







 本文详细介绍了Flume的架构,包括数据源、agent的组成部分(Source、Channel、Sink)以及Flume在数据传输中的可靠性问题。Flume作为一个数据传输工具,其核心是Agent,由Source负责收集数据,Channel用于暂存日志信息,Sink则负责将数据传出。文章还探讨了Source的实现方式(EventDrivenSource和PollableSource)、Channel的选择器(ReplicatingChannelSelector和MultiplexingChannelSelector)以及Flume在实际应用中的场景,如multi-agent flow、Consolidation和Multiplexing the flow。
本文详细介绍了Flume的架构,包括数据源、agent的组成部分(Source、Channel、Sink)以及Flume在数据传输中的可靠性问题。Flume作为一个数据传输工具,其核心是Agent,由Source负责收集数据,Channel用于暂存日志信息,Sink则负责将数据传出。文章还探讨了Source的实现方式(EventDrivenSource和PollableSource)、Channel的选择器(ReplicatingChannelSelector和MultiplexingChannelSelector)以及Flume在实际应用中的场景,如multi-agent flow、Consolidation和Multiplexing the flow。
首先回答一个问题的,What it is Flume?
这是一个分布式,高可用,可靠的分布式日志收集系统 ,能将不同的海量数据收集,移动并存储到一个数据存储系统中。
先说一句,这里说的是 NG!NG!NG!,然后就是本文可能会说的比较多、比较细,并且不谈安装配置(安装不提,配置根据不同情况不一而同,如果只想做个 demo 的话网上一大堆)。
在我看来,Flume-ng 已经说不上是一个所谓的系统了,没有了 master、没有了 control,去掉了很多臃肿的组件,现在应该将它称为一个优秀的传输工具。现在来把Flume拆开了谈一谈,先上图
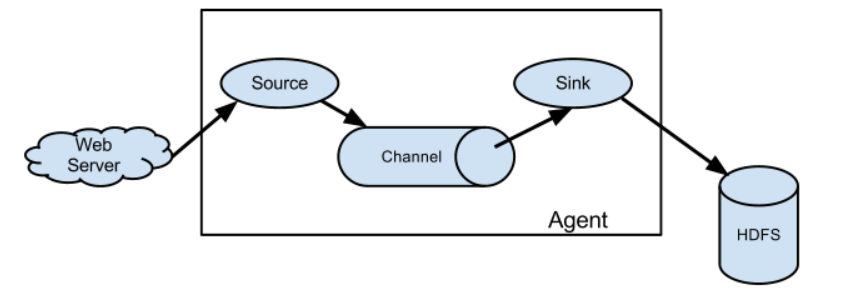
Agent–Flume的核心
agent 是 Flume 的一个独立进程,一个完整的数据收集工具,独立运行在一个 JVM 上,其中包含了 Flume 的核心组件(source、channel 和 sink)。
Client
client 其实是一个位于数据源的生产数据的组件,线程独立,供 agent 的 source 进行数据读取。
Event
event 是 flume 数据传输的单位,也是事务的基本单元。分为头部与数据部分,其中头部是一个 map,数据为字节数组。

Flow
Flume event 传输过程的抽象。
然后接下来具体点:
一、数据源
Client所支持的日志机制
Avro、Thrift、Syslog、Netcat、log4j 和 http(Post 传输(json 封装))等等。
Event
Flume 将一行文本反序列化为一个 event,可以定义 event 的大小、编码等。
Hearder
//event定义了一个描述数据的hearder
Map<String, String> getHeaders();
//你也可以set它(分装复用时起作用)
void setHeaders(Map<String, String> headers);Body
//event定义了一个存放数据数据的body
byte[] getBody();
//你也可以set它
void setBody(byte[] body); event 包装了数据内容到 body 中,并转换编码,且将hearder设置为空(如果不需要 fan out 到不同的 channel,header 无存在必要,如需要,则自定义),然后传入 channel 中。
public static Event withBody(byte[] body,Map<String, String> headers) {
Event event = new SimpleEvent();
if(body == null) {
body = new byte[0];
}
event.setBody(body);
if (headers != null) {
event.setHeaders(new HashMap<String, String>(headers));
}
return event;
} 二、agent
Source
source 用于收集传递到该 agent 的 event,其 type 有很多种,针对不同的日志数据传输机制,常用的有:
Avro Source
匹配 Avro ,针对 Avro 机制收集数据(rpc)。
Exec Source
基于 Unix/Linux 命令产生的数据。
JMS Source
连接到JMS(Topic 或 Queue)收集数据
Spooling Directory Source
监控文件夹的新文件生成,读取文件内容到channel(读取完重命名或删除该文件)。
Kafka Source
读取Kafka数据源。
来来来,看看Source接口定义:
public interface Source extends LifecycleAware, NamedComponent {
/**
* 设置channel对event的处理标识
*/
public void setChannelProcessor(ChannelProcessor channelProcessor);
/**
* 返回标识
*/
public ChannelProcessor getChannelProcessor();
}其实这里没啥东西,主要是些基础参数,利用 NamedComponent 定义每个组件的唯一标识,LifecycleAware 维护组件状态,定义 Channel 的操作。
然后看 Source 的抽象,主要是组件状态改变和取得标识,这里 Source 还有一个很重要的点是获取 Channel 事务对象的 ,这个在后面的 Channel 中说,各位大佬可以注意一下。
public abstract class AbstractSource implements Source {
private ChannelProcessor channelProcessor;
private String name;
private LifecycleState lifecycleState;
public AbstractSource() {
lifecycleState = LifecycleState.IDLE;
}
@Override
public synchronized void start() {
Preconditions.checkState(channelProcessor != null,
"No channel processor configured");
lifecycleState = LifecycleState.START;
}
@Override
public synchronized void stop() {
lifecycleState = LifecycleState.STOP;
}
@Override
public synchronized void setChannelProcessor(ChannelProcessor cp) {
channelProcessor = cp;
}
@Override
public synchronized ChannelProcessor getChannelProcessor() {
return channelProcessor;
}
@Override
public synchronized LifecycleState getLifecycleState() {
return lifecycleState;
}
@Override
public synchronized void setName(String name) {
this.name = name;
}
@Override
public synchronized String getName() {
return name;
}
public String toString() {
return this.getClass().getName() + "{name:" + name + ",state:" + lifecycleState + "}";
}
}说下使用情况,多数用的是 Spooling Directory Source,刚开始分析,多说点。首先,Spooling Directory Source 与其他 异步 Source 不一样的是它是可靠的。然后看看它是如何执行的,还是用源码说话吧:
public class SpoolDirectorySource extends AbstractSource
implements Configurable, EventDrivenSource {
private static final Logger logger = LoggerFactory.getLogger(SpoolDirectorySource.class);
/* 配置选项 */
//读取文件完成标记(default ".COMPLETED")
private String completedSuffix;
//配置的Flume监控目录(不监控子目录)
private String spoolDirectory;
//Header是否保存文件绝对路径
private boolean fileHeader;
//fileHeader在Header中的key(自身为value)
private String fileHeaderKey;
//Header是否保存文件名
private boolean basenameHeader;
//basenameHeader在Header中的key(自身为value)
private String basenameHeaderKey;
//每次处理行数(default "100")
private int batchSize;
private String includePattern;
//正则表达式(文件名匹配则略过不读)
private String ignorePattern;
//文件元数据存放目录
private String trackerDirPath;
//序列化
private String deserializerType;
private Context deserializerContext;
//文件读取完是否删除(default "never")
private String deletePolicy;
//读入编码方式(default "UTF-8")
private String inputCharset;
//有无法解析字符时的处理策略(default "FAIL 返回coderresult对象或者抛出charactercodingexception异常")
private DecodeErrorPolicy decodeErrorPolicy;
private volatile boolean hasFatalError = false;
private SourceCounter sourceCounter;
ReliableSpoolingFileEventReader reader;
private ScheduledExecutorService executor;
private boolean backoff = true;
private boolean hitChannelException = false;
private boolean hitChannelFullException = false;
//向 channel 中发送 event,出现 channel 溢满,则休眠,休眠时间成倍增加至该值后不变
private int maxBackoff;
//文件读取顺序(default "OLDEST")
private ConsumeOrder consumeOrder;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









