






 本文介绍了Transformer模型中如何通过位置编码解决因缺乏词位置顺序信息的问题,详细解释了位置编码的原理、计算方法,并提供了PyTorch实现代码。重点展示了如何使用位置索引和编码维度生成位置嵌入矩阵。
本文介绍了Transformer模型中如何通过位置编码解决因缺乏词位置顺序信息的问题,详细解释了位置编码的原理、计算方法,并提供了PyTorch实现代码。重点展示了如何使用位置索引和编码维度生成位置嵌入矩阵。
在处理自然语言时候,因Transformer是基于注意力机制,不像RNN有词位置顺序信息,故需要加入词的位置信息来显示的表明词的上下文关系。具体是将词经过位置编码(positional encoding),然后与emb词向量求和,作为编码块(Encoder block)的输入信息。在《Attention Is All You Need》论文中,位置编码信息如下:

其中PE的维度为:[序列长度,编码维度](即[seq_len,emb_dim])
pos表示词语在句子中的位置
表示编码(emb)的维度
i表示词向量的位置,偶数位置用sin,奇数位置用cos
据此,即可根据不同的pos信息和i信息得到不同的位置嵌入信息。具体计算时候,由于sin和cos后半部分相同,采用log将次方拿下,方便计算。

具体Pytorch代码实现如下
# coding=utf8
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import math
def get_position_encoding(seq_len, emb_dim):
pe = torch.zeros(seq_len, emb_dim)
pos = torch.arange(0, seq_len, dtype=torch.float)
pos = pos.unsqueeze(1)
locpos = torch.arange(0, emb_dim, 2).float()
div_term = torch.exp(locpos * (-math.log(10000.0) / emb_dim)) #对应上面公式最后一行
# 第一维度序列长度,第二维度编码
pe[:, 0::2] = torch.sin(pos * div_term)
pe[:, 1::2] = torch.cos(pos * div_term)
return pe
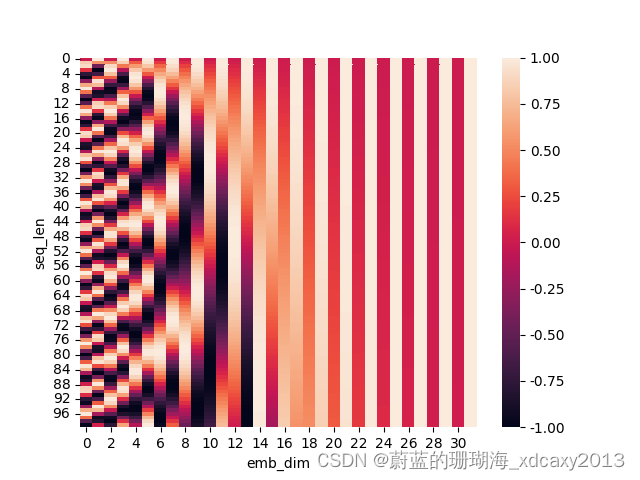
pe = get_position_encoding(100, 32)
sns.heatmap(pe)
plt.xlabel('emb_dim')
plt.ylabel('seq_len')
plt.show()生成图如下:
补充知识点:
切片,位置编码赋值:
def clip_pos(x):
xdata = torch.arange(1, x, 1)
print("###xdata:###", xdata)
"""
切片的语法使用冒号(:)来表示,形式为`[start:end:step]`,其中start表示起始索引(包含),end表示结束索引(不包含),step表示步长(默认为1)。
如果省略start,则默认从序列的第一个元素开始
如果省略end,则默认截取到序列的最后一个元素
如果省略step,则默认以步长为1进行截取
"""
# print(xdata[0::2])
print(xdata[0:4:2])
print(xdata[1::2])














 3476
3476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









