







这是一篇一本正经无聊的小研究项目。。
互联网现在面临很多新网络文体,比如弹幕文体、小红书的种草文体、网名等,这些超短文本中本身字符特征就比较少,但是表情包占比却很多,这是重要信息呀。
之前参加比赛,一般都是当作停用词直接删掉,在这些超短文本中可就不行了。

相关代码+数据可见我的github:py-yanwenzi
相关文章:
网络表情NLP(一)︱颜文字表情实体识别、属性检测、新颜发现
网络表情NLP(二)︱特殊表情包+emoji识别
几种特殊符号:颜文字,emoji,特殊标号.
其中,emoji,特殊符号都是可以分词分开的,
但是颜文字字数比较多,分词的时候会占着比较多的内容且不太好分
从符号大全这个网址来看,里面有比较多的单个特殊符号。

在py-yanwenzi的data中有一份xlsx,pecial_symbols.xlsx就是一些收集与整理。
1 emoji表情识别
github:https://github.com/carpedm20/emoji
安装:
$ !pip install emoji
相关教程:
import emoji
emoji_str = "python is 👍"
# 特殊字符转换为正常字符(相当于解码)
strs = emoji.demojize(emoji_str)
print(strs)
# 正常字符转换为特殊字符(相当于编码)
emoji_str = emoji.emojize(strs)
print(emoji_str)
# emoji的个数
print(emoji.emoji_count(emoji_str))
# emoji有哪些?list出来
print(emoji.emoji_lis(emoji_str))
输出得内容:
python is :thumbs_up:
python is 👍
1
[{'location': 10, 'emoji': '👍'}]
2 通过正则来判定
主要参考了EmojiHandle,感谢这位作者。
2.1 判断是否是表情
from collections import defaultdict
import re
frequencies = defaultdict(int)
#判断是否是表情
def isEmoji(content):
if not content:
return False
if u"\uE000" <= content and content <= u"\uE900":
return True
if u"\U0001F000" <= content and content <= u"\U0001FA99":
return True
#以下代码被上面的范围包含了
if u"\U0001F600" <= content and content <= u"\U0001F64F":
return True
elif u"\U0001F300" <= content and content <= u"\U0001F5FF":
return True
elif u"\U0001F680" <= content and content <= u"\U0001F6FF":
return True
elif u"\U0001F1E0" <= content and content <= u"\U0001F1FF":
return True
else:
return False
content = "👍"
isEmoji(content)
# True
content = "python is 👍"
isEmoji(content)
# False
这里是对单一字符进行判定。
2.2 特殊符号编码映射关系
数据可见我的github:py-yanwenzi
'''
获取SoftBank与WeChat的Emoji映射表
'''
from collections import defaultdict
frequency = defaultdict(int)
frequency1 = defaultdict(int)
frequency2 = defaultdict(int)
def getReflactTbl(filename):
frequencies = defaultdict(int)
with open(filename, 'r', encoding='utf-8-sig') as f:
for line in f:
line = line.split()
frequencies[line[0]] = line[1]
print(frequencies)
return frequencies
def getStandordTbl(filename):
frequency1 = defaultdict(int)
with open(filename, 'r', encoding='utf-8-sig') as f:
for newline in f:
while newline.find('fully-qualified # ') > -1 or newline.find('; non-fully-qualified # ') > -1:
startpos = newline.find('# ') + 2
# print(startpos)
endpos = newline.find(' ', startpos + 1)
# print(endpos)
meaning = newline[startpos:endpos]
emoji_value = newline[endpos + 1:len(newline)]
emoji_value = meaning.encode('unicode-escape').decode('utf-8').replace('\\U','').upper()
frequency1[meaning] = emoji_value.replace('\n', '')
newline = f.readline()
print(frequency1)
return frequency1
def getWechatTbl(filename):
frequency2 = defaultdict(int)
with open(filename, 'r', encoding='utf-8-sig') as f:
for newline in f:
while newline.find('fully-qualified # ') > -1 or newline.find('; non-fully-qualified # ') > -1:
startpos = newline.find('# ') + 2
# print(startpos)
endpos = newline.find(' ', startpos + 1)
# print(endpos)
emoji_value = newline[startpos:endpos]
meaning = emoji_value.encode('unicode-escape').decode('utf-8').replace('\\u','').upper()
frequency2[meaning] = emoji_value
newline = f.readline()
print(frequency2)
return frequency2
frequency = getReflactTbl('data\emoji.txt')
frequency1 = getStandordTbl('data\emoji-test.txt')
frequency2 = getWechatTbl('data\emoji-wechat.txt')
映射关系为:
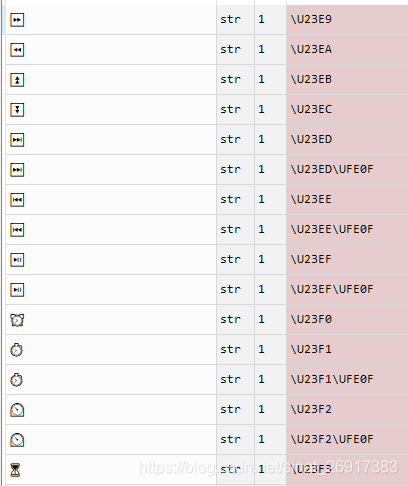
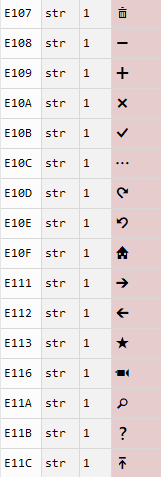
2.3 表情编码
字符编码问题,还是满头疼得。
将字符串的unicode值打印出来
u = "好"
u.encode('unicode-escape').decode('utf-8')
>>> '\\u597d'
u.encode('utf-8')
>>> b'\xe5\xa5\xbd'
u.encode('unicode-escape')
>>> b'\\u597d'
识别表情
import re
def identifyEmoji(desstr):
'''
识别表情
'''
co = re.compile(r'\\u\w{4}|\\U\w{8}')
print(co.findall(desstr))
if len(co.findall(desstr)):
return True
else:
return False
print(u'\U00010000')
a = '😁'.encode('unicode-escape').decode('utf-8')
print(a)
print(identifyEmoji(a))
>>> 𐀀
>>> \U0001f601
>>> ['\\U0001f601']
>>> True

















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









