






1. 简介
(Long Short-Term Memory)LSTM是一种长短期记忆网络,是一种特殊的RNN , LSTM更加适用于处理和预测时间序列中间隔较长的重要事件,并在一定程度上缓解了梯度消失
2. 门控单元
一个LSTM块中有3个门控单元,分别是输出门,输入门,遗忘门
那么门控记忆单元又是什么呢?
在LSTM中引入了记忆细胞(memory cell,记忆单元也行),用于存储网络中的一些信息,门控单元就相当于我们平常生活中的门,决定了数据合适进来?以什么方式进来?需不需要遗忘某一部分的数据?
下面我们就来解释上面提到的各个门
2.1 遗忘门
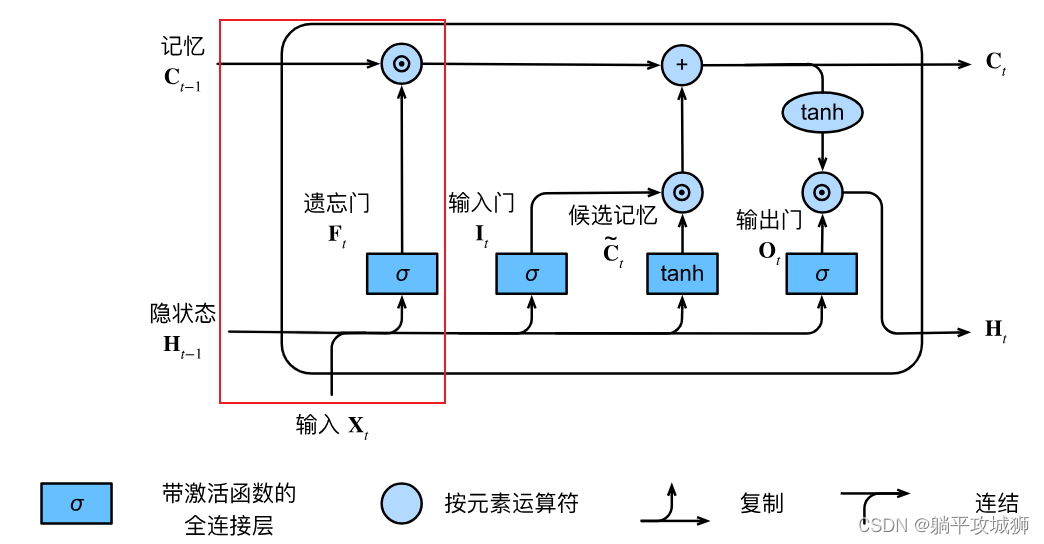 上图所圈的部分即是遗忘门的逻辑,对应的公式如下
F
t
=
σ
(
X
t
W
x
f
+
H
t
−
1
W
h
f
+
b
f
)
\mathbf{F}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f)
Ft=σ(XtWxf+Ht−1Whf+bf)即是合并了当前输入和前一时刻的隐状态通过 相乘权重加上偏置,最终通过sigmoid激活函数输出结果,通过此门可以计算出一个0~1之前的遗忘值,用于后面决定前序记忆的遗忘程度
上图所圈的部分即是遗忘门的逻辑,对应的公式如下
F
t
=
σ
(
X
t
W
x
f
+
H
t
−
1
W
h
f
+
b
f
)
\mathbf{F}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xf} + \mathbf{H}_{t-1} \mathbf{W}_{hf} + \mathbf{b}_f)
Ft=σ(XtWxf+Ht−1Whf+bf)即是合并了当前输入和前一时刻的隐状态通过 相乘权重加上偏置,最终通过sigmoid激活函数输出结果,通过此门可以计算出一个0~1之前的遗忘值,用于后面决定前序记忆的遗忘程度
2.2 输入门
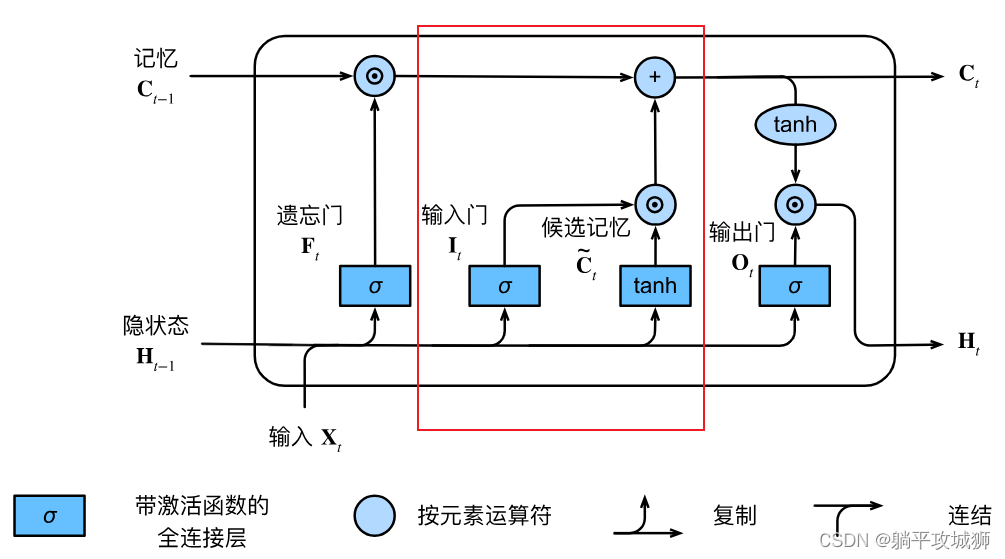
从上图中我们可以看到,输入门部分包含两种逻辑,决定了我当前时刻需要学多少新的知识。公式如下
I
t
=
σ
(
X
t
W
x
i
+
H
t
−
1
W
h
i
+
b
i
)
\mathbf{I}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xi} + \mathbf{H}_{t-1} \mathbf{W}_{hi} + \mathbf{b}_i)
It=σ(XtWxi+Ht−1Whi+bi)跟前面类似,只是权重矩阵替换成对应的,值得注意的是这些权重矩阵可以通过网络自己学习出来,所以我们只需要给他们统一初始化,像是一个三元组(
W
隐藏层
,
W
输入层
,
b
W_{隐藏层}, W_{输入层}, b
W隐藏层,W输入层,b)生成4次…
2.2.1 候选记忆
既然我们有一个输入门输入我们当前新学的数据了,为什么还需要一个候选记忆呢,感觉完全没有存在的必要?🙃
事实上不是这样的,大家不要被其误导,候选记忆的本质就是学习的新东西,而输入门才是我们用于约束我们需要多少的候选记忆加入当前的网络,上图中可以看到通过
⊙
~\odot~
⊙ 运算后生成的东东是直接加到记忆细胞中的,不是乘法!!
此时激活函数用的是tanh,同上替换相应的权重矩阵其公式如下 C ~ t = tanh ( X t W x c + H t − 1 W h c + b c ) \tilde{\mathbf{C}}_t = \text{tanh}(\mathbf{X}_t \mathbf{W}_{xc} + \mathbf{H}_{t-1} \mathbf{W}_{hc} + \mathbf{b}_c) C~t=tanh(XtWxc+Ht−1Whc+bc)
2.3 输出门
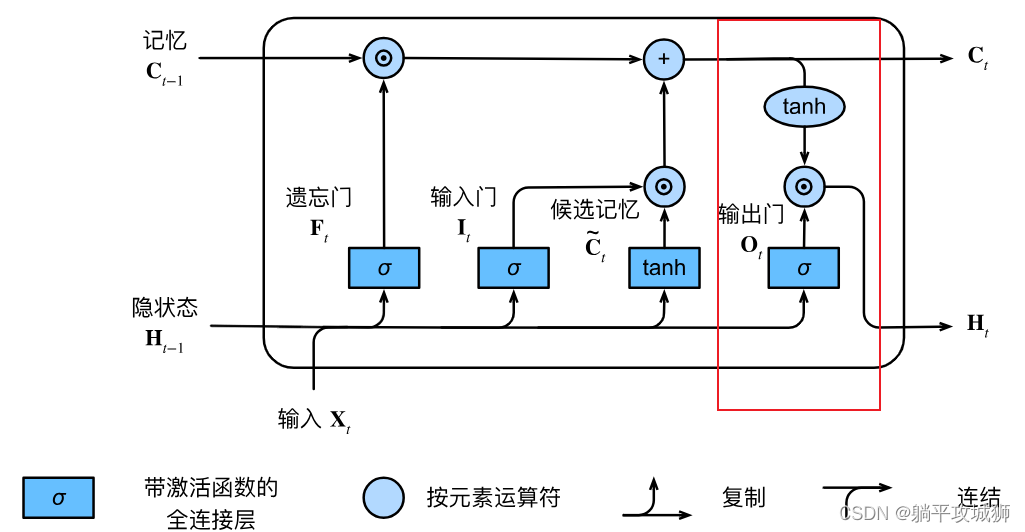 终于到最后一个门啦,输出门主要作用在当前时刻的隐状态输出上。公式如下
O
t
=
σ
(
X
t
W
x
o
+
H
t
−
1
W
h
o
+
b
o
)
\mathbf{O}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o)
Ot=σ(XtWxo+Ht−1Who+bo)这个公式就不解释了,跟前面一样的。观察上面的图我们可以看到
H
t
~H_t~
Ht t时刻的隐状态由上一时刻的记忆单元
C
t
−
1
~C_{t-1}~
Ct−1 ,上一时刻的隐状态
H
t
−
1
~H_{t-1}~
Ht−1 ,当前时刻的输入
X
i
~X_i~
Xi 三者共同决定,在讲如何计算前,我们还要多提一嘴最上面那条线代表的记忆单元如何计算
终于到最后一个门啦,输出门主要作用在当前时刻的隐状态输出上。公式如下
O
t
=
σ
(
X
t
W
x
o
+
H
t
−
1
W
h
o
+
b
o
)
\mathbf{O}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xo} + \mathbf{H}_{t-1} \mathbf{W}_{ho} + \mathbf{b}_o)
Ot=σ(XtWxo+Ht−1Who+bo)这个公式就不解释了,跟前面一样的。观察上面的图我们可以看到
H
t
~H_t~
Ht t时刻的隐状态由上一时刻的记忆单元
C
t
−
1
~C_{t-1}~
Ct−1 ,上一时刻的隐状态
H
t
−
1
~H_{t-1}~
Ht−1 ,当前时刻的输入
X
i
~X_i~
Xi 三者共同决定,在讲如何计算前,我们还要多提一嘴最上面那条线代表的记忆单元如何计算
2.3.1 t时刻记忆单元 C t \mathbf C_t Ct
根据图片我们可以得出 t 时刻的记忆单元计算公式如下 C t = C t − 1 ⊙ F t + I t ⊙ C t ~ \mathbf C_t = \mathbf C_{t-1} \odot~\mathbf F_t ~+~\mathbf I_t \odot ~\tilde{\mathbf C_t} Ct=Ct−1⊙ Ft + It⊙ Ct~即是遗忘门决定遗忘多少前时刻的记忆;输入门决定学习多少刚学习的记忆。两者之和作为当前时刻新的记忆
我们可以通过上面的式子理解一下为什么LSTM会减缓梯度消失,梯度消失本质就是在反向传播的过程中权重矩阵的连乘,而这里引入记忆细胞可以很好的减轻这里情况:
如果遗忘门为1,而输入门为0,此时上一个时刻的记忆就会原封不动的保存到下一个时刻,
那么此时为我们就可以省去反复计算的时间🤔 c t c_t ct对 c t − 1 c_{t-1} ct−1的导数跟三个门的权重有关,而这些权重又是可以自学习的,所以可以有效控制住梯度的大小,不会太大或者太小
自己的拙见,有不同理解的可以评论区call我
上面出现的 ⊙ ~\odot~ ⊙ 代表数学中的同或运算,两个操作数值相同时同或结果为真,反之为假,公式表示如下 a ⊙ b = a ∗ b + a ′ ∗ b ′ 其中 a ′ 为非 a , b ′ 为非 b a ~\odot~b = a*b + a'*b' ~~~~~~~~~~~~其中a'为非a,b'为非b a ⊙ b=a∗b+a′∗b′ 其中a′为非a,b′为非b
2.4 t时刻的隐状态 H t ~~\mathbf H_t Ht
H
t
=
t
a
n
h
(
C
t
)
⊙
O
t
\mathbf H_t = tanh(\mathbf C_t) ~\odot~\mathbf O_t
Ht=tanh(Ct) ⊙ Ot
由于有了输出门控单元
O
t
\mathbf O_t
Ot,所以这就确保了任意时刻
H
t
\mathbf H_t
Ht 的值始终在区间 (−1,1)内。
而sigmoid函数是在(0,1)之间的
- 只要输出门接近 1,我们就能够有效地将所有记忆信息传递给预测部分
- 对于输出门接近 0,我们只保留记忆元内的所有信息,而不需要更新隐状态。
3.总结
LSTM对于处理更长的时序会更加好(对比RNN),并在一定程度上缓解了梯度消失,并且除了计算时间负责一点基本没有啥缺点。最后说下一个LSTM块中包含
-
记忆细胞负责保存重要信息 -
遗忘门决定要不要遗忘记忆细胞中的信息 -
输入门决定要不要将当前输入信息写入记忆细胞 -
候选记忆学习得到的当前时刻新记忆 -
输出门决定要不要将记忆细胞的信息作为当前的隐变量输出
当然对于更长的时序还是用transformer模型来做更好
















 6502
6502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









