




 数据分箱通过将数值分类提升数据可读性。在Python中,使用pandas的cut方法可对Series和DataFrame进行分箱操作。例如,将成绩分为不及格、一般、良好和优秀四个等级,并统计各等级人数。同样,可以为DataFrame的多个列定义分箱规则,提高数据展示的清晰度。
数据分箱通过将数值分类提升数据可读性。在Python中,使用pandas的cut方法可对Series和DataFrame进行分箱操作。例如,将成绩分为不及格、一般、良好和优秀四个等级,并统计各等级人数。同样,可以为DataFrame的多个列定义分箱规则,提高数据展示的清晰度。
数据分箱就是按照某种规则将数据进行分类。就像可以将水果按照大小进行分类,售卖不同的价格一样。
对series进行分箱
首先创建一个整形随机的series,表示学生的成绩:

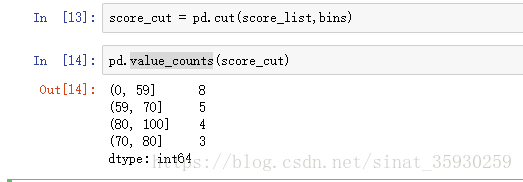
然后指定一个分箱原则,规定:0-59为不及格,59-70为一般,70-80为良好,80-100位优秀:

然后利用pandas中的cut方法,指定分箱规则和对象,结果将获得一个Categories对象:

对于这个对象就可以使用pandas中的value_counts方法来统计各个段内数据的个数:
对dataframe分箱
首先创建一个包含学生分数和姓名的dataframe:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7650
7650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









