









视频链接:李宏毅机器学习(2016)(3)_演讲•公开课_科技_bilibili_哔哩哔哩
课程资源:Hung-yi Lee
课程相关PPT已经打包命名好了:链接:https://pan.baidu.com/s/1gfRjrc3 密码:pstr
我的第二讲笔记:http://blog.csdn.net/sinat_25346307/article/details/78725660
Gradient Descent
本讲主要讲解了关于梯度下降算法使用的一些技巧(tips)以及最后对梯度下降背后的数学原理和梯度下降的限制进行了讲解。
Tip1:Tuning your learning rate
我们知道学习率太大或者太小都会对找到最优点有不好的影响。一个普遍流行且简单的观点是在每个epoch后,通过乘以一个因子来减小学习率。因为在一开始,距离目标点较远就需要一个较大的学习率,经过多个epoch后,就开始接近目标点,因此需要减小学习率。此外,学习率不能够达到one-size-fits-all,对应不同的参数有不同的学习率。
Adagrad:
在Adagrad中,更新权值不再是仅仅减去学习率乘以偏导数。而是:
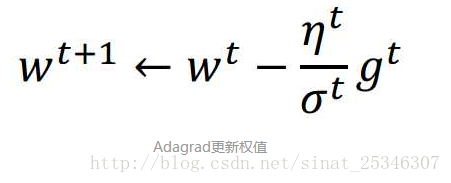
此处,

参数解释

之前参数的倒数的均方根
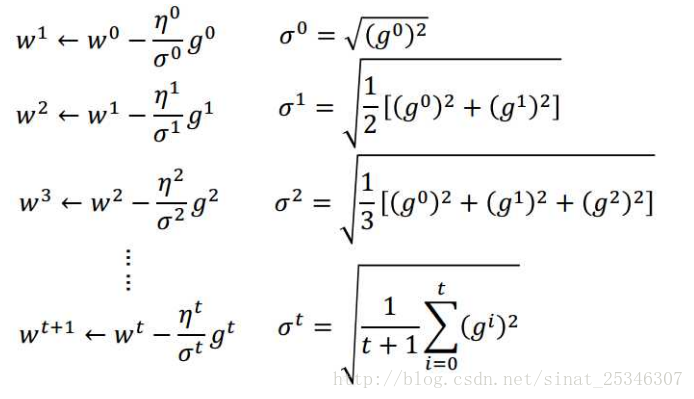
因此,

Tip2:Stochastic Gradient Descent
简言之,随机梯度下降就是每次随机(或顺序)选择一个训练样本计算损失进行权值更新,而不是像批处理那样对全部的训练样例进行损失求和之后再进行权值的更新。

随机梯度下降
虽然一次仅处理一个样例就更新权值,会出现更新权值的方向并不按预期的方向,但是在整个训练样本上做梯度下降之后,权值的整体更新方向会朝着预期的方向,并且会更快。

Tip3:Feature Scaling
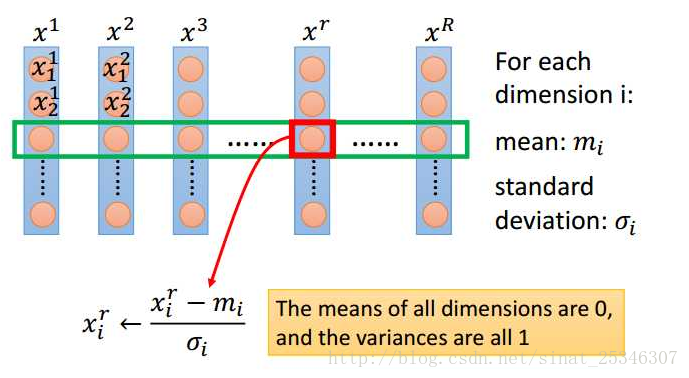
Feature Scaling 可理解为使得特征的输入在相同的尺度,也可称为规范化输入。

这样能够使得损失函数能够更快得优化。
通常采用的规范化方法是:
Gradient Descent Theory
在使用随机梯度进行最小化损失函数时,是否每次更新参数后,损失函数的值都会变小?
这个陈述是不正确的。并不能保证每次都朝着预期的方向更新参数。
梯度下降理论的数学支持。
先介绍下泰勒级数。

泰勒级数
当然了,泰勒级数同样可以对多变量进行展开。
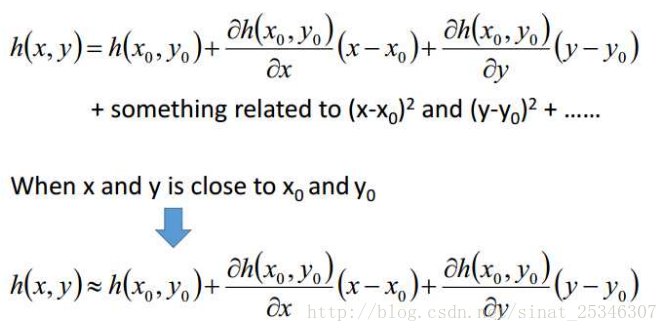
多变量的泰勒级数
基于泰勒级数,只要红色圈足够小,在红色圈内就满足:
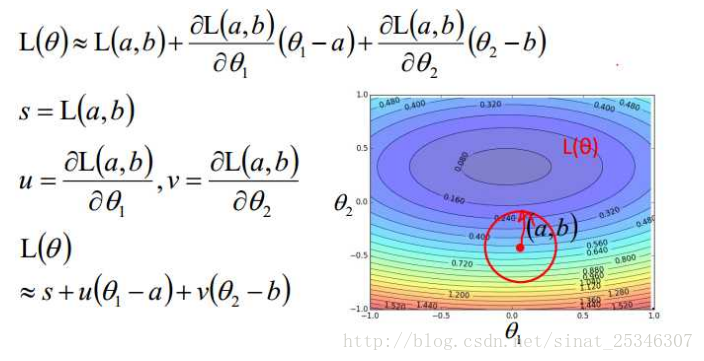
这就变成找到对应的θ1和θ2能够使得L(θ)最小。并且θ1和θ2满足:


如果使用泰勒级数的二次展开式的话,就会变成使用牛顿法来求解最优问题了。
但在深度学习中,那并不实用,还是用选择用一次展示式——梯度下降。
More Limitations of Gradient Descent
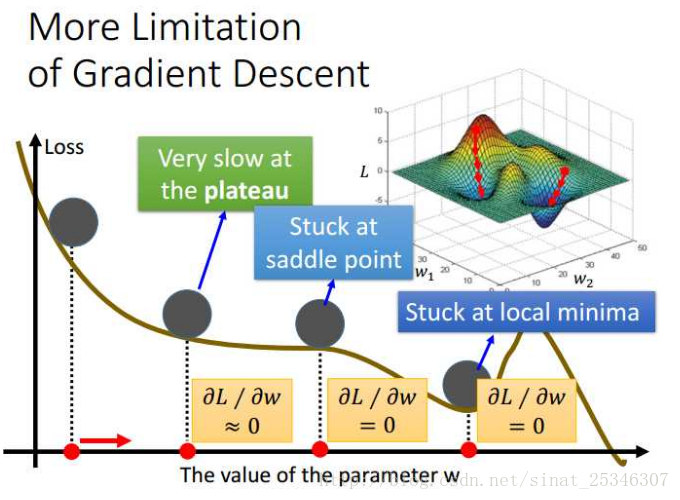
在梯度下降中,通常认为是当导数值为0时,就认为求得了最优解了。但是,出现导数为0的点并不仅仅是最优点,还有可能是之前谈及的局部最优点,鞍点(不是极大值也不是极小值的临界点),甚至在“高原”处,导数值小到可以约等于0。这就是梯度下降的限制。
总结:
本讲主要讲解了能够使得梯度下降工作更高效的三种方法:
Adagrad、SGD、Feature Scaling。
以及梯度下降理论背后的数学理论知识和梯度下降的限制。















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









