







 本文介绍了一种利用结巴分词(jieba)进行中文文本中人物关系抽取的方法,并通过NetworkX和Matplotlib实现了人物关系网络的可视化展示。通过加载自定义词典提高分词准确性,统计文本中人物出现频率及相互间的关系强度。
本文介绍了一种利用结巴分词(jieba)进行中文文本中人物关系抽取的方法,并通过NetworkX和Matplotlib实现了人物关系网络的可视化展示。通过加载自定义词典提高分词准确性,统计文本中人物出现频率及相互间的关系强度。
# -*- coding: utf-8 -*-
"""
Created on Wed May 3 12:58:30 2017
https://zhuanlan.zhihu.com/p/24767513 参考链接
@author: chuc
"""
import networkx as nx
import matplotlib.pyplot as plt
import jieba
import codecs
import jieba.posseg as pseg
names = {} # 姓名字典
relationships = {} # 关系字典
lineNames = [] # 每段内人物关系
# count names
jieba.load_userdict("some/person.txt") # 加载字典
with codecs.open("some/people.txt", "r") as f:
for line in f.readlines():
poss = pseg.cut(line) # 分词并返回该词词性
lineNames.append([]) # 为新读入的一段添加人物名称列表
for w in poss:
if w.flag != "nr" or len(w.word) < 2:
continue # 当分词长度小于2或该词词性不为nr时认为该词不为人名
lineNames[-1].append(w.word) # 为当前段的环境增加一个人物
if names.get(w.word) is None:
names[w.word] = 0
relationships[w.word] = {}
names[w.word] += 1 # 该人物出现次数加 1
# explore relationships
for line in lineNames: # 对于每一段
for name1 in line:
for name2 in line: # 每段中的任意两个人
if name1 == name2:
continue
if relationships[name1].get(name2) is None: # 若两人尚未同时出现则新建项
relationships[name1][name2]= 1
else:
relationships[name1][name2] = relationships[name1][name2]+ 1 # 两人共同出现次数加 1
with codecs.open("some/person_edge.txt", "a+", "utf-8") as f:
for name, edges in relationships.items():
for v, w in edges.items():
if w > 20:
f.write(name + " " + v + " " + str(w) + "\r\n")
a = []
f = open('some/person_edge.txt','r',encoding='utf-8')
line = f.readline()
while line:
a.append(line.split()) #保存文件是以空格分离的
line = f.readline()
f.close()
G = nx.Graph()
G.add_weighted_edges_from(a)
nx.draw(G,with_labels=True,font_size=12,node_size=1000,node_color='g')
plt.show()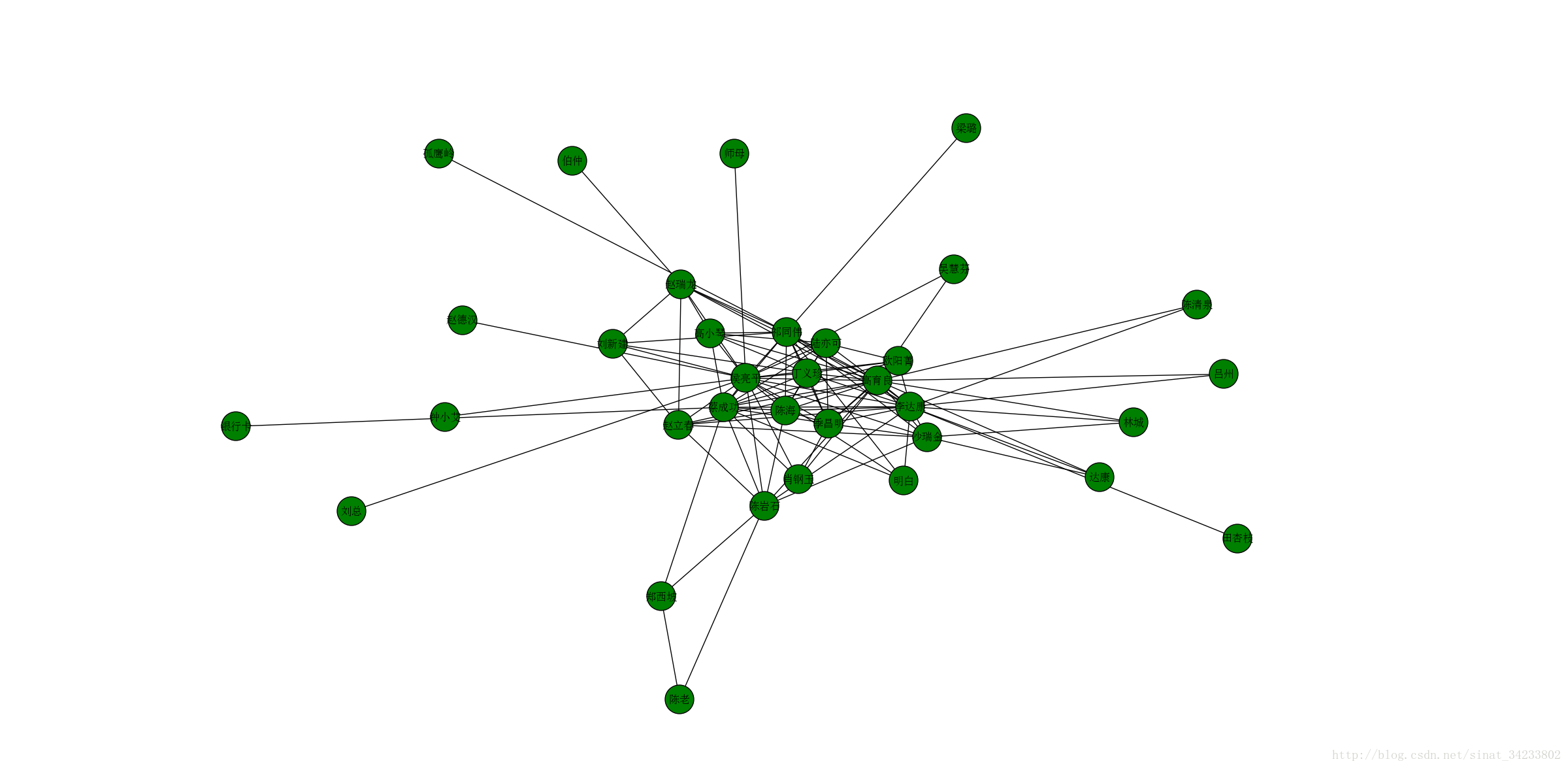

















09-18
 2401
2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









