






 这篇学习笔记详细介绍了RNN和LSTM的工作原理。RNN因其在处理序列数据时的特性而受到关注,但也存在梯度消失和遗忘问题。LSTM通过细胞状态解决了长期依赖问题,能更好地保留信息。笔记涵盖了RNN的前向传导和反向传播,以及LSTM的基本结构和优势。
这篇学习笔记详细介绍了RNN和LSTM的工作原理。RNN因其在处理序列数据时的特性而受到关注,但也存在梯度消失和遗忘问题。LSTM通过细胞状态解决了长期依赖问题,能更好地保留信息。笔记涵盖了RNN的前向传导和反向传播,以及LSTM的基本结构和优势。
学习笔记:RNN与LSTM
记录一下学习进度吧。
RNN
Recurrent Neural Network偏重于数据时序上的处理,是一个链式的结构。由于RNN中存在时间上的信息,就可以根据之前出现的信息对当前的信息进行推断,链式的特征揭示了 RNN 本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。这可能就是它最大的优势吧。
但是类似于梯度衰减和梯度爆炸,但信息相隔时间过晚,会存在信息遗忘的情况,无法体现优势。

RNN前向传导公式示意
可见前向传导的公式需要记住的状态,仅是多了几个 st s t 。
RNN反向传播
关于v的反向
就是反向传播,和普通的神经网络没有差异
关于w的反向
可见w的反向也是反向传播,但是是多个梯度的累加和。
代码实现起来应该还算行吧,只是需要记住每一个状态(虽然目前正在学习,还没有自己实现过)。
关于U的求导
其实从展开图看来,U的求导可能也和W一样,存在多个更新路径,但是由于数据保留的可能必要性看来,只进行了当前状态的更新。和普通的前向传播一样。
LSTM
正如前面介绍的梯度消失和梯度爆炸的问题,当间隔时间过大,有些信息是长期依赖(Long-Term Dependencies)的,而RNN不能很好的解决这个问题,便有了LSTM。
观察如下RNN结构

在重复的结构之中,只有一个简单的激活函数,得到新的状态量
st
s
t
。
观察如下的LSTM的结构,其中最主要的是最上面的一条水平线,在图中贯穿,叫做细胞状态,由于其只有少量的信息交互,故能够保证信息较小的变化,保持长久的记忆。
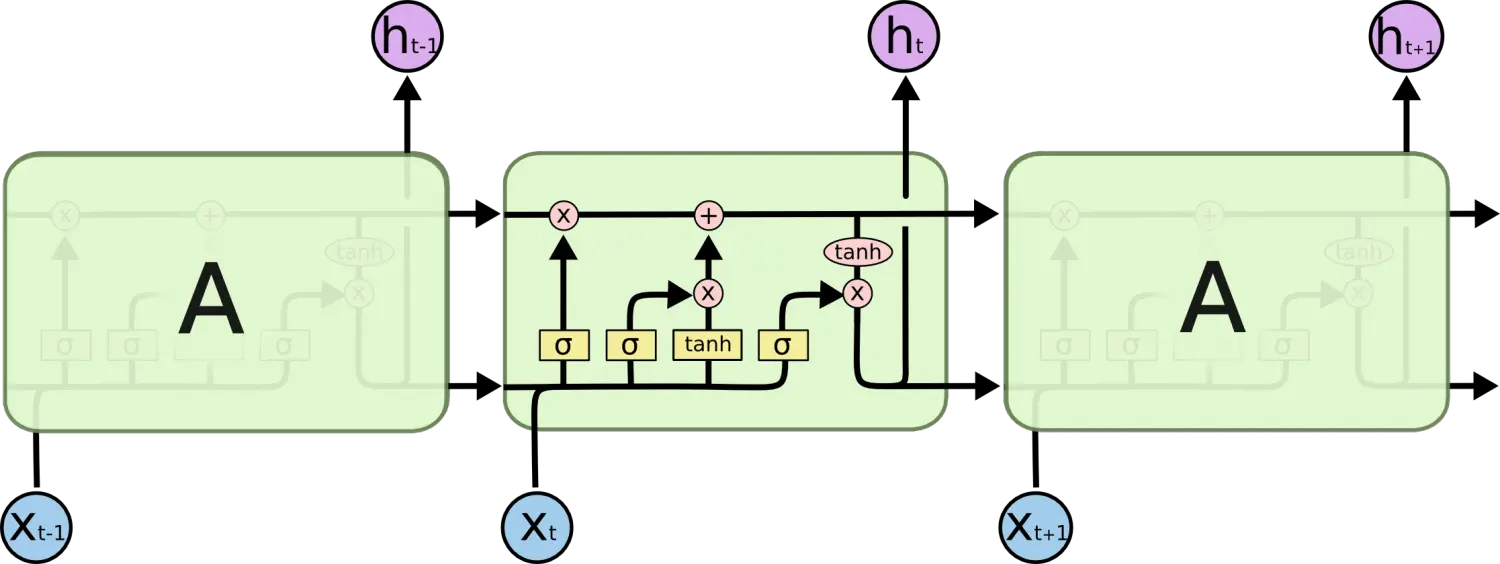

如下是对其中
σ
σ
、
tanh
t
a
n
h
和两个pointwise_operation的理解:
- σ σ 函数类似于权重, 决定什么值我们将要更新,sigmoid函数能够归一化0-1,这样便能达到一个选择性通过的目的。
- 一个 tanh 层创建一个新的候选值向量,通过一个非线性操作,产生一个类似于状态的变量。
- pointwise_operation是一种对于状态的操作,比如选择通过来丢弃某些信息、更新细胞状态来加入当前信息、从细胞状态得到输出变量。
关于LSTM的更新求导,下次加上。
结论
- rnn考虑以往的序列信息,加入了先前知识。比以往的神经网络而言,似乎更接近人的学习过程。
- LSTM通过一个细胞状态的主线过程,保证了长期记忆不会很快的衰减,然后根据每一次的状态和输入更新主线的细胞状态。通过改善结构,来达到目的。















 1072
1072

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









