







一、深度学习中常用的调节参数
本节为笔者上课笔记(CDA深度学习实战课程第一期)
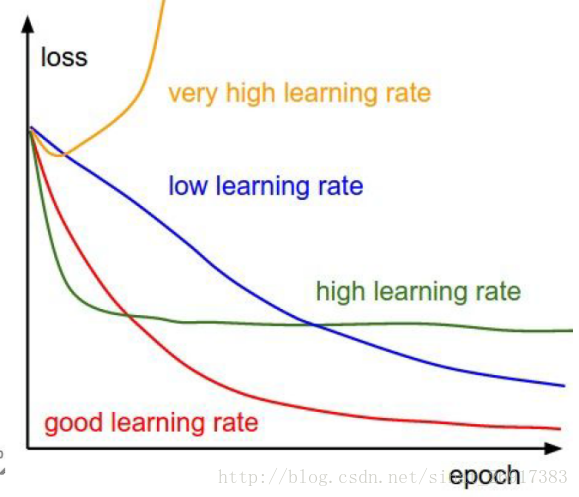
1、学习率
步长的选择:你走的距离长短,越短当然不会错过,但是耗时间。步长的选择比较麻烦。步长越小,越容易得到局部最优化(到了比较大的山谷,就出不去了),而大了会全局最优
一般来说,前1000步,很大,0.1;到了后面,迭代次数增高,下降0.01,再多,然后再小一些。
2、权重
梯度消失的情况,就是当数值接近于正向∞,求导之后就更小的,约等于0,偏导为0
梯度爆炸,数值无限大
对于梯度消失现象:激活函数
Sigmoid会发生梯度消失的情况,所以激活函数一般不用,收敛不了了。Tanh(x),没解决梯度消失的问题。
ReLu Max(0,x),比较好,代表Max门单元,解决了梯度消失的问题,而且起到了降维
权重初始化,可以随机也可以一开始设置一定的图形分布,用高斯初始化
3、层数
越多,灵敏度越好,收敛地更好,激活函数也越多,曲线的性能也更好
但是,神经元过拟合,并且计算量较大层数越多。在节点多的情况下一般会考虑:Drop-out
节点太多也不好,所以需要删除一些无效的节点
但是去掉节点,这里却是随机的,随机去掉(30%-60%)的节点
注意:随机的选择,去掉一些节点。但是drop-out也不一定是避免过拟合
很常见。一般不drop-out一定会过拟合,有drop-out概率低一些
4、过拟合
上面的drop-out就算一种。其他过拟合可能也会使用:BN,batch normalization(归一化)
在caffe操作时候,模型训练中如何解决过拟合现象?
看到验证集的数据趋于平稳,譬如第1000次之后,验证集的loss平稳了,那么就截取1000次,把学习率降低为原来的0.1,拿来第10000次结果,修改文件,继续训练。
.
5、Loss设计与观察
一般来说分类就是Softmax, 回归就是L2的loss. 但是要注意loss的错误范围(主要是回归), 你预测一个label是10000的值, 模型输出0, 你算算这loss多大, 这还是单变量的情况下. 一般结果都是nan. 所以不仅仅输入要做normalization, 输出也要。
准确率虽然是评测指标, 但是训练过程中还是要注意loss的. 你会发现有些情况下, 准确率是突变的, 原来一直是0, 可能保持上千迭代, 然后突然变1. 要是因为这个你提前中断训练了, 只有老天替你惋惜了. 而loss是不会有这么诡异的情况发生的, 毕竟优化目标是loss.
对比训练集和验证集的loss。 判断过拟合, 训练是否足够, 是否需要early stop的依据
.
6、初始化
一次惨痛的教训是用normal初始化cnn的参数,最后acc只能到70%多,仅仅改成xavier,acc可以到98%。还有一次给word embedding初始化,最开始使用了TensorFlow中默认的initializer(即glorot_uniform_initializer,也就是大家经常说的无脑使用xavier),训练速度慢不说,结果也不好。改为uniform,训练速度飙升,结果也飙升。所以,初始化就跟黑科技一样,用对了超参都不用调;没用对,跑出来的结果就跟模型有bug一样不忍直视。
经验来源:https://www.zhihu.com/question/25097993/answer/153674495
.
7、weight decay(权值衰减)
的使用既不是为了提高你所说的收敛精确度也不是为了提高收敛速度,其最终目的是防止过拟合。在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就大。
.
8、momentum
是梯度下降法中一种常用的加速技术。
即momentum系数,通俗的理解上面式子就是,如果上一次的momentum与这一次的负梯度方向是相同的,那这次下降的幅度就会加大,所以这样做能够达到加速收敛的过程
.
9、训练时间 Early stopping
对于每个神经元而言,其激活函数在不同区间的性能是不同的:
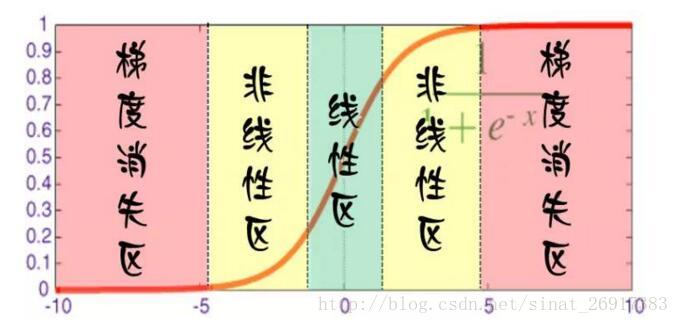
当网络权值较小时,神经元的激活函数工作在线性区,此时神经元的拟合能力较弱(类似线性神经元)。
有了上述共识之后,我们就可以解释为什么限制训练时间(early stopping)有用:因为我们在初始化网络的时候一般都是初始为较小的权值。训练时间越长,部分网络权值可能越大。如果我们在合适时间停止训练,就可以将网络的能力限制在一定范围内。
.
10、增加噪声 Noise
给网络加噪声也有很多方法:
在输入中加噪声:噪声会随着网络传播,按照权值的平方放大,并传播到输出层,对误差 Cost 产生影响。
在权值上加噪声:在初始化网络的时候,用 0 均值的高斯分布作为初始化。Alex Graves 的手写识别 RNN 就是用了这个方法
对网络的响应加噪声:如在前向传播过程中,让默写神经元的输出变为 binary 或 random。显然,这种有点乱来的做法会打乱网络的训练过程,让训练更慢,但据 Hinton 说,在测试集上效果会有显著提升 (But it does significantly better on the test set!)。
二、caffe训练时Loss变为nan的原因
本节转载于公众号平台:极市平台
1、梯度爆炸
原因:梯度变得非常大,使得学习过程难以继续
现象:观察log,注意每一轮迭代后的loss。loss随着每轮迭代越来越大,最终超过了浮点型表示的范围,就变成了NaN。
措施:
1. 减小solver.prototxt中的base_lr,至少减小一个数量级。如果有多个loss layer,需要找出哪个损失层导致了梯度爆炸,并在train_val.prototxt中减小该层的loss_weight,而非是减小通用的base_lr。
2. 设置clip gradient,用于限制过大的diff
2、不当的损失函数
原因:有时候损失层中loss的计算可能导致NaN的出现。比如,给InfogainLoss层(信息熵损失)输入没有归一化的值,使用带有bug的自定义损失层等等。
现象:观测训练产生的log时一开始并不能看到异常,loss也在逐步的降低,但突然之间NaN就出现了。
措施:看看你是否能重现这个错误,在loss layer中加入一些输出以进行调试。
示例:有一次我使用的loss归一化了batch中label错误的次数。如果某个label从未在batch中出现过,loss就会变成NaN。在这种情况下,可以用足够大的batch来尽量避免这个错误。
3、不当的输入
原因:输入中就含有NaN。
现象:每当学习的过程中碰到这个错误的输入,就会变成NaN。观察log的时候也许不能察觉任何异常,loss逐步的降低,但突然间就变成NaN了。
措施:重整你的数据集,确保训练集和验证集里面没有损坏的图片。调试中你可以使用一个简单的网络来读取输入层,有一个缺省的loss,并过一遍所有输入,如果其中有错误的输入,这个缺省的层也会产生NaN。
案例:有一次公司需要训练一个模型,把标注好的图片放在了七牛上,拉下来的时候发生了dns劫持,有一张图片被换成了淘宝的购物二维码,且这个二维码格式与原图的格式不符合,因此成为了一张“损坏”图片。每次训练遇到这个图片的时候就会产生NaN。
良好的习惯是,你有一个检测性的网络,每次训练目标网络之前把所有的样本在这个检测性的网络里面过一遍,去掉非法值。
4、池化层中步长比核的尺寸大
如下例所示,当池化层中stride > kernel的时候会在y中产生NaN
layer {
name: "faulty_pooling"
type: "Pooling"
bottom: "x"
top: "y"
pooling_param {
pool: AVE
stride: 5
kernel: 3
}
}http://stackoverflow.com/questions/33962226/common-causes-of-NaNs-during-training
.
.
三、一些训练时候出现的问题
本节转载于公众号深度学习大讲堂,文章《caffe代码夜话1》
1、为啥label需要从0开始?
在使用SoftmaxLoss层作为损失函数层的单标签分类问题中,label要求从零开始,例如1000类的ImageNet分类任务,label的范围是0~999。这个限制来自于Caffe的一个实现机制,label会直接作为数组的下标使用,具体代码SoftmaxLoss.cpp中133行和139行的实现代码。
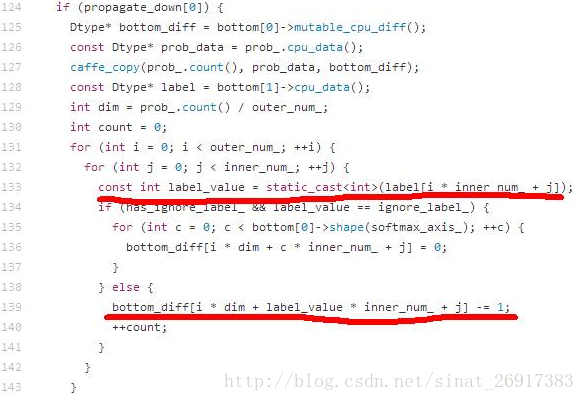
132行第一层for循环中的outer_num等于batch size,对于人脸识别和图像分类等单标签分类任务而言,inner_num等于1。如果label从1开始,会导致bottom_diff数组访问越界。
.
2、为什么Caffe中引入了这个inner_num,inner_num等于什么
从FCN全卷积网络的方向去思考。FCN中label标签长度=图片尺寸
caffe引入inner_num使得输入image的size可以是任意大小,innuer_num大小即为softmax层输入的height*width
.
3、在标签正确的前提下,如果倒数第一个全连接层num_output > 实际的类别数,Caffe的训练是否会报错?
不会报错且无影响
.
4、BN中的use_global_status
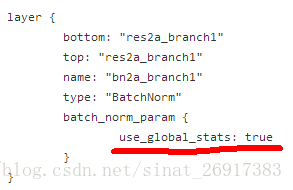
图2. ResNet部署阶模型Proto文件片段
但是如果直接拿这个Proto用于训练(基于随机初始化),则会导致模型不收敛,原因在于在Caffe的batch_norm_layer.cpp实现中,use_global_stats==true时会强制使用模型中存储的BatchNorm层均值与方差参数,而非基于当前batch内计算均值和方差。
首先看use_global_stats变量是如何计算的:
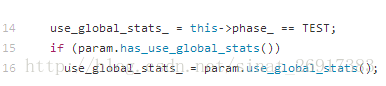
图3. use_global_stats计算
再看这个变量的作用:

图4. use_global_stats为true时的行为
以下代码在use_global_stats为false的时候通过moving average策略计算模型中最终存储的均值和方差:

图5. BatchNorm层均值和方差的moving average
因此,对于随机初始化训练BatchNorm层,只需要在Proto文件中移除use_global_stats参数即可,Caffe会根据当前的Phase(TRAIN或者TEST)自动去设置use_global_stats的值。
.
5、BatchNorm层是否支持in place运算,为什么?
BN是对输入那一层做归一化操作,要对每个元素-均值/标准差,且输入输出规格相当,是可以进行in place。
标准的ReLU函数为max(x, 0),而一般为当x > 0时输出x,但x <= 0时输出negative_slope。RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
.
.
四、过拟合解决:dropout、batch Normalization
来源于:https://github.com/exacity/deeplearningbook-chinese/releases/
1、dropout——另类Bagging(类似随机森林RF)
引用自Dropout作者:
在标准神经网络中,每个参数接收的导数表明其应该如何变化才能使最终损失函数降低,并给定所有其它神经网络单元的状态。因此神经单元可能以一种可以修正其它神经网络单元的错误的方式进行改变。而这就可能导致复杂的共适应(co-adaptations)。由于这些共适应现象没有推广到未见的数据,将导致过拟合。我们假设对每个隐藏层的神经网络单元,Dropout通过使其它隐藏层神经网络单元不可靠从而阻止了共适应的发生。因此,一个隐藏层神经元不能依赖其它特定神经元去纠正其错误。(来源:赛尔译文 Dropout分析)
Dropout可以被认为是集成非常多的大神经 网络的实用Bagging方法。当每个模型是一个大型神经网络时,这似乎是不切实际的,因为训练和 评估这样的网络需要花费很多运行时间和内存。
Dropout提供了一种廉价的Bagging集成近似,能够训练和评估指数级的神经网络。
操作方法:将一些单元的输出乘零就能有效地删除一个单元。
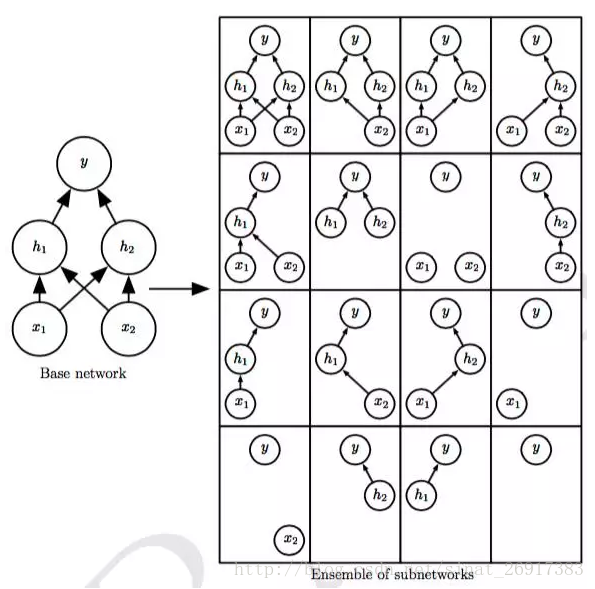
(1)具体工作过程:
Dropout以概率p关闭神经元,相应的,以大小为q=1-p的概率开启其他神经元。每个单个神经元有同等概率被关闭。当一个神经元被丢弃时,无论其输入及相关的学习参数是多少,其输出都会被置为0。
丢弃的神经元在训练阶段的前向传播和后向传播阶段都不起作用:因为这个原因,每当一个单一的神经元被丢弃时,训练阶段就好像是在一个新的神经网络上完成。
训练阶段,可以使用伯努利随机变量、二项式随机变量来对一组神经元上的Dropout进行建模。
(来源:赛尔译文 Dropout分析)
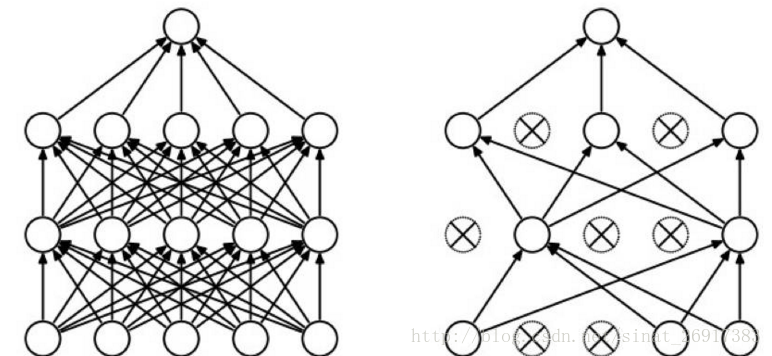
(2)dropout类型:
正向dropout、反向dropout。
反向Dropout有助于只定义一次模型并且只改变了一个参数(保持/丢弃概率)以使用同一模型进行训练和测试。相反,直接Dropout,迫使你在测试阶段修改网络。因为如果你不乘以比例因子q,神经网络的输出将产生更高的相对于连续神经元所期望的值(因此神经元可能饱和):这就是为什么反向Dropout是更加常见的实现方式。
(3)dropout与其他规则
故反向Dropout应该与限制参数值的其他归一化技术一起使用,以便简化学习速率选择过程
正向Dropout:通常与L2正则化和其它参数约束技术(如Max Norm1)一起使用。正则化有助于保持模型参数值在可控范围内增长。
反向Dropout:学习速率被缩放至q的因子,我们将其称q为推动因子(boosting factor),因为它推动了学习速率。此外,我们将r(q)称为有效学习速率(effective learning rate)。总之,有效学习速率相对于所选择的学习速率更高:由于这个原因,限制参数值的正则化可以帮助简化学习速率选择过程。
(来源:赛尔译文 Dropout分析)
(4)优势:
看作是对输入内容的信息高度智能化、自适应破坏的一种形式,而不是 对输入原始值的破坏。
Dropout不仅仅是训练一个Bagging的集成模型,并且是共享隐藏单元的集成模型。这意味着无论其他隐藏单元是否在模型中,每个隐藏单元必须都能够表现良好。隐藏单元必须准备好进行模型之间的交换和互换。
计算方便是Dropout的一个优点。训练过程中使用Dropout产生 n 个随机二进制 数与状态相乘,每个样本每次更新只需 O(n)的计算复杂度。
Dropout的另一个显著优点是不怎么限制适用的模型或训练过程。几乎在所有 使用分布式表示且可以用随机梯度下降训练的模型上都表现很好。包括前馈神经网 络、概率模型,如受限玻尔兹曼机(Srivastava et al., 2014),以及循环神经网络(Bayer and Osendorfer, 2014; Pascanu et al., 2014a)。许多其他差不多强大正则化策略对模 型结构的限制更严格。
(5)劣势:
Dropout是一个正则化技术,它减少了模型的有效容量。为了抵消这种影响,我们必须增大模型规模。不出意外的话,使 用Dropout时最佳验证集的误差会低很多,但这是以更大的模型和更多训练算法的迭
代次数为代价换来的。对于非常大的数据集,正则化带来的泛化误差减少得很小。在
这些情况下,使用Dropout和更大模型的计算代价可能超过正则化带来的好处。只有极少的训练样本可用时,Dropout不会很有效。在只有不到 5000 的样本 的Alternative Splicing数据集上 (Xiong et al., 2011),贝叶斯神经网络 (Neal, 1996)比Dropout表现更好
(Srivastava et al., 2014)。当有其他未分类的数据可用时,无监 督特征学习比Dropout更有优势。
.
2、batch Normalization
batch normalization的主要目的是改善优化,但噪音具有正则化的效果,有时使Dropout变得没有必要。
参数训练过程中多层之间协调更新的问题:在其他层不改变的假设下,梯度用于如何更新每一个参数。但是,一般情况下会同时更新所有层。 这造成了很难选择一个合适的学习速率,因为某一层中参数更新的效果很大程度上取决 于其他所有层。
batch normalization可应用于网络 的任何输入层或隐藏层。设 H 是需要标准化的某层的minibatch激励函数,布置为 设计矩阵,每个样本的激励出现在矩阵的每一行中。标准化 H,我们替代它为
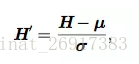
其中 μ 是包含每个单元均值的向量,σ 是包含每个单元标准差的向量。
反向传播这些操作,计算均值和标准差,并应用它们于标准化 H。这意味着,梯度不会再简单地增加 hi 的标准差或均值;标准化操作会 除掉这一操作的影响,归零其在梯度中的元素。
以前的方法添加代价函数的惩罚,以鼓励单位标准化激励统计量,或是 在每个梯度下降步骤之后重新标准化单位统计量。
前者通常会导致不完全的标准化, 而后者通常会显著地消耗时间,因为学习算法会反复改变均值和方差而标准化步骤 会反复抵消这种变化。
batch normalization重新参数化模型,以使一些单元总是被定 义标准化,巧妙地回避了这两个问题。
.
延伸一:Check failed: error == cudaSuccess (2 vs. 0) out of memory
参考博客:【caffe跑试验遇到错误:Check failed: error == cudaSuccess (2 vs. 0) out of memory】
明显是内存不够, nvidia-smi/watch -n 0.1 nvidia-smi实时查看
发现有top命令无法查看到的进程,将这些进程杀死掉,释放内存:
杀死进程命令:kill -9 PID
最后重新运行试验,就可以开始跑了,最后我终于知道为什么了:
top是监视CPU的,而 nvidia-smi才是监视GPU的。
.
延伸二:softmax出现的问题与解决
caffe中softmax层有两种方式:softmax和SoftmaxWithLoss。本节内容来源:Caffe 训练时loss等于87.33的原因及解决方法
layers {
name: "prob"
type: “Softmax"
bottom: " ip2"
top: "prob"
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}softmax,name=top名称,bottom为上一层的names。
softmax计算:
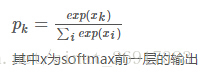
softmax中Loss的计算:
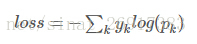
softmax层会出现的报错:
softmax是用指数函数计算的,指数函数的值都是大于零的。因此,我们有理由相信,计算过程中出现了float溢出等异常,出现了inf,nan等异常数值导致softmax输出为零
最后我们发现,当softmax之前的feature值过大时,由于softmax先求指数,会超出float数据范围,成为inf。inf与其他任何数值的和都是inf,softmax在做除法时任何正常范围的数值除以inf都会变为0。然后求loss时log一下就出现了87.3356这样的值。
softmax的解决方案:
1、观察数据中是否有异常样本或异常label导致数据读取异常
2、调小初始化权重,以便使softmax输入的feature尽可能变小
3、降低学习率,这样就能减小权重参数的波动范围,从而减小权重变大的可能性。这条也是网上出现较多的方法。
4、如果有BN(batch normalization)层,finetune时最好不要冻结BN的参数,否则数据分布不一致时很容易使输出值变的很大。
.
延伸三:caffe中layer与layers的差别
报错:
Manually switch the definition to 'layer' format to continue.来源layer与layers是有差别的,来看看:
#layers层的type需要大写,且没有引号
layers {
bottom: "fc8"
top: "prob"
name: "prob"
type: SOFTMAX
}
#layer层的type带引号,且小写
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}同样一个输出softmax层,为啥呢?网上问答:
之前在caffe里下载的caffemodel的prototxt网络构造,里面的构架是用layer写的。后来想试一下VGGnet等高端构架,网上下载到的居然是layers模式的,坑了我好久,才找到错误根源,原来是layers的参数跟layer有所差异。
caffe利用google开发的proto工具对自己的prototxt文件进行解析,解析过后生成cpp或者py的代码。所以虽然layers和layer的构造不同,其实就是参数的大小写名字之类的有所差异,但是最后有用的代码是一样的。尽管如此,我们在同一个prototxt文件中只能使用一种格式,不能layer和layers混用。但是呢,deploy.prototxt和train_val.prototxt之间是可以不同的。
在layer版本deploy中输入数据的格式为:“Input”,这个是有讲究的,跟训练的数据type不同,因为训练时用的“Data”,他们的主要差异在于,Data是有label的,而Input就是输入数据而已,很单纯,也就是他们的blobs维数不同,因此在deploy.prototxt中要用Input。我找了半天没有找到在layers层中Input应该替换为什么类型的type,因此我的deploy还是使用的layer结构,不过能够正常运行。
延伸四:深度学习中.jpg图像读取失败原因
笔者在导入.jpg会出现两种情况:
- 1、.jpg导入不了,报错truncated;
- 2、图片尤其是png.(虽然后缀是jpg)格式的图片会出现,无法转换为np.array
情况一(参考链接):
ValueError: Could not load ""
Reason: "image file is truncated (2 bytes not processed)"笔者在使用caffe时候,出现以上报错,明明是一个好的jpg图像,为啥读不进去呢?
这时候就需要额外导入以下代码:
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True情况二:(参考链接)
libpng error: Read Error以上的解决方法:
import cv2, random
import os
import numpy as np
from PIL import Image
from PIL import ImageFile
import imghdr
ImageFile.LOAD_TRUNCATED_IMAGES = True
if imghdr.what(name) == "png":
Image.open(name).convert("RGB").save(name)
img = cv2.imread(name)
img = np.array(Image.open(name))转换一下格式为RGB
.
延伸五:caffe_pb2.NetParameter网络层打印
# load MS COCO model specs
file = open(caffe_root + 'models/VGGNet/coco/SSD_512x512/deploy.prototxt', 'r')
coco_netspec = caffe_pb2.NetParameter()
text_format.Merge(str(file.read()), coco_netspec)根据NetParameter打印网络结构,用于保存deploy和train_test的网络结构。
import google.protobuf
def print_network(prototxt_filename, caffemodel_filename):
'''''
Draw the ANN architecture
'''
_net = caffe.proto.caffe_pb2.NetParameter()
f = open(prototxt_filename)
google.protobuf.text_format.Merge(f.read(), _net)
caffe.draw.draw_net_to_file(_net, prototxt_filename + '.png' )
print('Draw ANN done!')
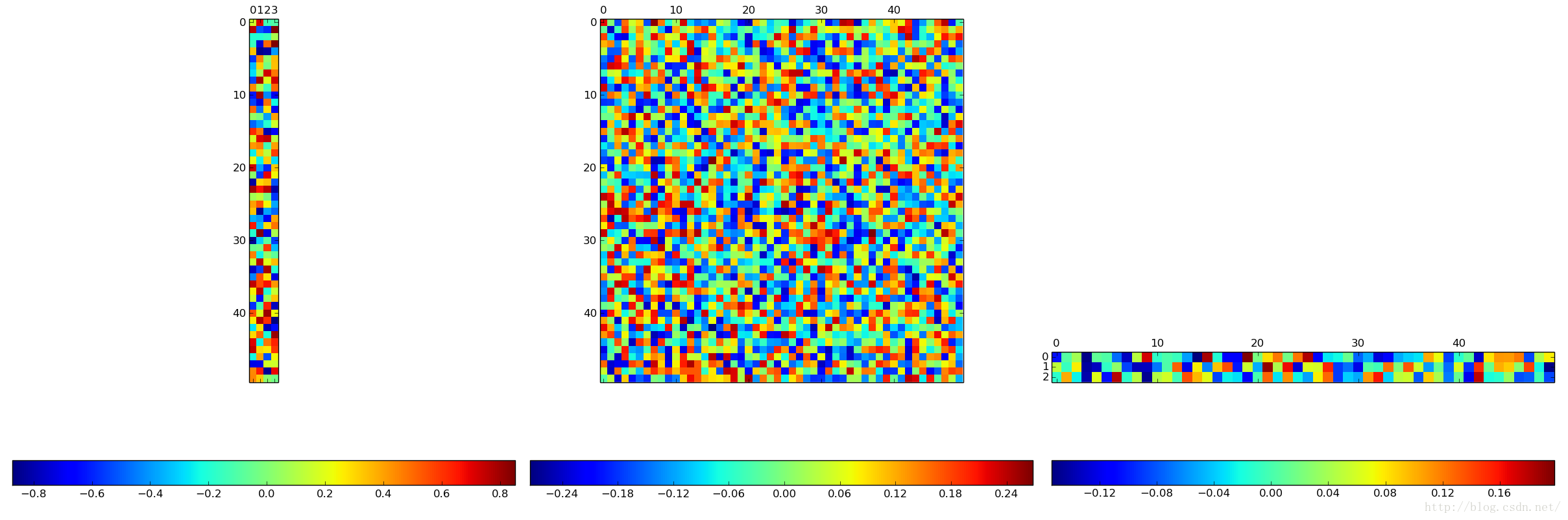
打印网络权重时用的是train_test.prototxt,用deploy.prototxt也行。绘制的网络结构图中的data和loss层为蓝色矩形块,而ip1~ip3为灰色八边形块。因为data层的输出和loss层的输出为不带权重的真实值,所以它俩在即使在net.params中,各自的所有权重也是相同的。实验保存的图片中没有xxx_weights_xx_data/loss.png也验证了这一点。heatmap反映了某网络中间层的输入节点和输出节点之间的权重,而histogram反映同一层网络中间层的权重值的分布。
.
延伸六:如何成为一名成功的“炼丹师”——DL训练技巧
来源: 计算机视觉战队
今天给大家讲讲DNN(深度神经网络)在训练过程中遇到的一些问题,然后我们应该怎么去注意它,并学会怎么去训练它。
1、数据集的准备:
必须要保证大量、高质量且带有准确标签的数据,没有该条件的数据,训练学习很困难的(但是最近我看了以为作者写的一篇文章,说明不一定需要大量数据集,也可以训练的很好,有空和大家来分享其思想—很厉害的想法);
2、数据预处理:
这个不多说,就是0均值和1方差化,其实还有很多方法;
3、Minibatch:
这个有时候还要根据你的硬件设备而定,一般建议用128,8这组,但是128,1也很好,只是效率会非常慢,注意的是:千万不要用过大的数值,否则很容易过拟合;
4、梯度归一化:
其实就是计算出来梯度之后,要除以Minibatch的数量,这个可以通过阅读源码得知(我之前有写过SGD);
5、学习率:
① 一般都会有默认的学习率,但是刚开始还是用一般的去学习,然后逐渐的减小它;
② 一个建议值是0.1,适用于很多NN的问题,一般倾向于小一点;但是如果对于的大数据,何凯明老师也说过,要把学习率调到很小,他说0.00001都不为过(如果记得不错,应该是这么说的);
③ 一个对于调度学习率的建议:如果在验证集上性能不再增加就让学习率除以2或者5,然后继续,学习率会一直变得很小,到最后就可以停止训练了;
④ 很多人用的一个设计学习率的原则就是监测一个比率(每次更新梯度的norm除以当前weight的norm),如果这个比率在10e-3附近,且小于这个值,学习会很慢,如果大于这个值,那么学习很不稳定,由此会带来学习失败。
6、验证集的使用:
使用验证集,可以知道什么时候开始降低学习率和什么时候停止训练;
7、weight初始化:
① 如果你不想繁琐的话,直接用0.02*randn(num_params)来初始化,当然别的值也可以去尝试;
② 如果上面那个建议不太好使,那么就依次初始化每一个weight矩阵用init_scale / sqrt(layer_width) * randn,init_scale可以被设置为0.1或者1;
③ 初始化参数对结果的影响至关重要,要引起重视;
④ 在深度网络中,随机初始化权重,使用SGD的话一般处理的都不好,这是因为初始化的权重太小了。这种情况下对于浅层网络有效,但是当足够深的时候就不行,因为weight更新的时候,是靠很多weight相乘的,越乘越小,类似梯度消失的意思。
8、RNN&&LSTM(这方面没有深入了解,借用别人的意思):
如果训练RNN或者LSTM,务必保证gradient的norm被约束在15或者5(前提还是要先归一化gradient),这一点在RNN和LSTM中很重要;
9、梯度检查:
检查下梯度,如果是你自己计算的梯度;如果使用LSTM来解决长时依赖的问题,记得初始化bias的时候要大一点;
10、数据增广:
尽可能想办法多的扩增训练数据,如果使用的是图像数据,不妨对图像做一点扭转,剪切,分割等操作来扩充数据训练集合;
11、dropout:(先空着,下次我要单独详细讲解Dropout)
12、评价结果:
评价最终结果的时候,多做几次,然后平均一下他们的结果。
补充:
1、选择优化算法
传统的随机梯度下降算法虽然适用很广,但并不高效,最近出现很多更灵活的优化算法,例如Adagrad、RMSProp等,可在迭代优化的过程中自适应的调节学习速率等超参数,效果更佳;
2、参数设置技巧
无论是多核CPU还是GPU加速,内存管理仍然以字节为基本单元做硬件优化,因此将参数设定为2的指数倍,如64,128,512,1024等,将有效提高矩阵分片、张量计算等操作的硬件处理效率;
3、正则优化 (通过L1 norm和L2 norm强制地让模型学习到比较小的权值。)
除了在神经网络单元上添加传统的L1/L2正则项外,Dropout更经常在深度神经网络应用来避免模型的过拟合。初始默认的0.5的丢弃率是保守的选择,如果模型不是很复杂,设置为0.2就可以;
4、其他方法
除了上述训练调优的方法外,还有其他一些常用方法,包括:使用mini-batch learning方法、迁移训练学习、打乱训练集顺序、对比训练误差和测试误差调节迭代次数、日志可视化观察等等。
weight penality(L1&L2)的工作原理:
weight decay通过L1 norm和L2 norm强制地让模型学习到比较小的权值。
这里有两个问题:
(1)为什么L1和L2 norm能够学习到比较小的权值?
——w明显减少得更多。L1是以减法形式影响w,而L2则是以乘法形式影响w,因此L2又称为weight decay。
(2)为什么比较小的权值能够防止过拟合?
——过拟合的本质是什么呢?无非就是对于非本质特征的噪声过于敏感,把训练样本里的噪声当作了特征,以至于在测试集上的表现非常稀烂。当权值比较小时,当输入有轻微的改动(噪声)时,结果所受到的影响也比较小,所以惩罚项能在一定程度上防止过拟合。
.
延伸七:增加模型的多样性
参考:米少熬好粥—数据有限时怎样调优深度学习模型
1、试试不断调整隐层单元和数量
调模型,要有点靠天吃饭的宽容心态,没事就调调隐层单元和数量,省的GPU闲着,总有一款适合你。
一般来说,隐层单元数量多少决定了模型是否欠拟合或过拟合,两害相权取其轻,尽量选择更多的隐层单元,因为可以通过正则化的方法避免过拟合。与此类似的,尽可能的添加隐层数量,直到测试误差不再改变为止。
2、试试两个模型或者多个模型concat
比如,两种不同分辨率的图像数据集,分别训练出网络模型a和网络模型b,那么将a和b的瓶颈层concat在一起,用一个全连接层(或者随便你怎么连,试着玩玩没坏处)连起来,,输入concat后的图片,训练结果可能比单个网络模型效果要好很多哦。
loss函数那些事儿
这里只从模型调优的tric角度来介绍下。
Softmax-loss算是最常用的loss方法了,但是Softmax-loss不会适用于所有问题。比如在数据量不足够大的情况下,softmax训练出来的人脸模型性能差,ECCV 2016有篇文章(A Discriminative Feature Learning Approach for Deep Face Recognition)提出了权衡的解决方案。通过添加center loss使得简单的softmax就能够训练出拥有内聚性的特征。该特点在人脸识别上尤为重要,从而使得在很少的数据情况下训练出来的模型也能有很好的作用。此外,contrastive-loss和triplet-loss也有其各自的好处,需要采样过程,有兴趣的可以多了解下。
花式调优
1、batch size设置
batch size一般设定为2的指数倍,如64,128,512等,因为无论是多核CPU还是GPU加速,内存管理仍然以字节为基本单元做硬件优化,2的倍数设置将有效提高矩阵分片、张量计算等操作的硬件处理效率。
不同batch size的模型可能会带来意想不到的准确率提升,这个调节其实是有一定规律和技巧的。
2、激励函数
激励函数为模型引入必要的非线性因素。Sigmoid函数由于其可微分的性质是传统神经网络的最佳选择,但在深层网络中会引入梯度消失和非零点中心问题。Tanh函数可避免非零点中心问题。ReLU激励函数很受欢迎,它更容易学习优化。因为其分段线性性质,导致其前传,后传,求导都是分段线性,而传统的sigmoid函数,由于两端饱和,在传播过程中容易丢弃信息。ReLU激励函数缺点是不能用Gradient-Based方法。同时如果de-active了,容易无法再次active。不过有办法解决,使用maxout激励函数。
3、权重初始化
权重初始化常采用随机生成方法以避免网络单元的对称性,但仍过于太过粗糙,根据目前最新的实验结果,权重的均匀分布初始化是一个最优的选择,同时均匀分布的函数范围由单元的连接数确定,即越多连接权重相对越小。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









