





对于每个从事和数据科学有关的人来说,大部分的时间都花在了前期的数据工作中,包括清洗、处理、探索性数据分析等。前期的工作不仅关乎数据的质量,也关乎最终模型预测效果的好坏。本文介绍一些比较冷门但效果不错的pandas方法来对数据进行初步探索,已经最后介绍一个非常方便实用的库pandas-profiling。
import pandas as pd
import numpy as np展示全部特征列
data = pd.read_csv('loans_2020.csv')
data.head()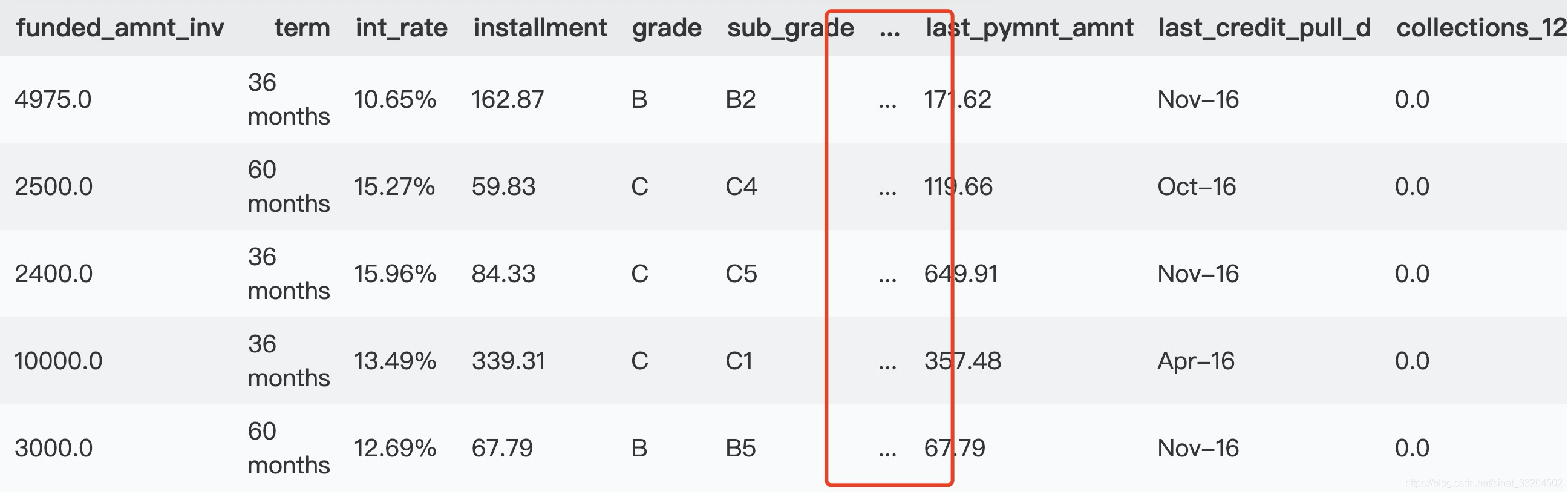
首先我们看到,对于一些比较大型的数据集导入时,会像上图这样将特征缩略,不能很好地直观看到所有的特征,那么此时可以将pandas的设置更改一下:
pd.set_option('display.max_columns', None)
data.head()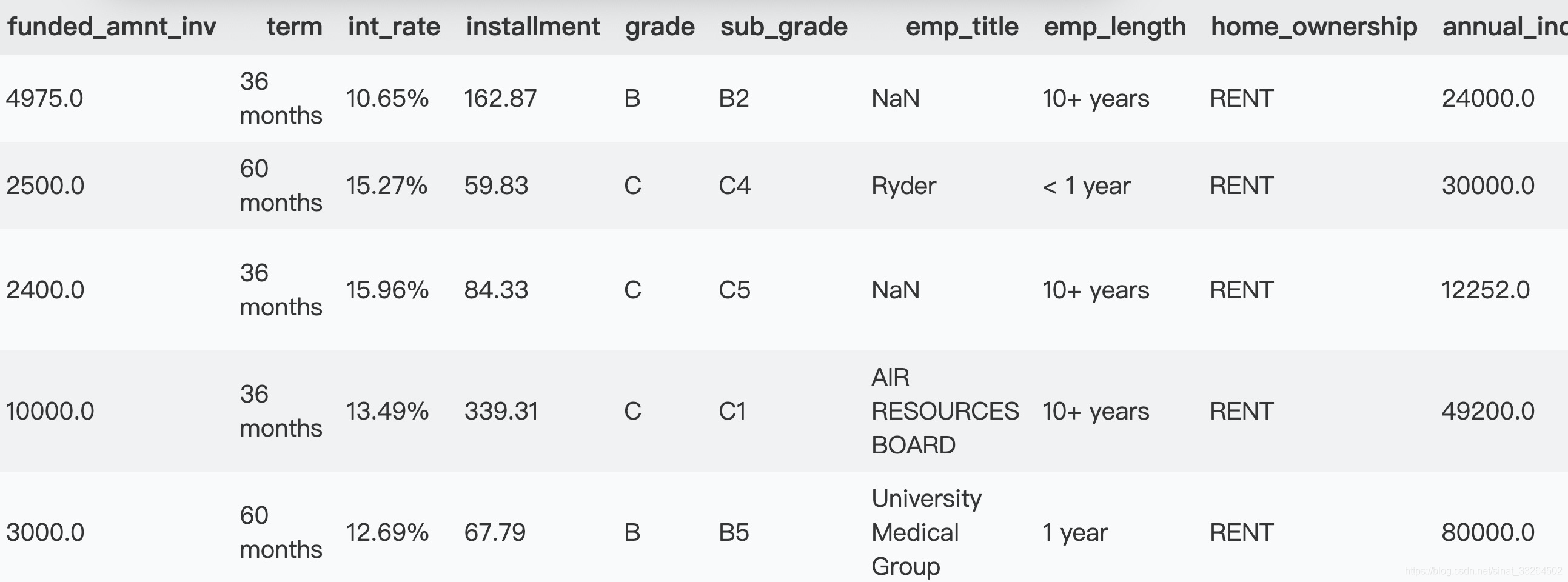
其中None可以改为你想要展示的具体最大列数。
展示单元格的全部内容
data1 = pd.DataFrame({'name': ['O'*80, 'X'*80]})
data1
像上图中如果一个单元格内的内容太多可能会缩略掉,若想展示全部内容的话也可以通过pandas设置来改变:
pd.set_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









