






如何实现LLM输出的Callback可视化
背景
当我们是用React大模型进行输出时,由于React这类推理的大模型它的输出不是一次性的,内部会有一个完整的推理过程。
实现
准备环境
导入需要的包
import streamlit as st # 导入streamlit
from langchain_community.callbacks.streamlit import StreamlitCallbackHandler 导入callback
创建streamlit配置
st.set_page_config(page_title="Code Agent",layout="wide")
st.title("Code Agent")
实现可在界面上配置的API KEY
我这里使用的是通义千问的模型,为了不用每次都要输入,设置默认获取本地环境变量中的key,没找到再获取sidebar.text_input控件的值,都没获取到就不往下走了
input_api_key = st.sidebar.text_input(
label="通义千问API KEY",
placeholder="输入后点击回车键生效",
type="password",
)
dashscope_api_key = os.environ.get("DASHSCOPE_API_KEY",input_api_key)
# 检查API KEY
if not dashscope_api_key:
st.info("请配置通义千问的API KEY")
st.stop()
实现React Agent
实现react agent,并绑定PythonREPLTool,让大模型能够通过编程来回答用户提问,下面的代码同时实现了模型记忆功能。
instructions = """You are an agent designed to write and execute python code to answer questions.
You have access to a python REPL, which you can use to execute python code.
If you get an error, debug your code and try again.
Only use the output of your code to answer the question.
You might know the answer without running any code, but you should still run the code to get the answer.
If it does not seem like you can write code to answer the question, just return "I don't know" as the answer.
"""
base_prompt_template = """
{instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
```
When you have a response to say to the Human, or if you do not need to use a tool, you MUST use the format:
```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}"""
base_prompt = PromptTemplate.from_template(base_prompt_template)
prompt = base_prompt.partial(instructions=instructions)
llm = ChatTongyi(model="qwen-max",)
tools = [PythonREPLTool()]
msgs = StreamlitChatMessageHistory()
memory = ConversationBufferMemory(
chat_memory=msgs, return_messages=True, memory_key="chat_history", output_key="output"
)
agent = create_react_agent(llm,tools,prompt)
if "messages" not in st.session_state or st.sidebar.button("清空聊天记录"):
st.session_state["messages"] = [{"role": "assistant", "content": "您好,我是助手小C,我会编程。"}]
# 加载历史聊天记录
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
agent_executor = AgentExecutor(agent=agent, tools=tools,memory=memory,verbose=False)
创建agent执行,并实现回调
因为langchain迭代比较快,目前在网络上找到的、书里面的,甚至官方demo,这个回调的写法都过时了
以前可能写法:直接在agent_executor.run方法中传callbacks参数,但是最新代码不支持run方法,只能用invoke,
st_cb = StreamlitCallbackHandler(st.container())
response = agent_executor.run({"input":user_query}, callbacks=[st_cb])
现在则需要构造一个config参数,写法如下:
# 创建聊天输入框
user_query = st.chat_input(placeholder="请开始提问吧!")
if user_query:
st.session_state.messages.append({"role": "user", "content": user_query})
st.chat_message("user").write(user_query)
with st.chat_message("assistant"):
st_cb = StreamlitCallbackHandler(st.container())
config = {"callbacks":[st_cb]}
response = agent_executor.invoke({"input":user_query}, config=config)
st.session_state.messages.append({"role": "assistant", "content": response["output"]})
st.write(response["output"])
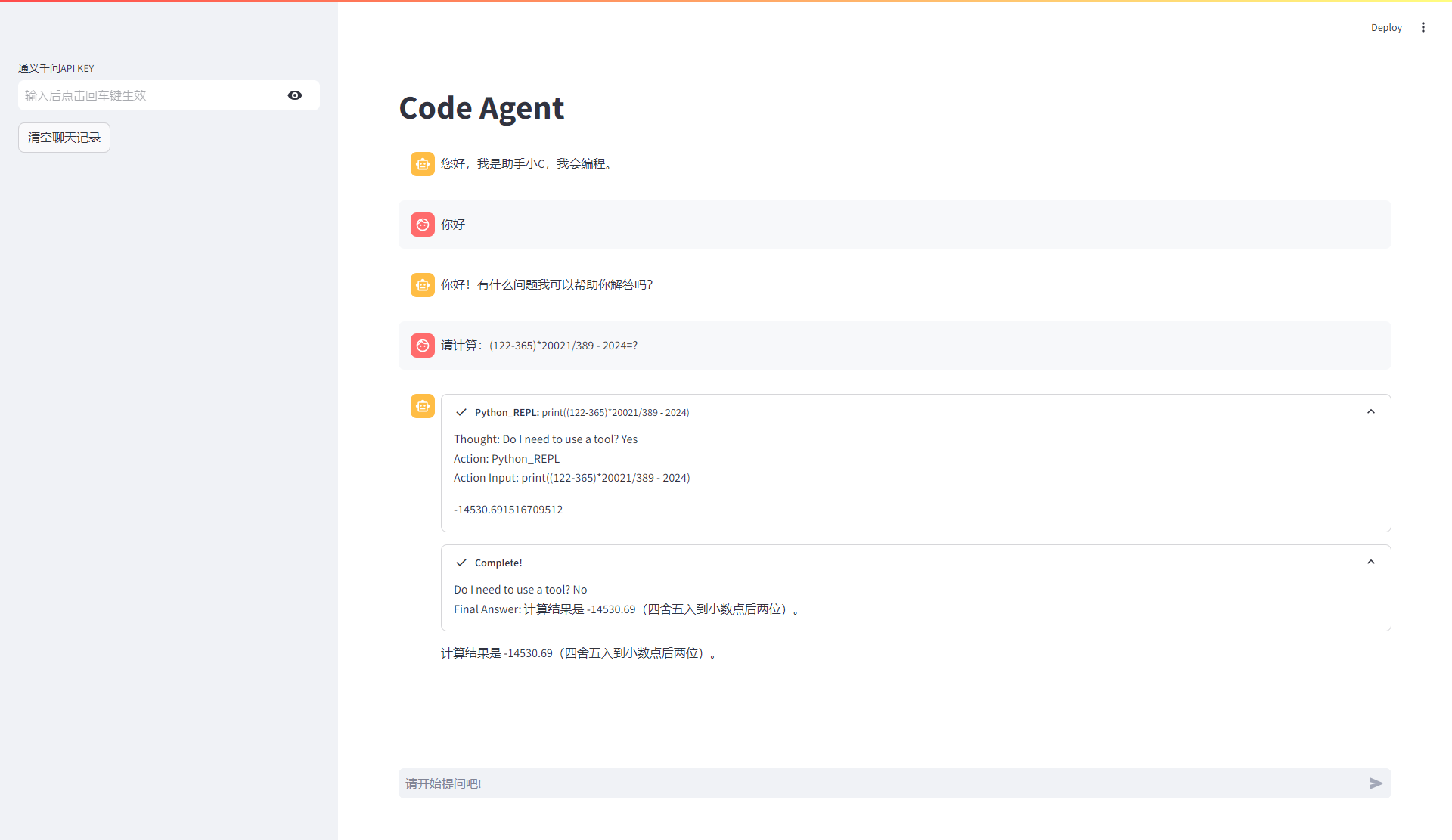
运行效果
可以看到,大模型的输出通过streamlit的callback显示了整个推理过程。















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









