data Before performing imputation
Maths Chemistry Physics Biology
0 80.0 60.0 NaN 78.0
1 90.0 65.0 57.0 83.0
2 NaN 56.0 80.0 67.0
3 95.0 NaN 78.0 NaN
After performing imputation
[[80. 60. 68.5 78. ]
[90. 65. 57. 83. ]
[87.5 56. 80. 67. ]
[95. 58. 78. 72.5]]
Maths第三列(Nan)是怎么算出来的, 我一开始用了两个最邻近的数值, 怎么算都不对; 后来看了youtube才恍然大悟:KNNImputer说的近邻并不是Math这列的物理近邻, 而是 用其他的科目(Chemistry, Physics等)去计算euclidean distance; 根据euclidean distance来判断邻居, 所以邻居应该是person0, person3 !
直观上理解就是: 如果某两个人其他科目的成绩都接近, 那么这两个人即是相似的, 他们的Maths成绩很可能接近;
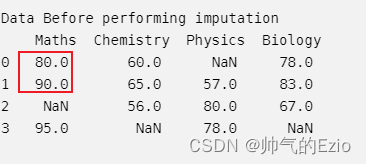
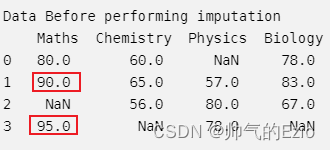
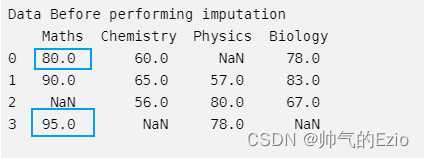
euclidean distance计算方式
*KNN_imputer原理视频(传不上来图片, 大家只能自己看视频了):
https://www.youtube.com/watch?v=AHBHMQyD75U














 2783
2783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









