







先说说为啥有这系列文章,其实是应为公司最近在研发一个有关大数据风控的产品,要用到 Storm,我也就被安排接触这个框架了。
其实本来是打算这方面去研究 JStorm 的,听说更加优秀,而且是用 Java 写的,能看源码,但是工作为重。
所以说,最近忙忙的,这系列写的也肯定快不了。
好了,不说废话,先翻译官网介绍 storm 的一句话:
Storm 是一个分布式的,可靠的,容错的数据实时计算系统,用于流处理。
然后是我本人接触下来的理解,先看张图:
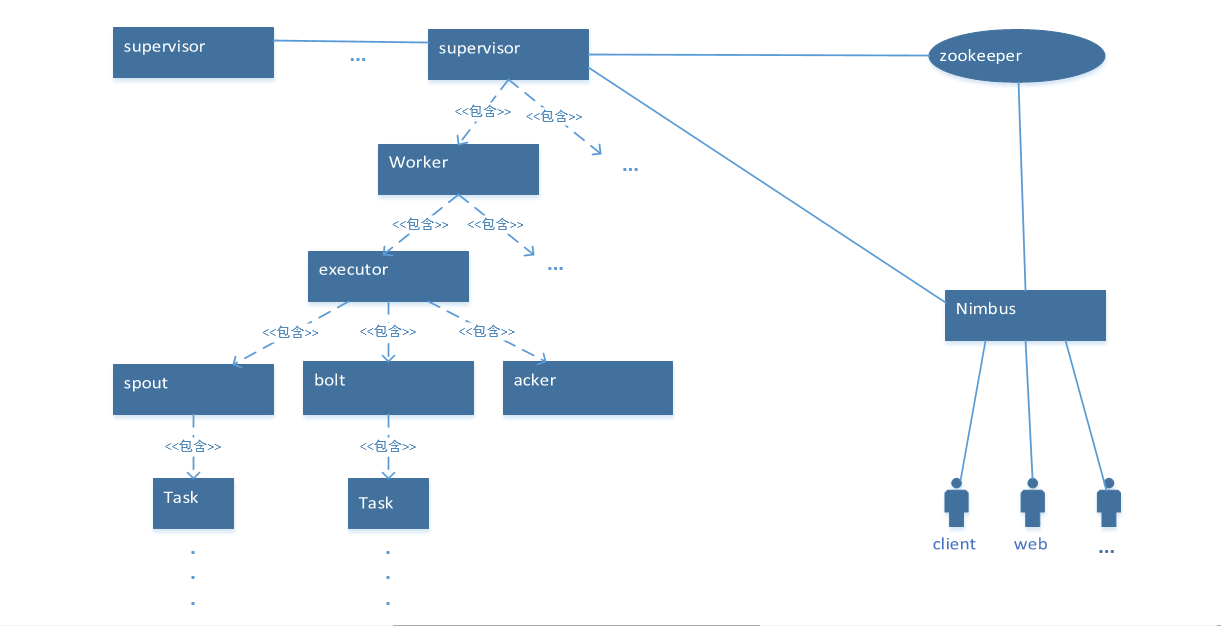
先拆开介绍下:
Nimbus: 整个集群的主控核心,负责 topology 的提交、运行状态监听、负载均衡及任务重新分配。
supervisor: 工作节点,主要是分配任务,记录心跳状态。
woker: 工作节点,一个 worker 对应一个进程。
executor: 物理容器,用于运行 task,一个 executor 对应一个线程。
topology: storm 作业,由各个计算节点组成。
component: 计算节点,也就是 spout、bolt 和 acker 的抽象概念。
task: spout、bolt 和 acker 的逻辑抽象。
tuple: 流处理中的基本处理单元。
spout: 流的源。
bolt: 接收流并进行处理,后输出。
acker: 锚定节点,可靠性处理。
接着说整体工作流程,看图,storm 集群是依赖于 zookeeper 的,Nimbus 的心跳监控、任务分配,supervisor 的心跳写入,获取任务都是由 zookeeper 管理的。其工作流程开始于一个 topology 提交到 nimbus,nimbus 进行任务分配,并将信息同步到 zookeeper,supervisor 定期获取任务分配信息(如果topology代码缺失,会从nimbus下载代码),并根据任务分配信息,调用 worker。worker 则根据分配的 tasks 信息,调用 executor ,实例化 component,此时整个流程进入 active 状态(除非主动 kill topology ,否则工作状态一直持续)。
然后看看,storm 如何对流进行逻辑处理的,扒一张官网的图:
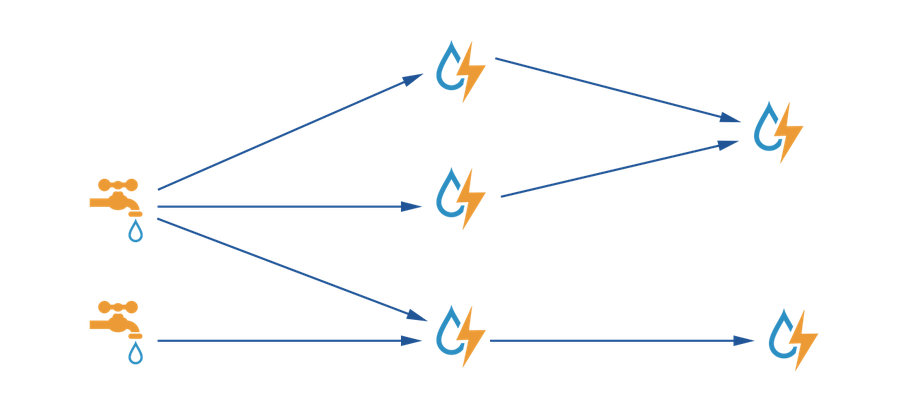
水龙头就是 spout,而电箱则是 bolt,水流则是 tuple 信息,是不是很形象,其传导过程及其灵活而且容易理解,spout 和 bolt 之间可以通过不同的流配置自由组合,构成 storm 的逻辑处理模式。
OK,第一篇就这么多,相信各位看看也能懂 storm 整体架构以及工作流程了。















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









