







 表示学习是机器学习中的关键步骤,旨在从原始数据中提取有效特征,简化复杂性并提高可解释性。自动化算法如无监督学习的自动编码器、树模型和深度学习(如CNN、RNN)在表示学习中扮演重要角色。相比于特征工程,表示学习在大数据场景下更显优势,因为它能自动学习和转换数据。解离性、分布式表示和深度是评估表示好坏的重要因素。
表示学习是机器学习中的关键步骤,旨在从原始数据中提取有效特征,简化复杂性并提高可解释性。自动化算法如无监督学习的自动编码器、树模型和深度学习(如CNN、RNN)在表示学习中扮演重要角色。相比于特征工程,表示学习在大数据场景下更显优势,因为它能自动学习和转换数据。解离性、分布式表示和深度是评估表示好坏的重要因素。
机器学习算法的成功与否不仅仅取决于算法本身,也取决于数据的表示。数据的不同表示可能会导致有效信息的隐藏或是曝露,这也决定了算法是不是能直截了当地解决问题。表征学习的目的是对复杂的原始数据化繁为简,把原始数据的无效信息剔除,把有效信息更有效地进行提炼,形成特征,这也应和了机器学习的一大任务——可解释性。 也正是因为特征的有效提取,使得今后的机器学习任务简单并且精确许多。在我们接触机器学习、深度学习之初,我们就知道有一类任务也是提炼数据的,那就是特征工程。与表征学习不同的是,特征工程是人为地处理数据,也是我们常听的“洗数据”。 而表示学习是借助算法让机器自动地学习有用的数据和其特征。 不过这两个思路都在尝试解决机器学习的一个主要问题——如何更合理高效地将特征表示出来。
即稍微入门一点机器学习的都知道传统地做法都人为地设计特征或者说使用已经完全标记好的数据来试图接近最好的分类效果。但实际上很多未标记的或者说标记相对较少的训练数据,我们当然可以人为标记,但也可以自动地筛选出比较重要的特征,有点类似于PCA(主成分分析)的思路,这就是表示学习或者说特征学习。
表示学习虽然从结构上讲只是数据的一个预处理手段,但是正如“工欲善其事,必先利其器”一样,它的出现提供了进行无监督学习和半监督学习的一种方法。其重要性不言而喻,以至于在花书中被单独列出来作为一章。表示学习一个比较典型的方法就是自编码器,有兴趣的可以自查。
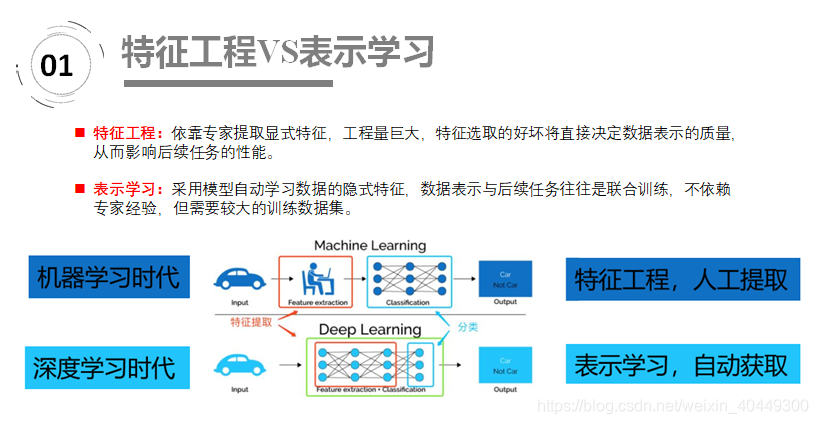
表征学习的自动化算法
我们定义了表示学
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 669
669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









