








一、聚类分析算法评价
聚类分析仅根据样本数据本身将样本分组。其目标是实现组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内的相似性越大,组间差别越大,聚类效果就越好。
(1)purity评价法

(2)RI评价法

(3)F值评价法

二、python主要聚类分析算法
python的聚类相关的算法主要在Scikit-Learn中,python里面实现的聚类主要包括K-Means聚类、层次聚类、FCM以及神经网络聚类。
聚类主要函数列表:

这些不同模型的使用方法是大同小异的,基本都是先用对应的函数建立模型,然后用.fit()方法来训练模型,训练好之后,就可以用.label_方法给出样本数据的标签,或者用.predict() 方法预测新的输入标签。
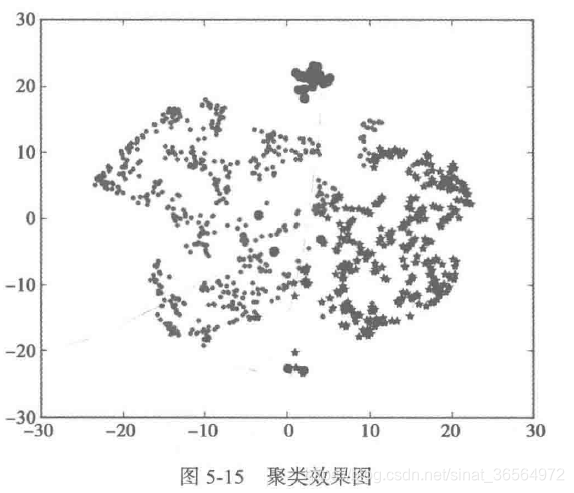
TSNE-聚类可视化工具
TSNE的定位是高维数据的可视化。通常来说输入的特征数是高维的(大于3维),一般很难以原特征对聚类结果进行展示。TSNE提供了一种有效的数据降维方式,让我们可以在2维或者3维的空间中展示聚类的结果。
TSNE实例:
对K-Means聚类结果以二维的方式展现出来:
#-*- coding: utf-8 -*-
#接k_means.py
from sklearn.manifold import TSNE
tsne = TSNE()
tsne.fit_transform(data_zs) #进行数据降维
tsne = pd.DataFrame(tsne.embedding_, index = data_zs.index) #转换数据格式
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
#不同类别用不同颜色和样式绘图
d = tsne[r[u'聚类类别'] == 0]
plt.plot(d[0], d[1], 'r.')
d = tsne[r[u'聚类类别'] == 1]
plt.plot(d[0], d[1], 'go')
d = tsne[r[u'聚类类别'] == 2]
plt.plot(d[0], d[1], 'b*')
plt.show()输出:















 479
479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









