






安装方法参考 http://blog.csdn.net/xunan003/article/details/74905696
以及 http://blog.csdn.net/u013277656/article/details/72627602?utm_source=itdadao&utm_medium=referral
未完待续。。。
ubuntu16.04安装:
采用镜像解压U盘安装,在官网下载镜像包后解压拷贝至U盘中,在电脑BIOS设置U盘启动
显卡驱动
NVIDIA MX150驱动安装(以小米笔记本为例)
安装完ubuntu kylin16.04后,开机发热严重,风扇狂转。应该是显卡驱动的问题,通过输入以下代码查看最合适的驱动
sudo ubuntu-drivers devices 如图:
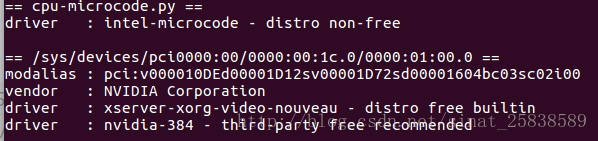
显卡驱动版本应该选择nvidia-384
下面有三种方法:
- 方法一
在NVIDIA驱动下载官网下载对应的run文件
首先卸载系统中的nvidia驱动:
sudo apt-get purge nvidia*由于系统自带的开源驱动与nvidia不兼容,要屏蔽掉nouveau
新建blacklist-nouveau.conf文件,输入命令:
sudo gedit /etc/modprobe.d/blacklist-nouveau.conf往文件中写入:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off再更新一下
sudo update-initramfs -u保存并退出。这一步是为了禁掉Ubuntu自带开源驱动nouveau。之后sudo reboot重启系统。在终端执行命令:
lsmod | grep nouveau如果没有feedback则已经禁用了nouveau。
下面我们找到驱动的存放目录,打开终端,为文件添加可执行权限:
sudo chmod a+x NVIDIA-Linux-x86_64-384.69.run用这种方法安装有一个弊端,就是不能在GUI中执行.run文件。
首先输入:
sudo /etc/init.d/lightdm stop按下ctrl+alt+F1进入tty1,按下ctrl+alt+F7回到桌面
然后
sudo ./NVIDIA-Linux-x86_64-384.69.run --no-opengl-files
sudo /etc/init.d/lightdm start一定不要装opengl。
ok后重启电脑
输入nvidia-smi查看安装是否完成
(我用该方法时遇到一个问题,驱动貌似是装了,但是打开nvidia-settings后没有选择驱动的地方,也不能查看当前驱动的状态,经过多次卸载sudo apt-get purge nvidia*重装也无济于事。。。)
于是换到了方法2
- 方法二
使用ppa安装(此处感谢Linux公社的教程)
卸载之前的驱动,和法一一样
1:sudo add-apt-repository ppa:mamarley/nvidia
2:输入你的root密码
3:sudo apt-get update
4:sudo apt-get install nvidia-版本号 nvidia-prime
5:等待安装完成,重启之后,你的电脑应该就是在用nvidIa显卡驱动了,可以使用这个进行显卡切换,切换之后必须注销登陆一次才行。
用这个方法时我也遇到了问题,就是下载卡在24%不动了,后来链接手机热点才完成下载安装,总体来说,这个方法最好用。
输入nvidia-smi验证驱动安装

显卡快速切换
打开终端,输入以下命令:
sudo add-apt-repository ppa:nilarimogard/webupd8 #添加PPA更新源
sudo apt-get update #刷新更新源列表
sudo apt-get install prime-indicator #安装双显卡切换指示器
cuda8.0
- 1.安装
https://developer.nvidia.com/cuda-downloads
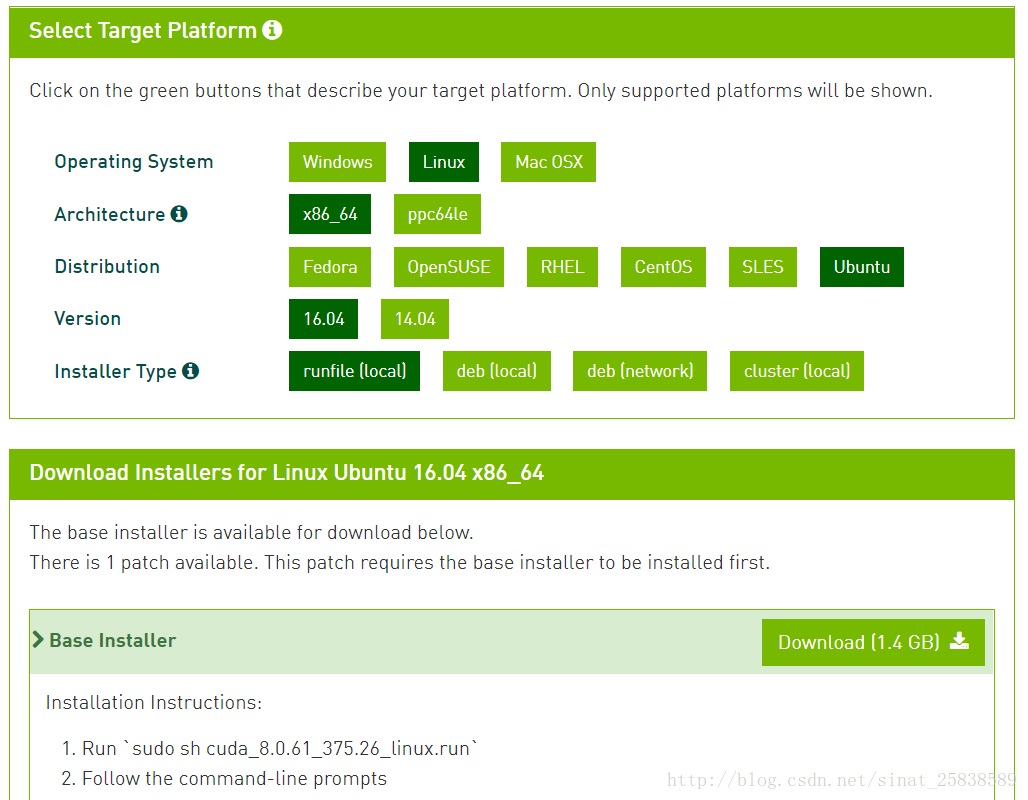
sudo sh cuda_*****.run 执行后会有一系列的Y/n选择,其中选择显卡驱动的一项一定选n。其他的随意,一般默认即可。
ubuntu的gcc编译器是5.4.0,然而cuda8.0不支持5.0以上的编译器,因此需要降级,把编译器版本降到4.9:
在terminal中执行:
sudo apt-get install gcc-4.9 gcc-5 g++-4.9 g++-5
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-4.9 20
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 10
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-4.9 20
sudo update-alternatives --install /usr/bin/g++ g++ /usr/bin/g++-5 10
sudo update-alternatives --install /usr/bin/cc cc /usr/bin/gcc 30
sudo update-alternatives --set cc /usr/bin/gcc
sudo update-alternatives --install /usr/bin/c++ c++ /usr/bin/g++ 30
sudo update-alternatives --set c++ /usr/bin/g++
配置cuda8.0之后主要加上的一个环境变量声明
gedit ~/.bashrc 在文件~/.bashrc之后加上:
export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
然后设置环境变量和动态链接库,在命令行输入
sudo gedit /etc/profile 在打开的文件里面加上(注意等号两边不能有空格)
export PATH=/usr/local/cuda/bin:$PATH 保存之后,创建链接文件
sudo gedit /etc/ld.so.conf.d/cuda.conf
在打开的文件中添加如下语句:
/usr/local/cuda/lib64
保存退出执行命令行:
sudo ldconfig
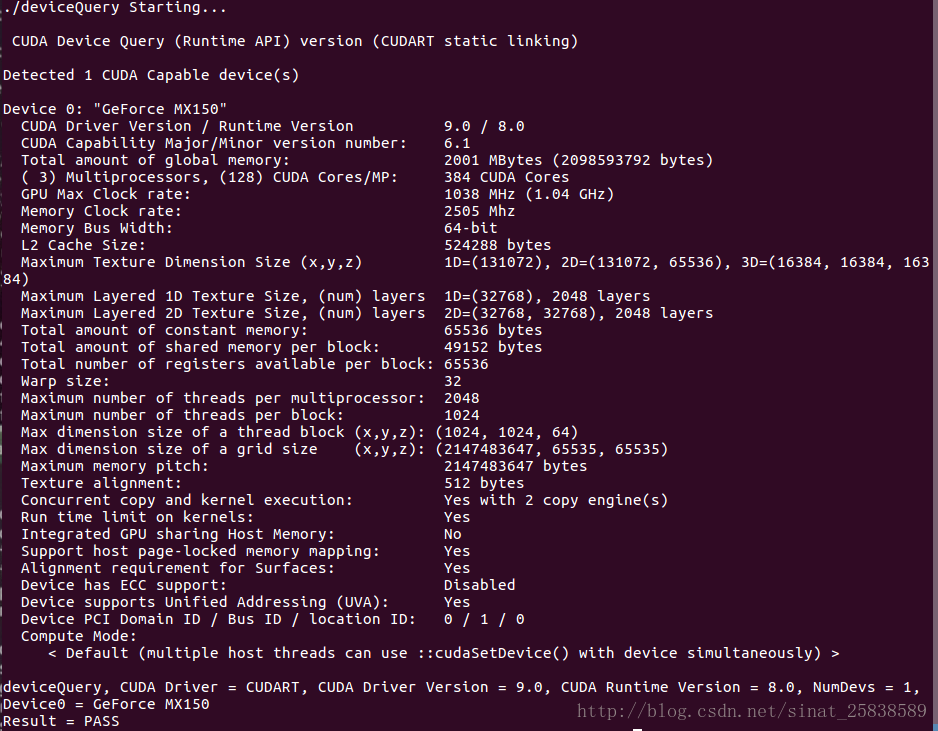
- 2.测试
测试cuda的Samples
命令行输入(注意cuda-8.0是要相对应自己的cuda版本)
cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
sudo make
sudo ./deviceQuery 返回GPU信息:表示配置成功
cudnn
cuDNN是GPU加速计算深层神经网络的库。
首先去官网(https://developer.nvidia.com/rdp/cudnn-download)下载cuDNN,可能需要注册一个账号才能下载。
cd进入cudnn7.0解压之后的include目录,在命令行进行如下操作:
sudo cp cudnn.h /usr/local/cuda/include/ #复制头文件 再cd进入lib64目录下的动态文件进行复制和链接:(7.0.1为对应版本具体可修改)
sudo cp lib* /usr/local/cuda/lib64/ #复制动态链接库
cd /usr/local/cuda/lib64/
sudo rm -rf libcudnn.so libcudnn.so.7 #删除原有动态文件
sudo ln -s libcudnn.so.7.0.1 libcudnn.so.7 #生成软衔接
sudo ln -s libcudnn.so.7 libcudnn.so #生成软链接 Opencv3.2.0
linux下查看opencv版本
pkg-config --modversion opencv
在github上下载代码并将其解压到你要安装的位置,(下载的位置还是在home/ubuntu、Downloads文件夹下)
首先安装Ubuntu系统需要的依赖项,虽然我也不知道有些依赖项是干啥的,但是只管装就行,也不会占据很多空间的。
sudo apt-get install --assume-yes libopencv-dev build-essential cmake git libgtk2.0-dev pkg-config python-dev python-numpy libdc1394-22 libdc1394-22-dev libjpeg-dev libpng12-dev libtiff5-dev libjasper-dev libavcodec-dev libavformat-dev libswscale-dev libxine2-dev libgstreamer0.10-dev libgstreamer-plugins-base0.10-dev libv4l-dev libtbb-dev libqt4-dev libfaac-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev x264 v4l-utils unzip 然后安装opencv需要的一些依赖项,一些文件编码解码之类的东东。
sudo apt-get install build-essential cmake git sudo apt-get install ffmpeg libopencv-dev libgtk-3-dev python-numpy python3-numpy libdc1394-22 libdc1394-22-dev libjpeg-dev libpng12-dev libtiff5-dev libjasper-dev libavcodec-dev libavformat-dev libswscale-dev libxine2-dev libgstreamer1.0-dev libgstreamer-plugins-base1.0-dev libv4l-dev libtbb-dev qtbase5-dev libfaac-dev libmp3lame-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev x264 v4l-utils unzip 在终端中cd到OpenCV文件夹下(解压的那个文件夹),然后
mkdir build #新建一个build文件夹,编译的工程都在这个文件夹里
cd build/ - 问题
cmake opencv 时遇到nvcc warning : The ‘compute_20’, ‘sm_20’, and ‘sm_21’ ……
解决办法如下:
sudo cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local -D CUDA_ARCH_BIN="5.0" ..CUDA_ARCH_BIN代表你当前显卡的计算能力。具体能力值可在nvidia官网下载cuda的地方查阅。添加CUDA计算能力值后即可正常编译通过。
cmake成功后,会出现如下结果,提示配置和生成成功:
– Configuring done
– Generating done
– Build files have been written to: /home/ise/software/opencv-3.2.0/build
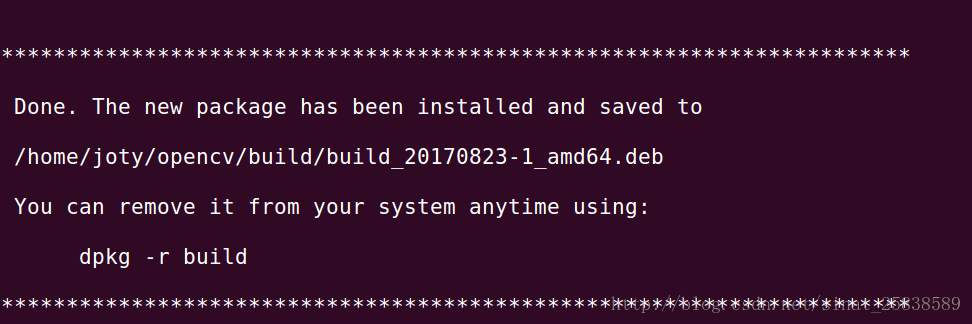
使用checkinstall:
使用checkinstall的目的是为了更好的管理我安装的opencv,因为opencv的安装很麻烦,卸载更麻烦,其安装的时候修改了一大堆的文件,当我想使用别的版本的opencv时,将当前版本的opencv卸载就是一件头疼的事情,因此需要使用checkinstall来管理我的安装。执行了checkinstall后,会在build文件下生成一个以backup开头的.tgz的备份文件和一个以build开头的.deb安装文件,当你想卸载当前的opencv时,直接执行dpkg -r build即可。
在install时,执行下面代码后出现错误
sudo /bin/bash -c 'echo "/usr/local/lib" > /etc/ld.so.conf.d/opencv.conf'
sudo ldconfig 在sudo ldconfig时遇到:/sbin/ldconfig.real: /usr/local/cuda/lib64/libcudnn.so.6 不是符号连接
解决办法:
建立硬链接
首先找到usr/local/cuda-8.0/lib64/目录,搜索 libcudnn 然后发现
两个文件
libcudnn.so.6 和libcudnn.so.6.0.21
理论上只有一个libcudnn.so.6.0.21
sudo ln -sf /usr/local/cuda/lib64/libcudnn.so.6.0.21 /usr/local/cuda/lib64/libcudnn.so.6- 完成
caffe
- 在make py的时候,遇到了这个错误:
/usr/bin/ld: cannot find -lhdf5_hl
/usr/bin/ld: cannot find -lhdf5
collect2: error: ld returned 1 exit status这说明连接器找不到 hdf5_hl和hdf5这两个库,没法进行链接。
我的解决方案是更改makefile:在makefile中作如下更改:
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_hl hdf5
LIBRARIES += glog gflags protobuf boost_system boost_filesystem m hdf5_serial_hl hdf5_serial把第一行注释,然后改成第二行的内容就可以了。
此解决方案引用自http://blog.csdn.net/baiyu9821179/article/details/73166497
- 问题2
/usr/bin/ld:/usr/local/cuda/lib64/libcudnn.so: file format not recognized; treating as linker script
/usr/bin/ld:/usr/local/cuda/lib64/libcudnn.so:1: syntax error
collect2: error: ld returned 1 exit status
Makefile:573: recipe for target ‘.build_release/lib/libcaffe.so.1.0.0’ failed
make: * [.build_release/lib/libcaffe.so.1.0.0] Error 1
解决方法:
移除除libcudnn.so.7.0.1以外的libcudnn.so文件
/usr/local/cuda/lib64$ sudo rm -rf libcudnn.so libcudnn.so.7
重新生成
sudo ln -s libcudnn.so.7.0.1 libcudnn.so.7
sudo ln -s libcudnn.so.7 libcudnn.so
然后
make clean
make all -j10

之后执行sudo make runtest测试是否装好
如果出现错误:
error while loading shared libraries: ×××.so.3.2: cannot open shared object file: No such file or directory

参考:
http://blog.chinaunix.net/uid-26212859-id-3256667.html
在root模式下(×××#)表示root模式,按ctrl+D切换出root用户
sudo su
×××# cat /etc/ld.so.conf
include ld.so.conf.d/*.conf
×××# echo "/usr/local/lib" >> /etc/ld.so.conf
×××# ldconfig
tensorflow
ooo
http://blog.csdn.net/BBZZ2/article/details/54141215?locationNum=2&fps=1
theano
fanQ篇
参考http://blog.csdn.net/bingyu9875/article/details/54600691
和https://my.oschina.net/shiyusen/blog/631082
使用了带有GUI的ssr-qt5
按照教程下载安装软件,注意一定要按步骤进行。尤其是update那块儿。
配置浏览器需要参考链接2,系统默认无代理。
设置终端的全局代理:
安装polipo软件
sudo apt-get install polipo
修改配置文件
config文件是只读的,要想修改里面的数据,需要获得最高权限。
cd /etc/polipo/
sudo chmod 777 config # 为config文件申请最高权限
vi /etc/polipo/config # 打开进行编辑
原文件中已经有了两句话,那么需要新加入3句话:
socksParentProxy = "localhost:1080"
socksProxyType = socks5
logLevel=4
ps:这里建议修改文件后恢复其本来的权限,这算是个好习惯。
关闭和启动polipo
关闭软件,让配置生效,然后重启。
sudo service polipo stop
sudo service polipo start
验证和使用
$ http_proxy=http://localhost:8123 curl ip.gs
Current IP / 当前 IP: 160.16..
ISP / 运营商: sakura.a***
City / 城市: Tokyo Tokyo
Country / 国家: Japan
IP.GS is now IP.SB, please visit https://ip.sb/ for more IP information, ip.gs will only use for curl purpose. / IP.GS 已更新至 IP.SB 请访问 https://ip.sb/ 获取更多信息, ip.gs 域名仅作 curl 使用
如有问题,请加入 Telegram 群 https:// t me sbfans
设置别名
每一次都输入这么一串命令实在太不人性化,解决方法就是给这个命令一个缩写的别名,比如“hp”。
vi .bashrc
打开配置文件,在最后面加上一句:
alias hp="http_proxy=http://localhost:8123"
关闭文件,执行下面代码:
source ~/.bashrc
这样,hp就可以代表之前很长的命令,试验一下:
hp curl ip.gs
为当前会话设置全局代理
难道要在每条联网命令前面都加上“hp”?当然不会,以下操作可以让当前终端窗口的所有联网命令都经过代理,一条命令,接管所有:
$export http_proxy=http://localhost:8123 # 当前终端使用代理
$ unset http_proxy # 当前终端取消代理
更为长久的代理设置
如果我想Ubuntu终端一直处于代理状态,能不能做到呢?这也是可以的,以下设置可以让本机的终端一直拥有代理能力,设置好后就完全不用操心了,类似于写入环境变量的操作。
方法很简单,将以下语句:
export http_proxy=http://localhost:8123
加入.bashrc文件末尾,再执行source ~/.bashrc即可。
软件源问题
参考
http://www.cnblogs.com/webnote/p/5767853.html
然后,刷新列表:
sudo apt-get update















 2182
2182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









