






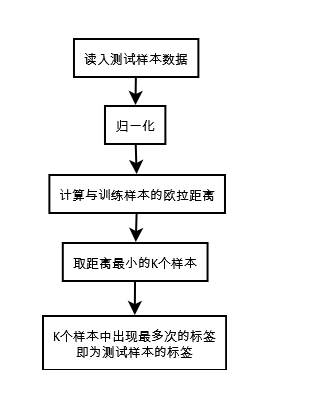
<span style="font-family: Arial, Helvetica, sans-serif;">Python代码:</span><span style="font-family: Arial, Helvetica, sans-serif;">def classify0(inX,dataSet,labels,k): </span> dataSetSize=dataSet.shape[0] ##shape代表矩阵的一边的长度
diffMat=tile(inX,(dataSetSize,1))-dataSet ##j将inX重复成(dataSetSize,1)的矩阵,减去dataSet,获得每一项的离差
sqDiffMat=diffMat**2 ##矩阵的**乘数代表矩阵中每一项自己相乘为乘方
sqDistances=sqDiffMat.sum(axis=1) ##将矩阵每一行中的元素相加
distances=sqDistances**0.5 ##将矩阵每一项自己取0.5次方
sortedDistIndicies=distances.argsort() ##argsot()顺序:从小到大
classCount={} ##新建一个字典
for i in range(k): ##从最小的开始到第k小的
voteIlabel=labels[sortedDistIndicies[i]]
classCount[voteIlabel]=classCount.get(voteIlabel,0)+1
sortedClassCount =sorted(classCount.iteritems(),
key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]</pre><pre name="code" class="python">编辑:1.tile:tile(A,n),功能是将数组A重复n次,构成一个新的数组,我们还是使用具体的例子来说明问题: 2.举例子:
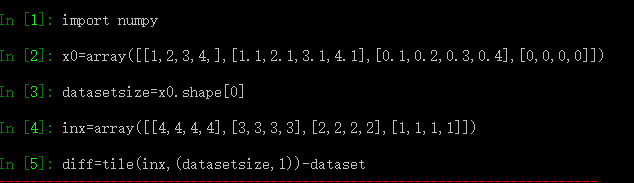
但是由于矩阵维度的问题,导致无法计算:

[4,4]的矩阵经过[4,1]的重复之后变成了[16,4]的矩阵;这说明,inx应该是用于分类的输入向量,即将对其进行分类,比如,训练样本是[4,4]的矩阵,标记好,矩阵的每一行都是一次样本值,输入样本与[1x4,4]每一个求距离,输出距离最小的那一项对应的标签(如上图)
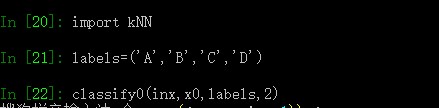
将labels标记为:'A','B','C','D',然后将数据分类:
得到结果是A















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









