







几个比较常见的概念:
rank: 多机多卡时代表某一台机器,单机多卡时代表某一块GPU
world_size: 多机多卡时代表有几台机器,单机多卡时代表有几块GPU
local_rank: 多机多卡时代表某一块GPU, 单机多卡时代表某一块GPU
单机多卡常用的启动方式为torch.distributed.launch。在启动器启动python脚本后,在执行过程中,启动器会将当前进程的index 通过参数传递给 python,我们可以这样获得当前进程的 index:即通过命令行参数 --local_rank 来告诉我们当前进程使用的是哪个GPU,用于我们在每个进程中指定不同的device(也有其他的方式来获取当前进程)。进程可以简单理解为运行一个代码,分布式训练采用多GPU多进程的方式,即每个进程都要独立运行一份训练代码,由此,为每个GPU分配一个进程进行分布式训练。通常不需要在每个进程中都有日志或其他信息(模型权重等)的输出,故可以通过--local_rank来指定打印日志或其他信息(模型权重等)的进程。
下面是单机多卡分布训练时核心点:
1.初始化操作:
device = torch.device('cuda:{}'.format(args.local_rank))
torch.cuda.set_device(device) # 为当前进程指定GPU
torch.distributed.init_process_group(backend="nccl", init_method="env://",) # 初始化进程组
dist.barrier() #等待所有GPU运行,同步所有进程torch.distributed.init_process_group()方法内的其他参数详见官方文档(store参数未指定时,rank和world_size参数可省略,反之,不可。对于不同的进程world_size是一样的,但是rank是不一样的.)
2.定义Sampler:
DistributedSampler (dataset)的处理,用来为不同的GPU分配数据
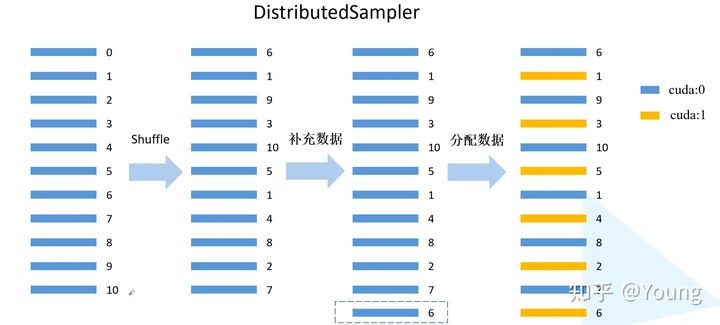
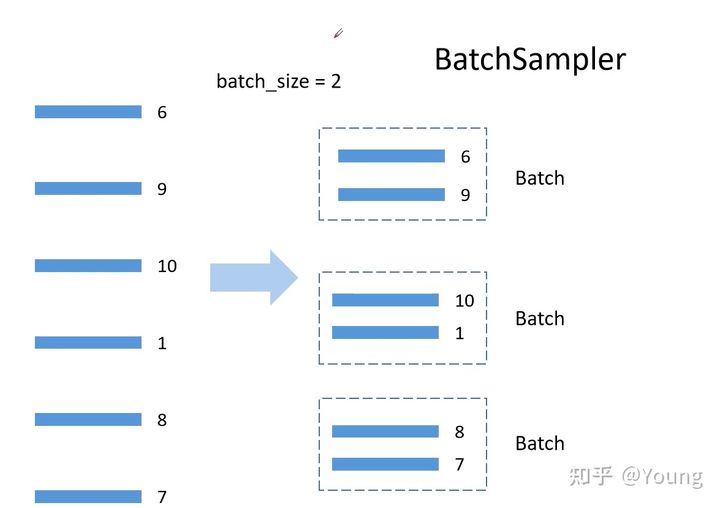
BatchSampler(sampler, batch_size, drop_last)的处理,用来为当前GPU组织数据
3.权重初始化
多卡训练时,如果没有预训练权重而进行随机初始化进行训练,必须要保证每张卡上初始化的权重是一模一样的
dist.barrier() #等待所有GPU运行,同步所有进程4.SyncBatchNorm(同步BN)
使用所有设备上的batch计算均值和方差,但会带来速度上的下降
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model)
5. 转化为DDP
torch.nn.parallel.distributedDataParallel(model,device_ids,find_unused_parameters,output_device)
PyTorch 有哪些坑/bug?26 赞同 · 4 评论回答
6.sampler.set_epoch(epoch)
用于控制在每一轮迭代,为不同的GPU分配不同的数据
7.loss
loss为当前设备对应当前批次计算所得到的损失,而期待的损失应该是所有设备之间的均值,故需要用一个函数reduce_value/tensor去求得不同设备之间的均值
def reduce_tensor(inp):
"""
Reduce the loss from all processes so that process with rank 0 has the averaged results.
"""
world_size = dist.get_world_size()
if world_size < 2:
return inp
with torch.no_grad():
reduced_inp = inp
torch.distributed.reduce(reduced_inp, dst=0) # 求和操作
return reduced_inp / world_size
8.dist.destroy_process_group()释放资源
9.Bug
Reference:
pytorch多GPU并行训练bilibili.com/video/BV1yt4y1e7sZ?t=2244正在上传…重新上传取消















 1925
1925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









