







Routing and Traffic Engineering
传统数据中心的网络结构是非常简单的,就像实验室的局域网一样,采用分层次的树状结构。路由算法采用Spanning Tree。
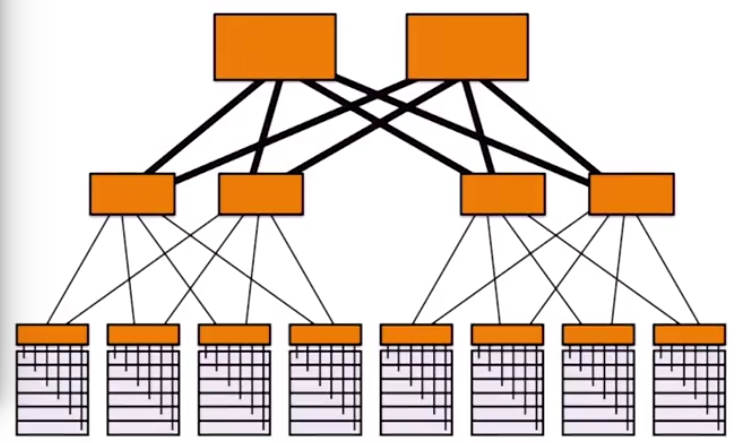
但是用这种方法的话,顶层的交换机压力会非常地大,需要花大资金买高端的交换机。一种改进方法如下所示,将大交换机才分成更多小交换机,并且使用更多的链路。
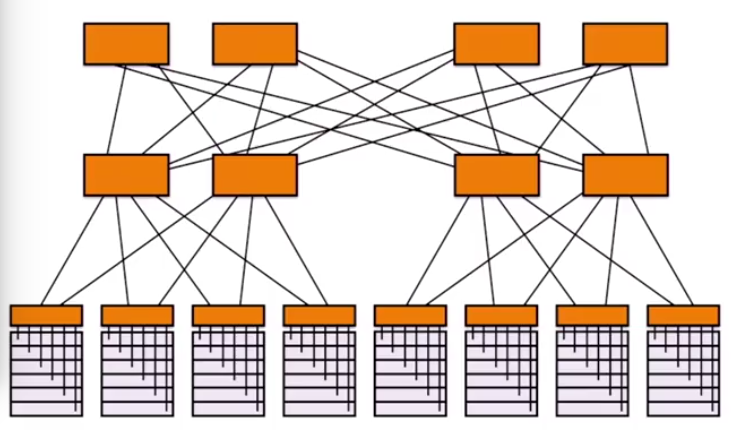
现在有许多更屌的路由方法,例如TRAIL,所有链路全部接上,全部可用。具体实现方法还没看,有空可以研究一下。
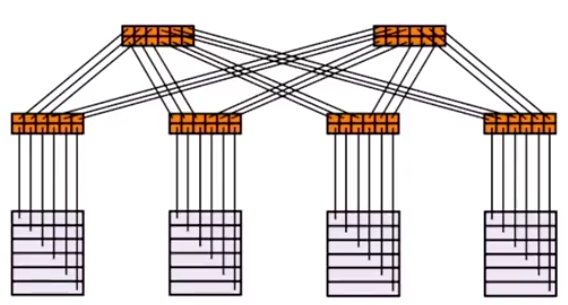
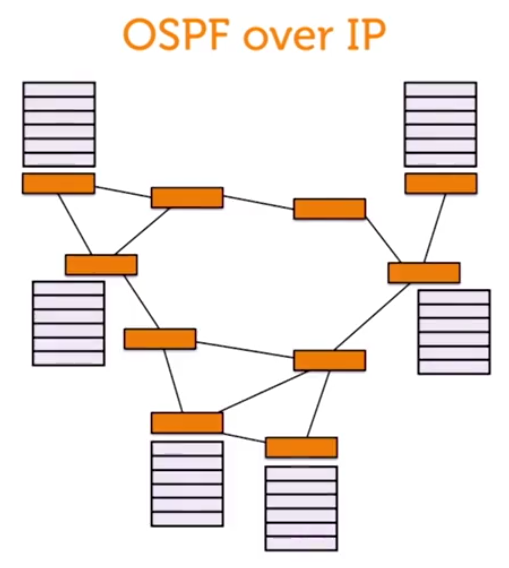
由于现代数据中心越来越复杂,局域网的路由方法都hold不住了,现在连互联网的路由方法都被考虑应用在数据中心上。例如内部网关协议OSPF,甚至外部网关协议BGP(居然复杂到这种程度?!应该是DC之间的协议吧)。
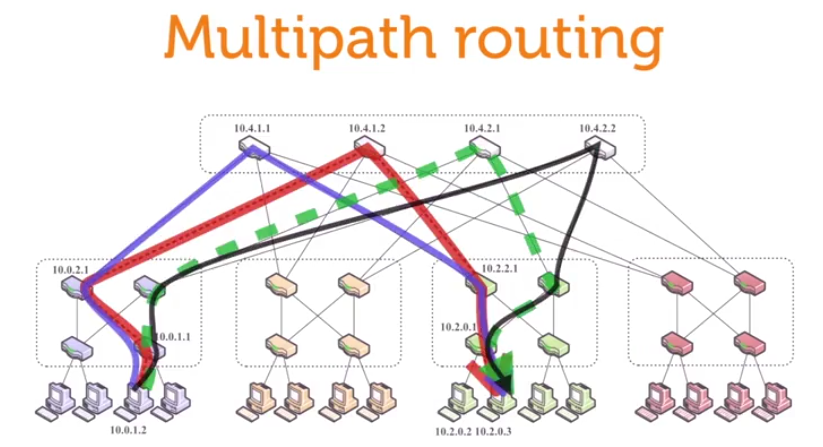
Multiple Path
Multiplepath routing
为了使各条链路负载均衡,在传输packets时采用多路径并行传输,也就是multiple path。如下图所示,四条路一起发。
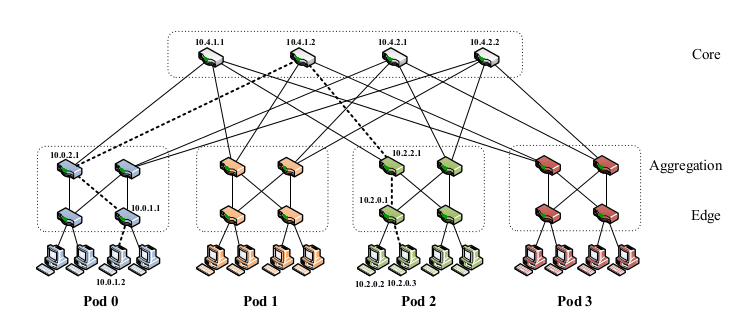
Fat Tree
首先需要解释一下这个网络拓扑,这叫fat-tree topology。参考paper:A Scalable, Commodity Data Center Network Architecture 。
假设有
k
个小集群(pod),每个交换机有
- 每个pod需要有
k
个交换机,分成两层,每层
k/2 个交换机 - 下层的交换机每个需要连接 k/2 个主机;上层交换机每个需要连 k/2 个核心交换机。那么每个交换机剩下的 k/2 个端口用于上下层互联。
- 核心层有 (k/2)2 个交换机,其每一个端口都连着一个小集群pod。
- 一个由 k-port 交换机组成的 fat-tree 最多可以支持
k3/4
台主机。
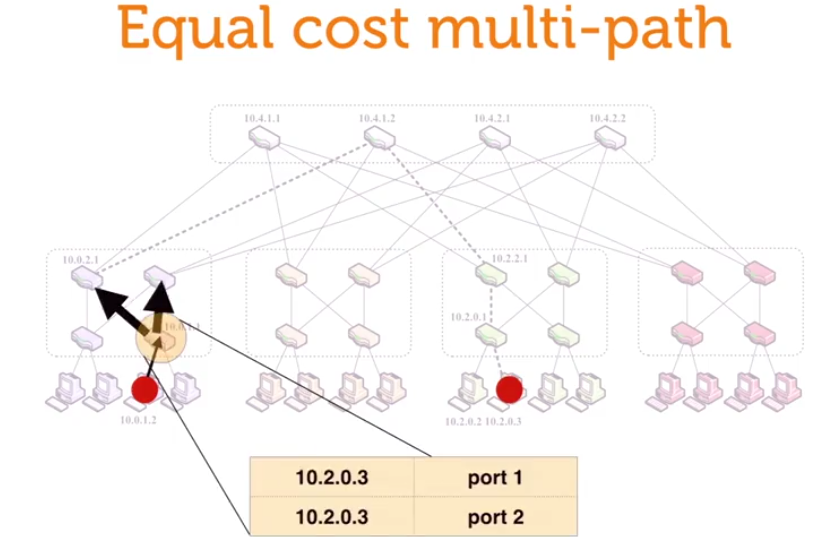
Equal cost multi-path
具体怎么做呢?如下所示,每次选路都random选一条,而且是等概率地选。
Flowlets
但是多路发送会带来一个问题,就是包乱序。一开始我并不以为这是个问题,因为TCP有 sliding window,应该不会是问题。知道Cousera论坛上别人给我发了这篇文章 reordering。乱序会显著降低网络性能。
A network path that suffers from persistent packet reordering will have severe performance degradation.
Reordering 主要带来三个问题,重复地ack, 误以为拥塞而减小拥塞窗口, 增加buffer压力:
- When a network path reorders data segments, it may cause the TCP receiver to send more than three successive dupacks , and this triggers the Fast Retransmit procedure at the TCP sender for data segments that may not necessarily be lost.
- he TCP transport protocol assumes congestion in the network only when it assumes that a packet is dropped at the gateway.
- TCP ensures that the receiving application receives data in order.
所以多路发送必须减少 reordering。可以参考这篇文章:
Dynamic Load Balancing Without Packet Reordering
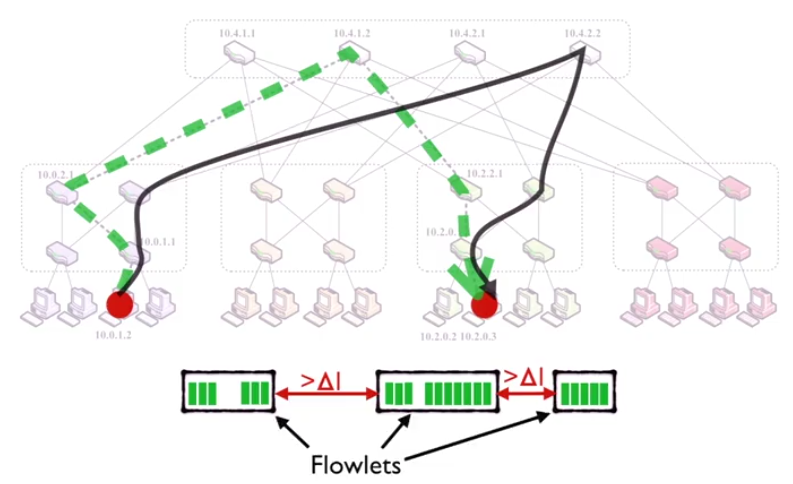
CONGA
最后有一篇很重要的paper,CONGA: Distributed Congestion-Aware Load Balancing for Datacenters。说一定要把fig. 1搞懂。有空看完继续补充。
补充:
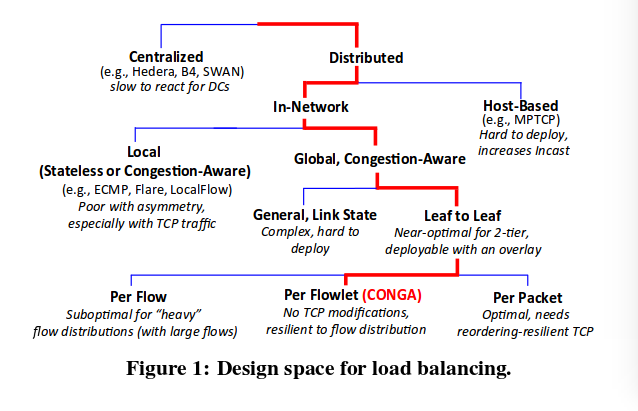
其他方法的缺点
- Centralized schemes are too slow for the traffic volatility in datacenters.
数据中心流量波动大,中心化控制不够快。 - Host-based methods such as MPTCP are challenging to deploy because network operators often do not control the end-host stack (e.g., in a public cloud) and even when they do, some high performance applications (such as low latency storage systems [39, 7]) bypass the kernel and implement their own transport.
基于主机的控制方法难以部署。首先是网络很难控制终端主机(例如公有云),就算可以,也需要实现自己的传输方法(这个并不理解…)。 - Local congestion-aware mechanisms are suboptimal and can perform even worse
than ECMP with asymmetry.
这里所说的不对称,大体是这样一种情况:对于ECMP,它采用的策略是将流量均匀随机地分配到每一条链路上。那么,一旦某些链路出现错误(link failure),ECMP就会带来不对称。因为它不应该继续向已经fail掉的link上分配。 - Leaf to Leaf
不理解。 - Per Flow. 这样控制粒度不够细化,flow的差异非常大;而Per Packet呢,粒度够细,但是要面对失序问题(reordering),跟TCP相关了。所以,Per Flowlet最好,不需要修改TCP,而且粒度也够细。















 2636
2636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









