







前言
主要是为了记录下学习小度自定义技能的过程
一、学习简介
参考官网解释 自定义技能简介
二、代码快速开发
我的代码架构
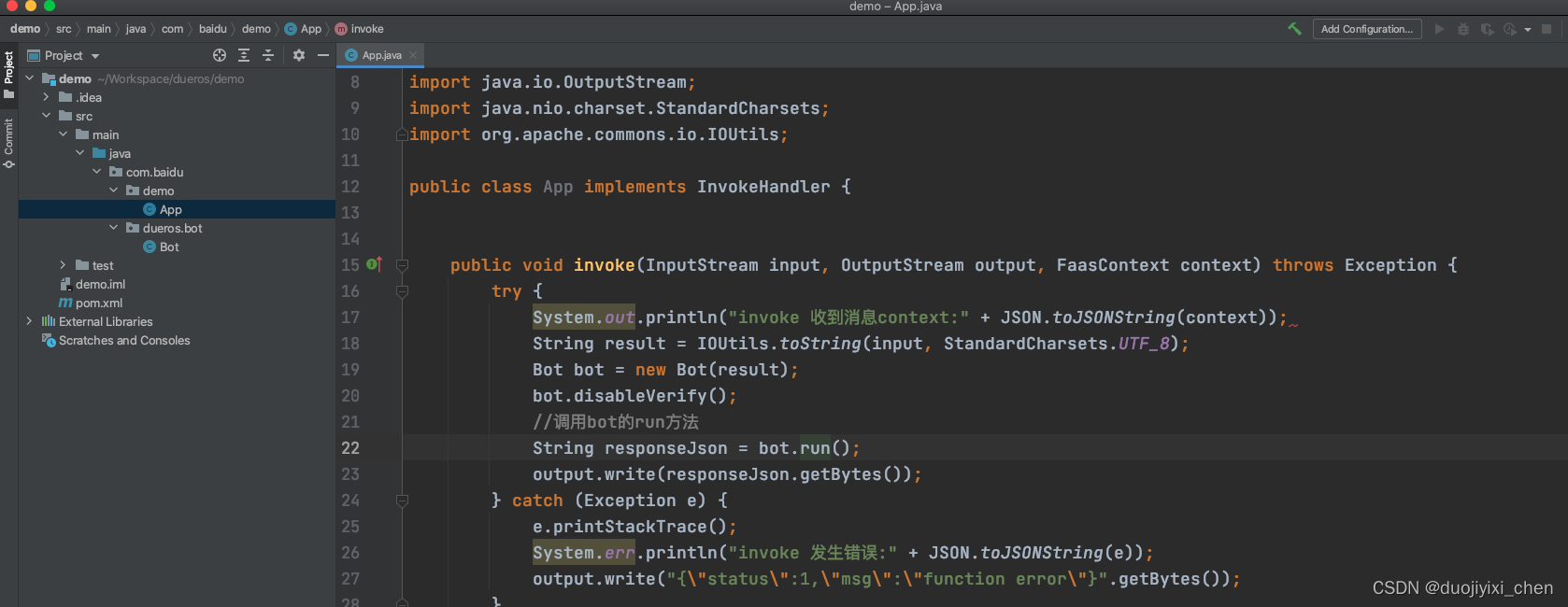
Bot.java这个类是需要去继承,然后重写的,但是官网没有给出,需要自己去探索
下面给出我测试的代码
public class Bot extends BaseBot {
public Bot(String request) throws IOException {
super(request);
}
protected Response onLaunch(LaunchRequest launchRequest) {
System.out.println("onLaunch收到消息啦啦啦~~~~~~launchRequest" + JSON.toJSONString(launchRequest));
// 新建文本卡片
TextCard textCard = new TextCard("山盟海誓卡片~");
// 设置链接地址
textCard.setUrl("www.ooxx.com");
// 设置链接内容
textCard.setAnchorText("爱我就点我……^_^¥¥¥");
// 添加引导话术
textCard.addCueWord("我想找个女朋友");
// 新建返回的语音内容
OutputSpeech outputSpeech = new OutputSpeech(OutputSpeech.SpeechType.PlainText, "欢迎吃爱情面包。。。。。。");
// 构造返回的Response
Response response = new Response(outputSpeech, textCard);
System.out.println("onLaunch 返回数据response:" + JSON.toJSONString(response));
return response;
}
@Override
protected Response onInent(IntentRequest intentRequest) {
System.out.println("onInent 收到消息intentRequest:" + JSON.toJSONString(intentRequest));
// 判断NLU解析的意图名称是否匹配 inquiry_tax
if ("inquiry_tax".equals(intentRequest.getIntentName())) {
// 判断NLU解析解析后是否存在这个槽位
if (getSlot("ssys.date") == null) {
// 询问月薪槽位
System.out.println("日期是多少");
} else if (getSlot("sys.city") == null) {
// 询问城市槽位
System.out.println("城市是哪个");
} else {
// 计算个税缴纳情况
System.out.println("未知的槽位");
}
}
TextCard textCard = new TextCard("意图卡片");
OutputSpeech outputSpeech = new OutputSpeech(OutputSpeech.SpeechType.PlainText, "爱情意图666");
Response response = new Response(outputSpeech, textCard);
System.out.println("onInent 返回数据response:" + JSON.toJSONString(response));
return response;
}
@Override
protected Response onSessionEnded(SessionEndedRequest sessionEndedRequest) {
System.out.println("onSessionEnded 收到消息:" + JSON.toJSONString(sessionEndedRequest));
// 构造TextCard
TextCard textCard = new TextCard("爱您么么哒");
textCard.setAnchorText("setAnchorText");
textCard.addCueWord("");
// 构造OutputSpeech
OutputSpeech outputSpeech = new OutputSpeech(OutputSpeech.SpeechType.PlainText, "爱您么么哒88");
// 构造Response
Response response = new Response(outputSpeech, textCard);
System.out.println("onSessionEnded 返回数据response:" + JSON.toJSONString(response));
return response;
}
}
三、官网配置
3.1 百度云CFC配置
推荐使用华北-北京
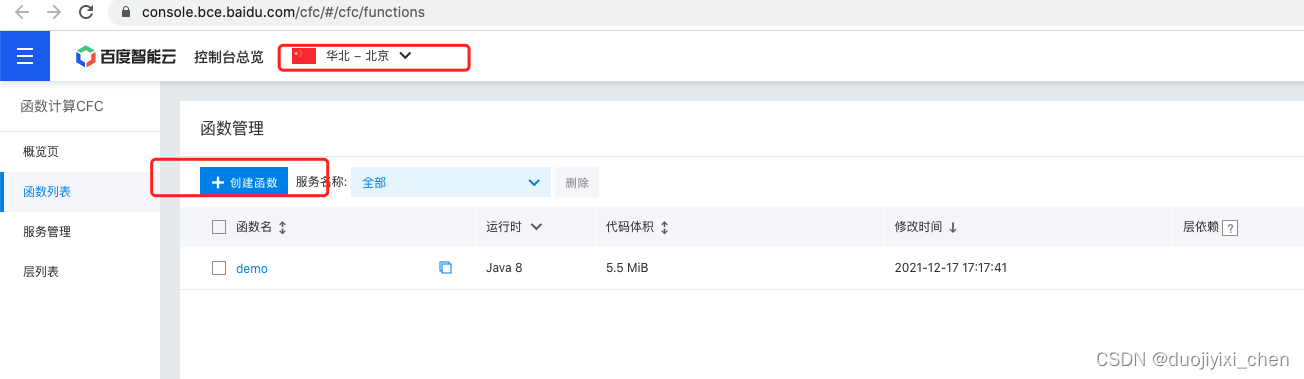
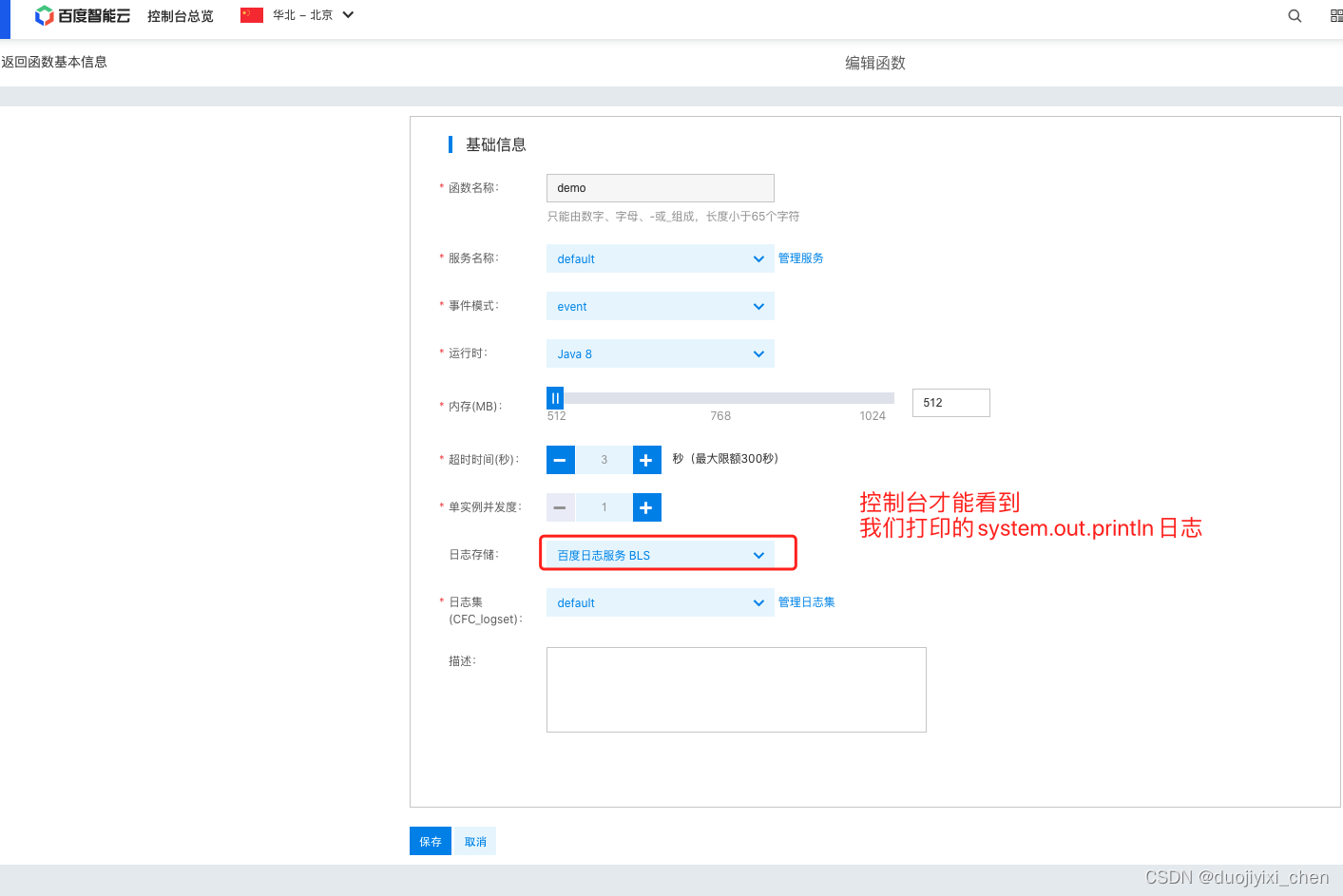
将自己的包打成zip包,参考代码快速开发官网地址
找到如下命令,在自己的工程中执行如下:
mvn package
cd target
zip java-bot.zip demo-1.0-jar-with-dependencies.jar
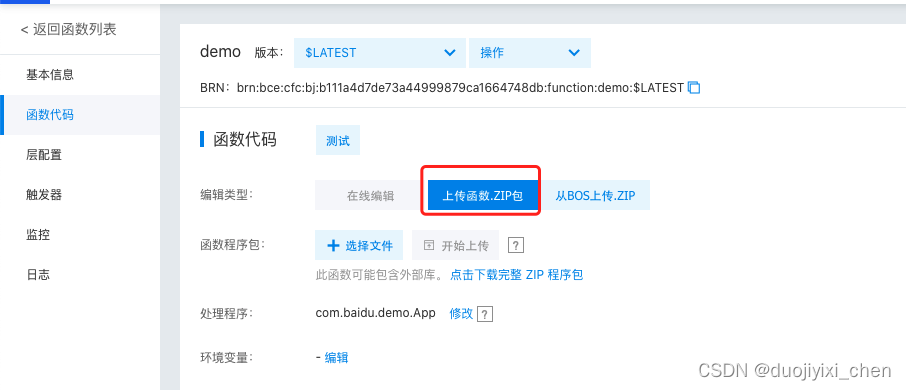
触发器一定要选择这个
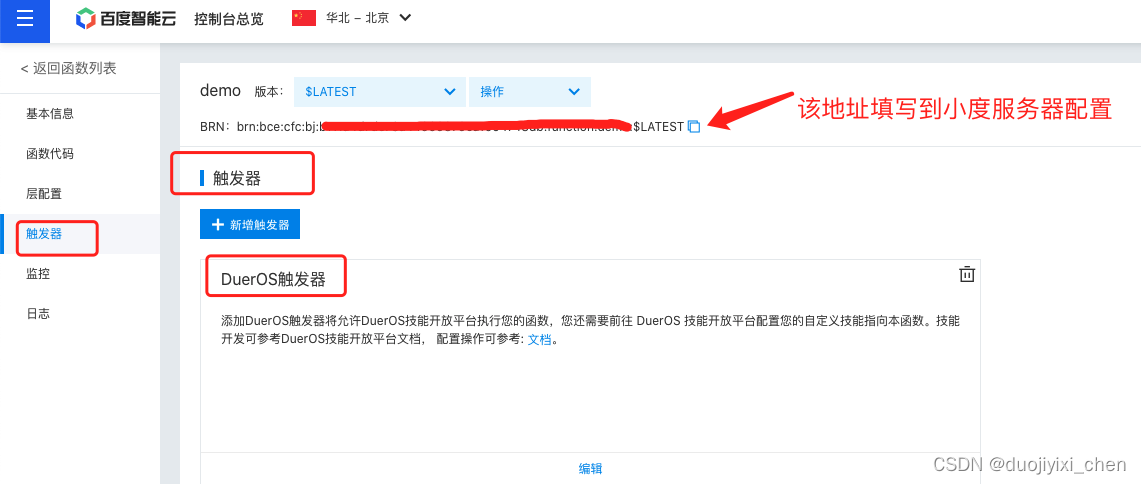
3.2 小度官网配置

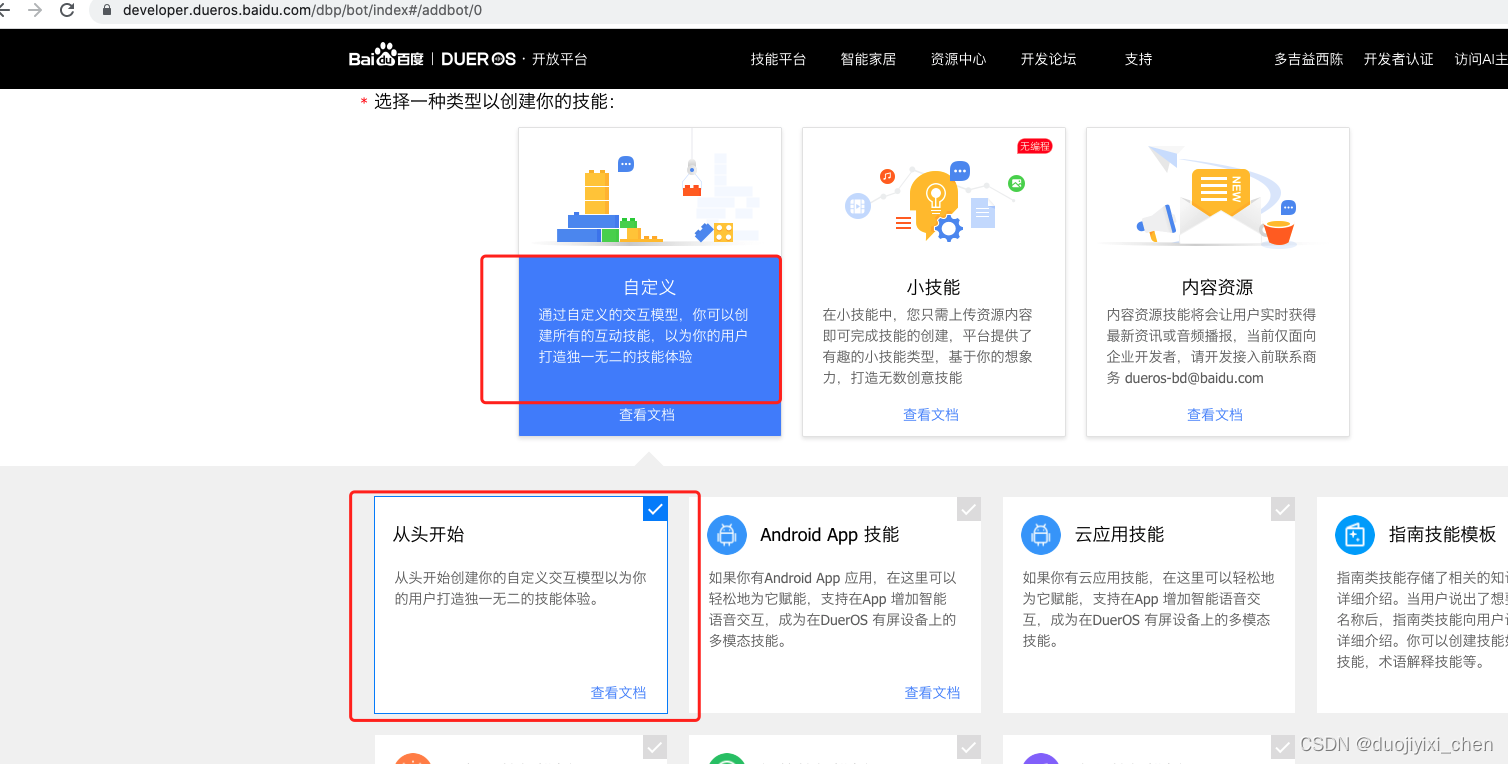
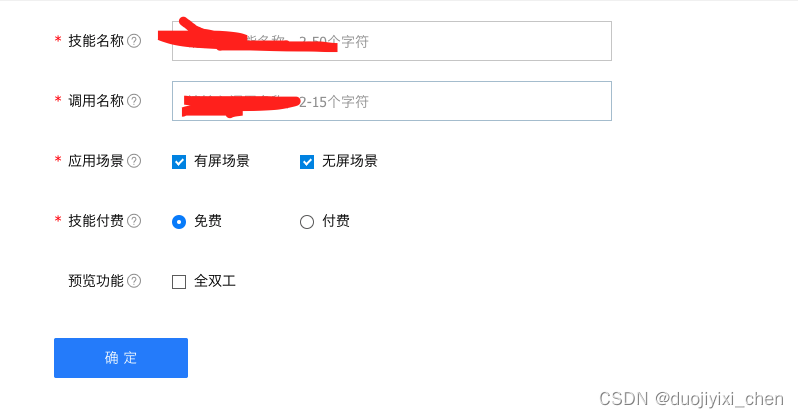
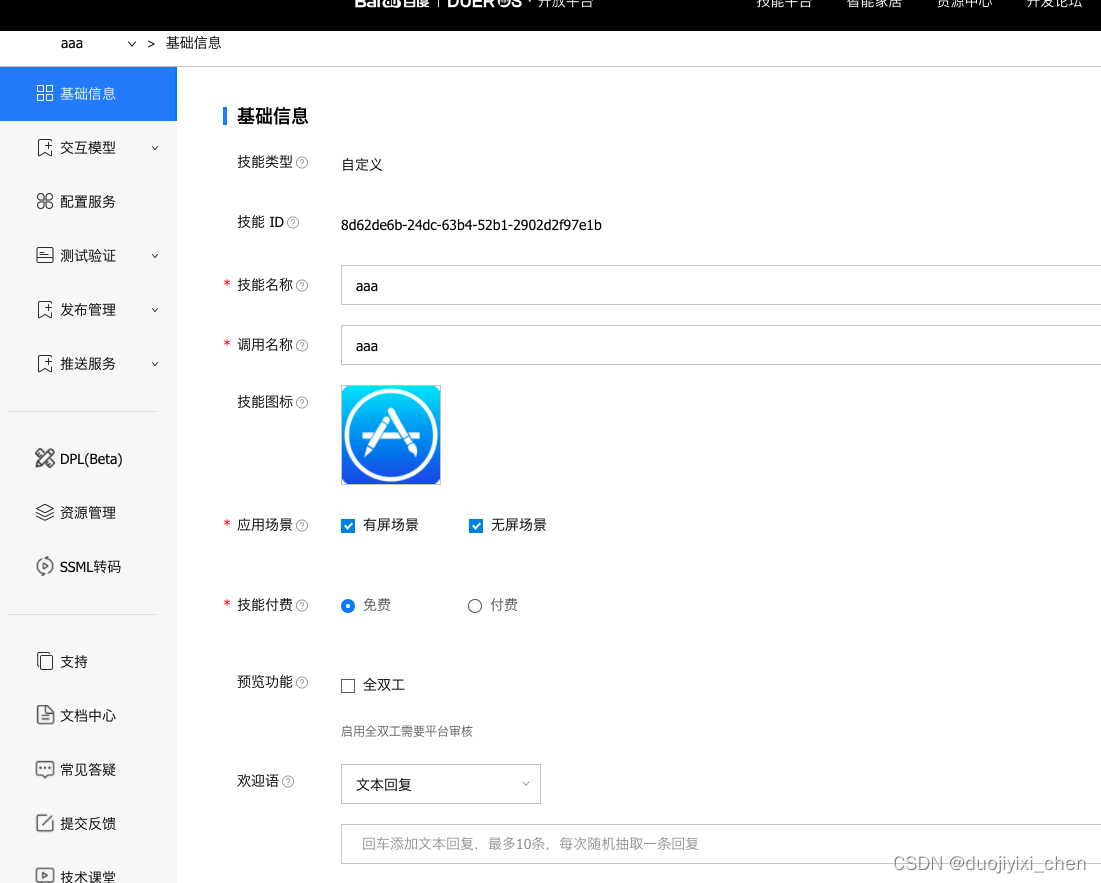
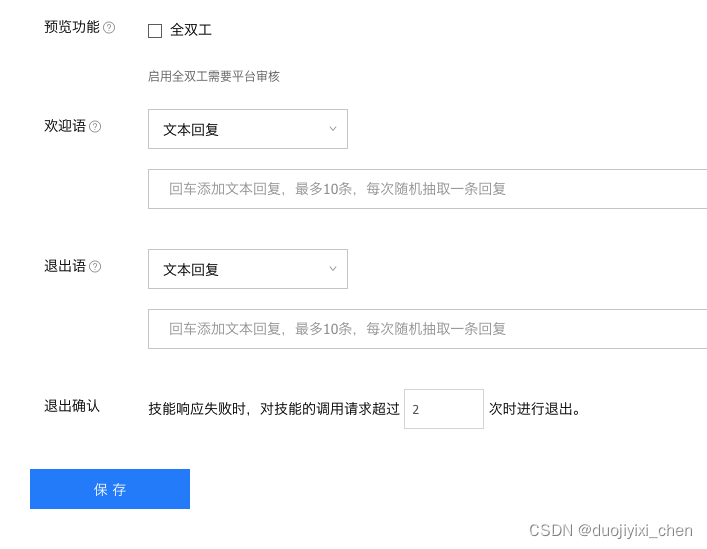
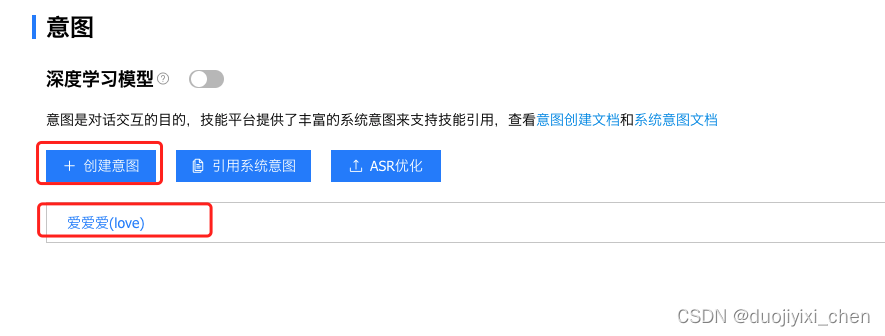
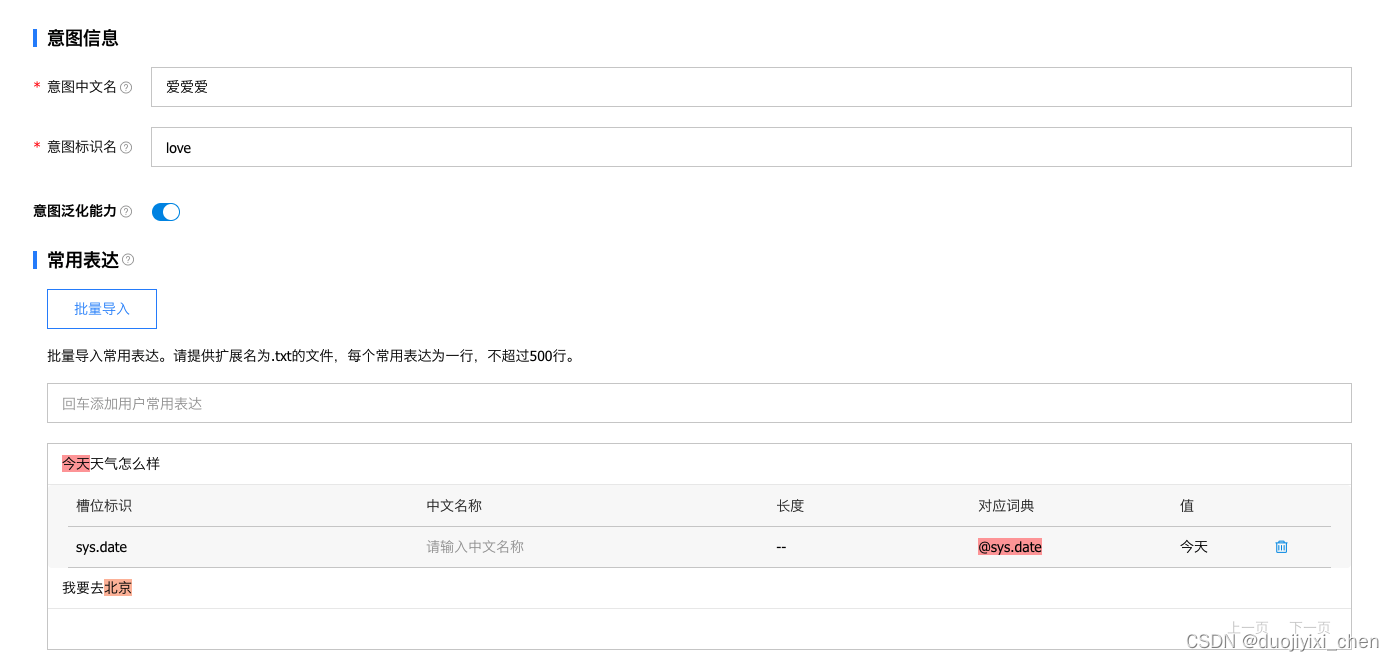
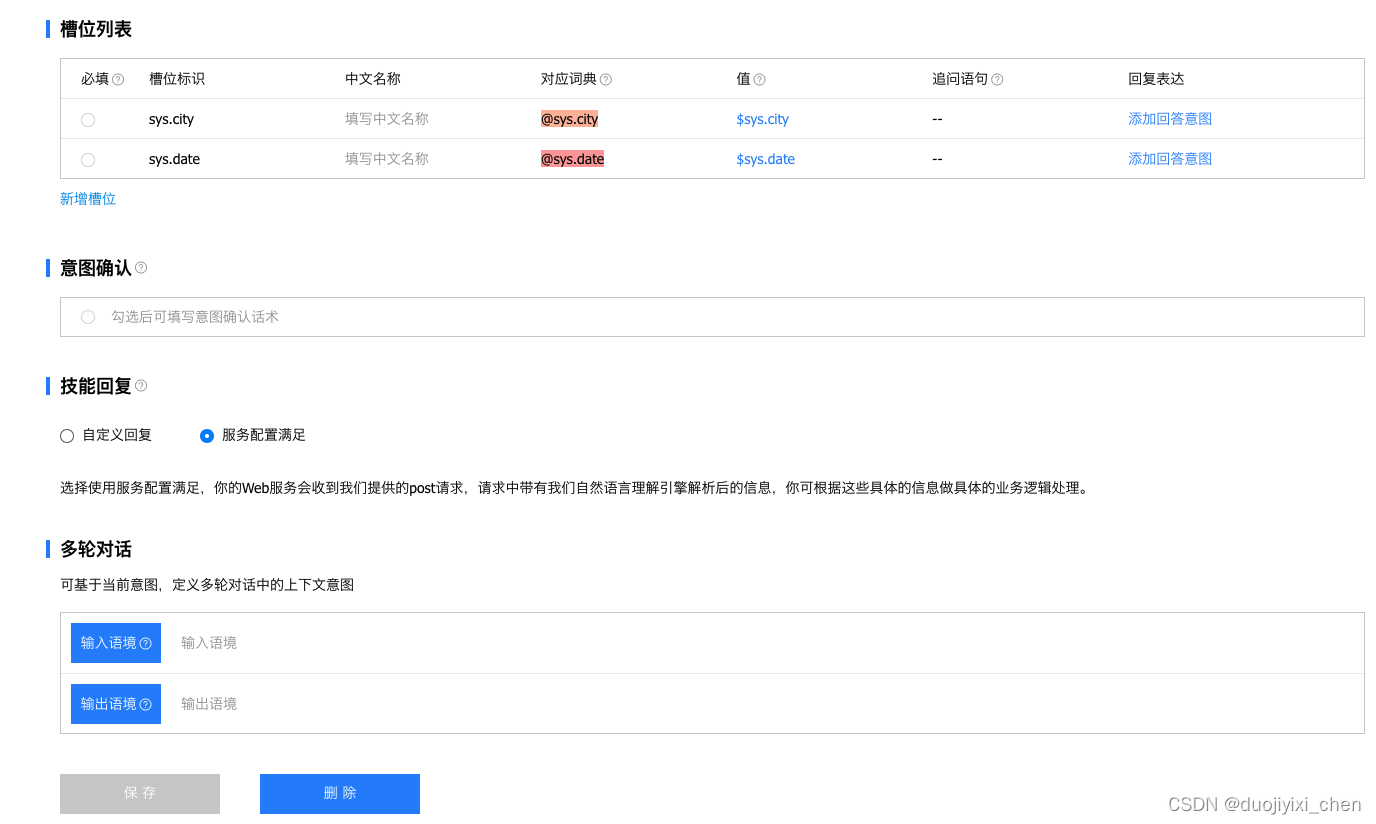
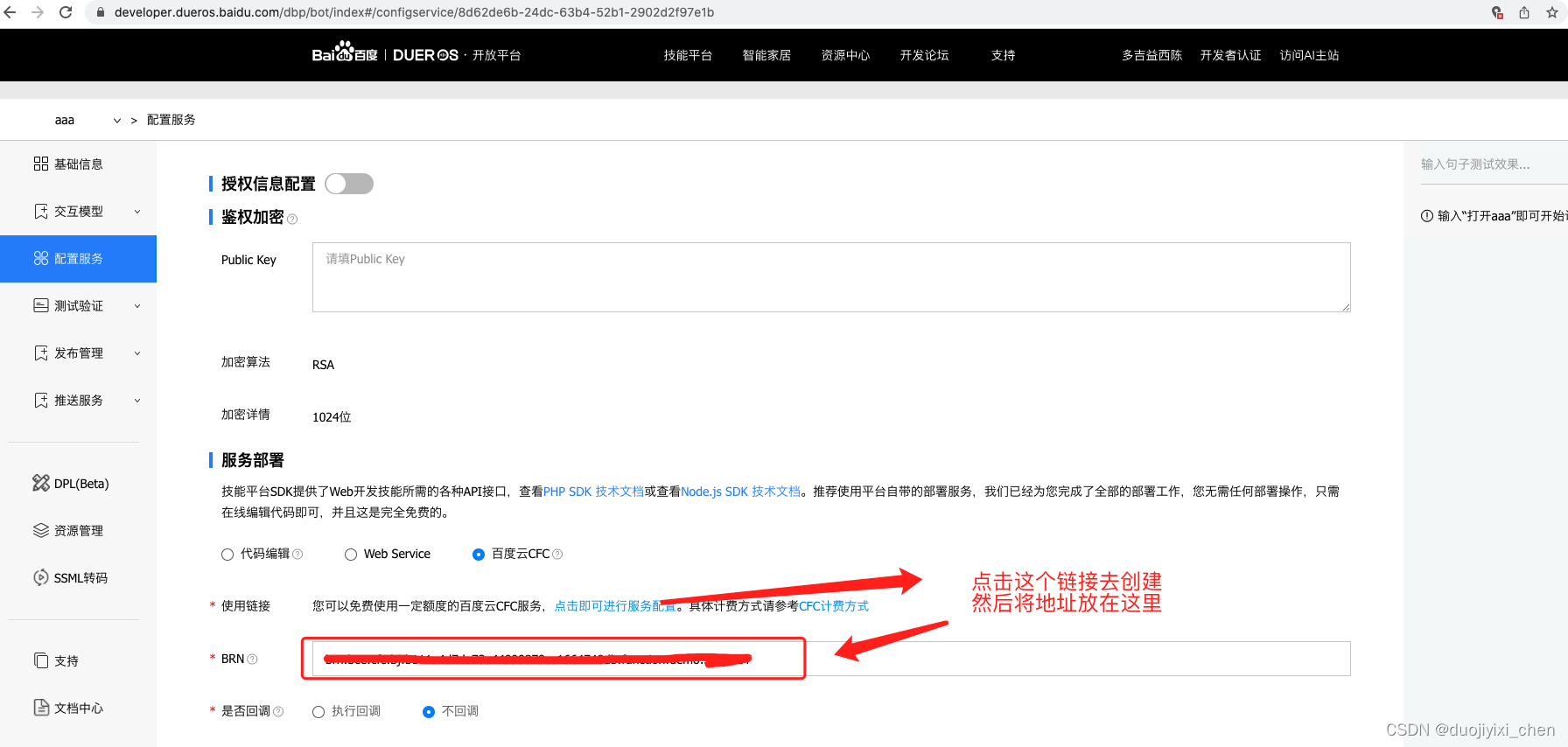
四、测试
4.1连接技能
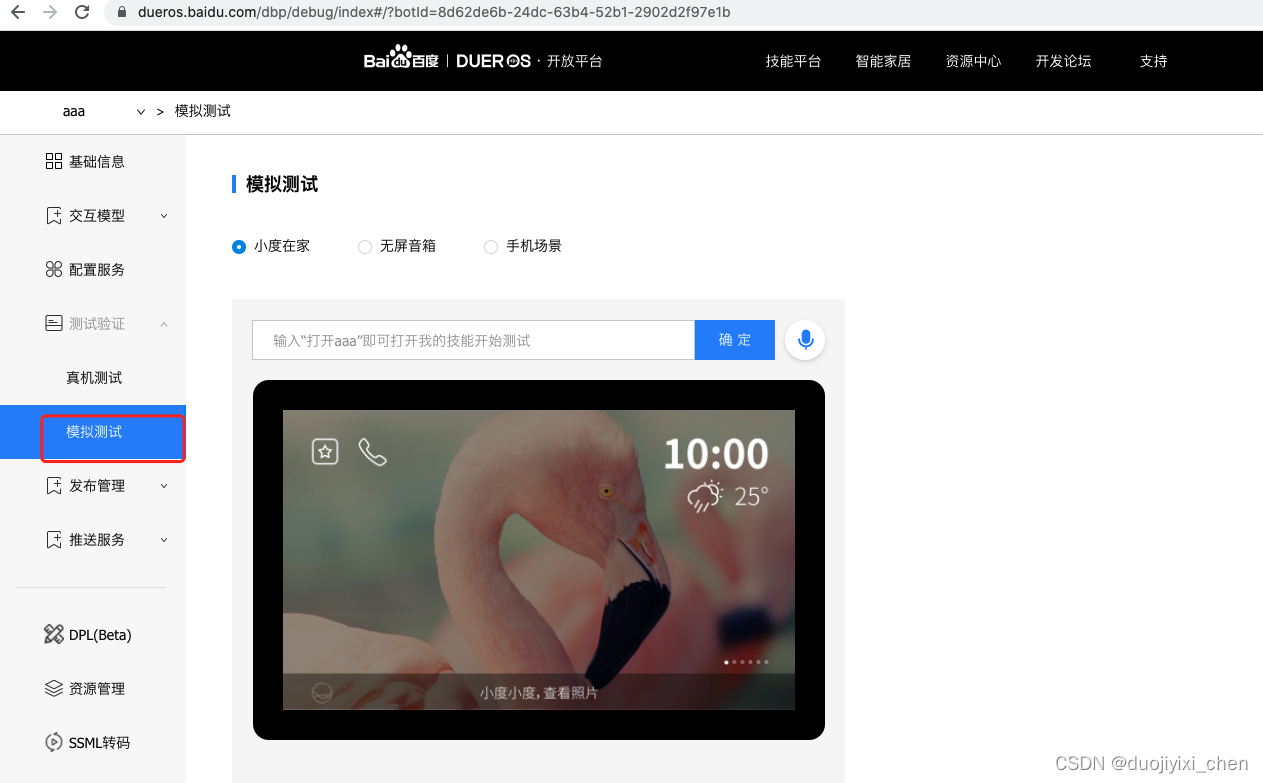
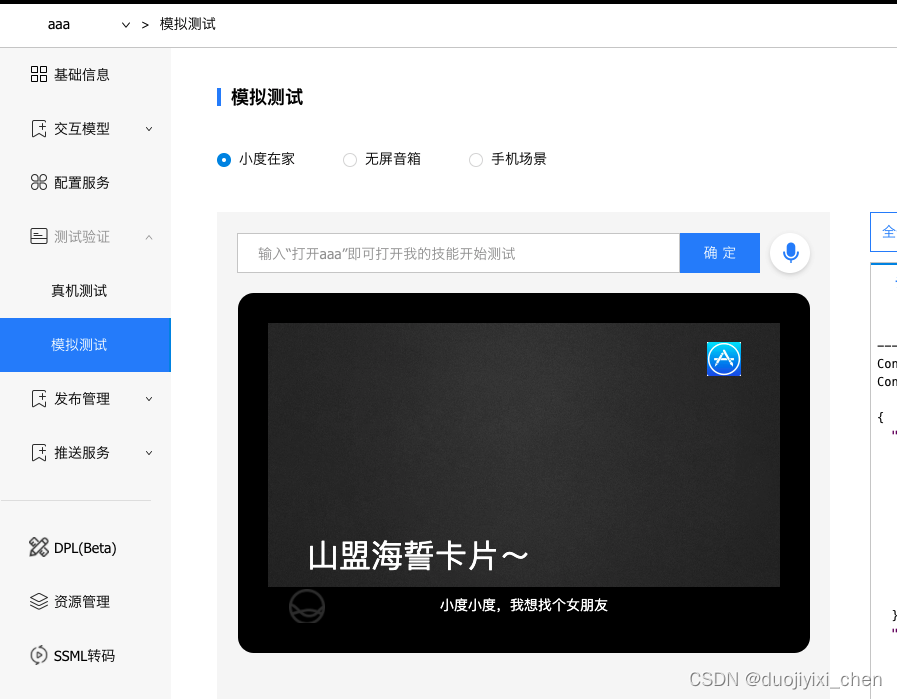
激活技能成功
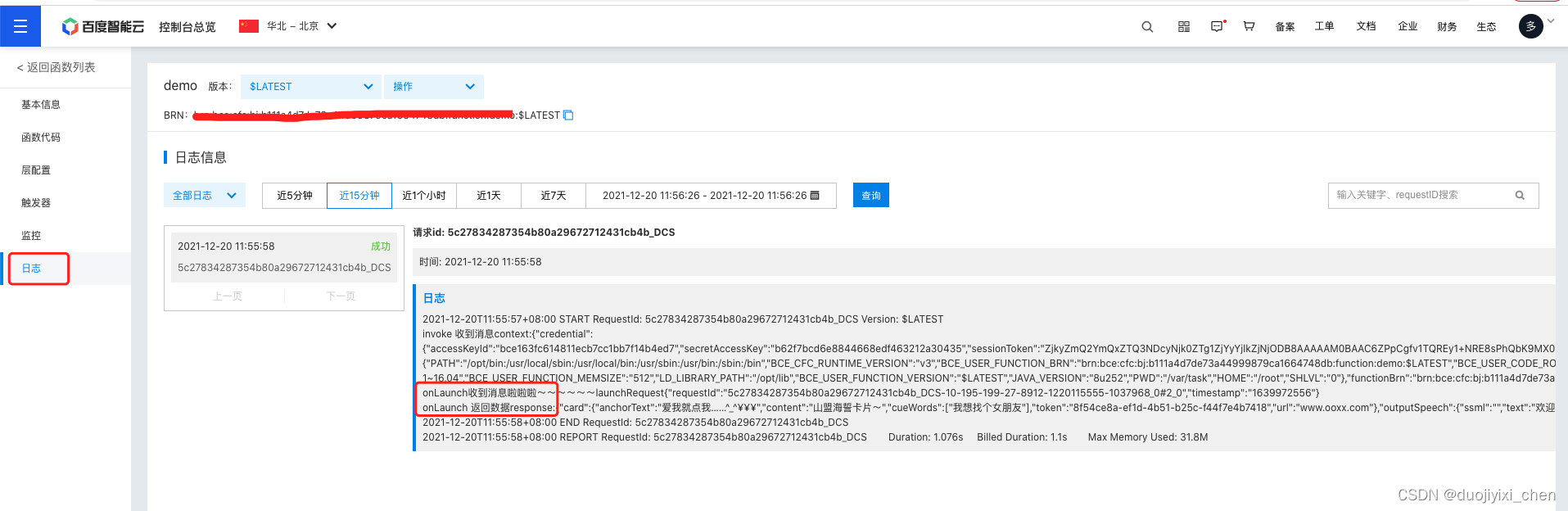
查看日志成功
4.2 意图测试
在上面技能打开的前提下,测试意图
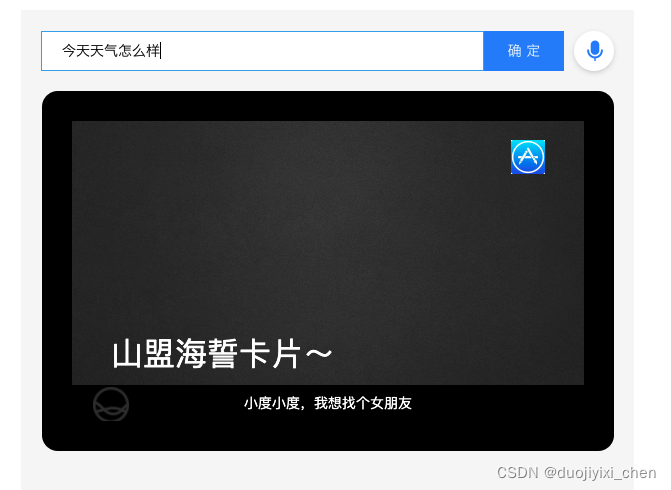
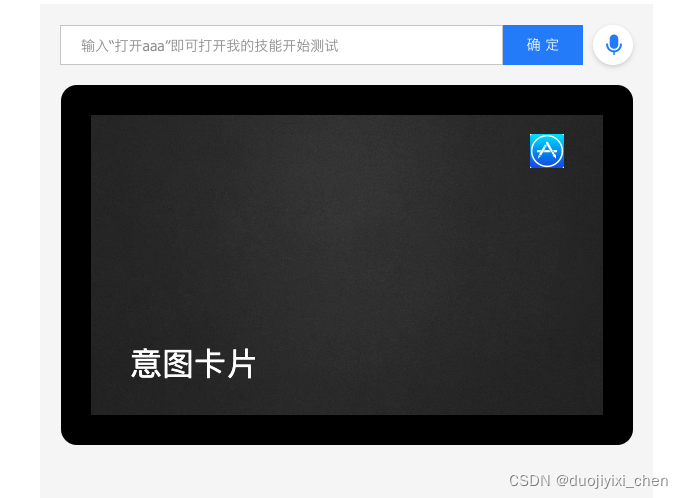
查看日志
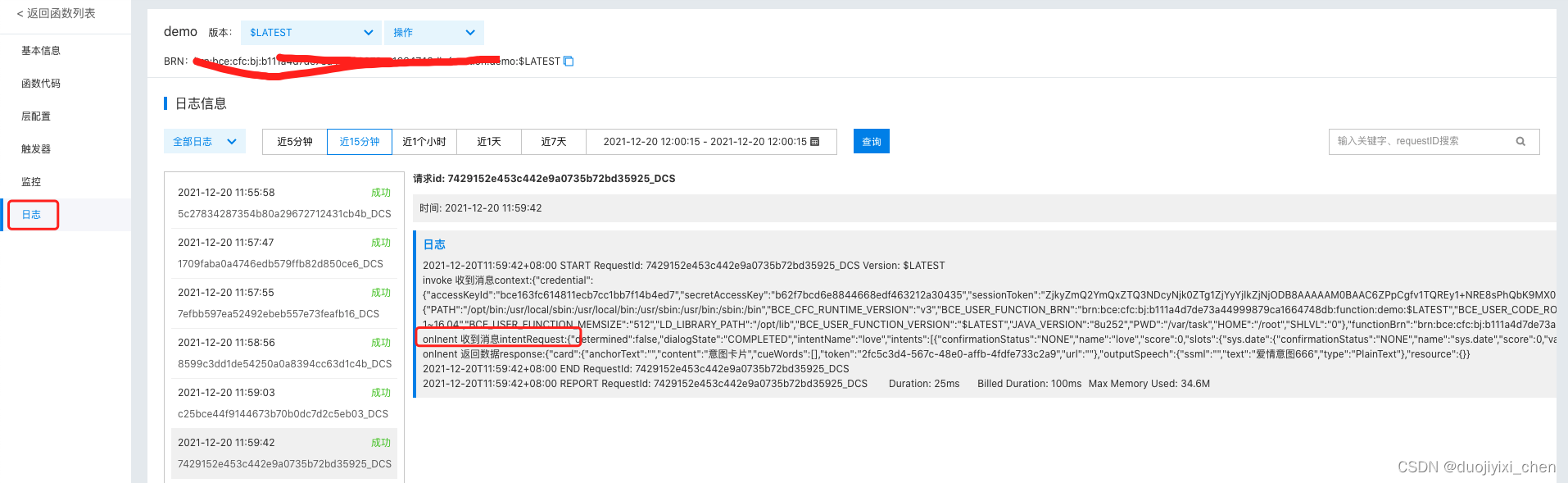
意图测试ok
4.3 断开技能
输入退出,小度会说代码指定爱你么么哒语音
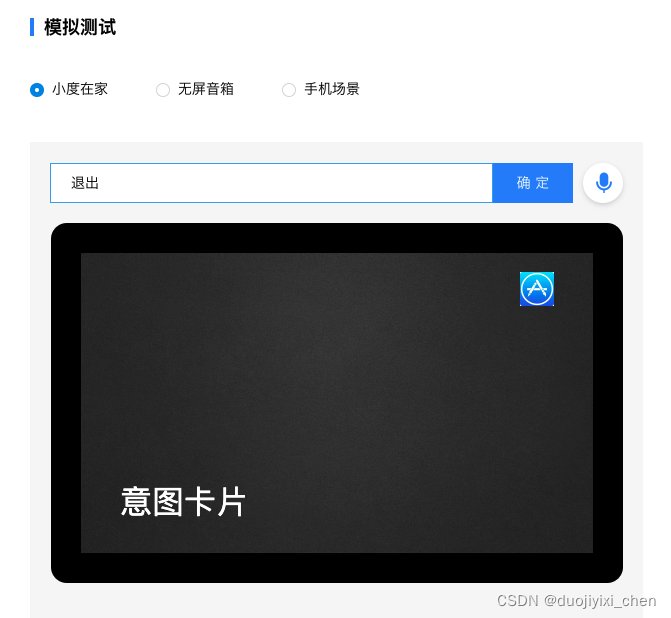
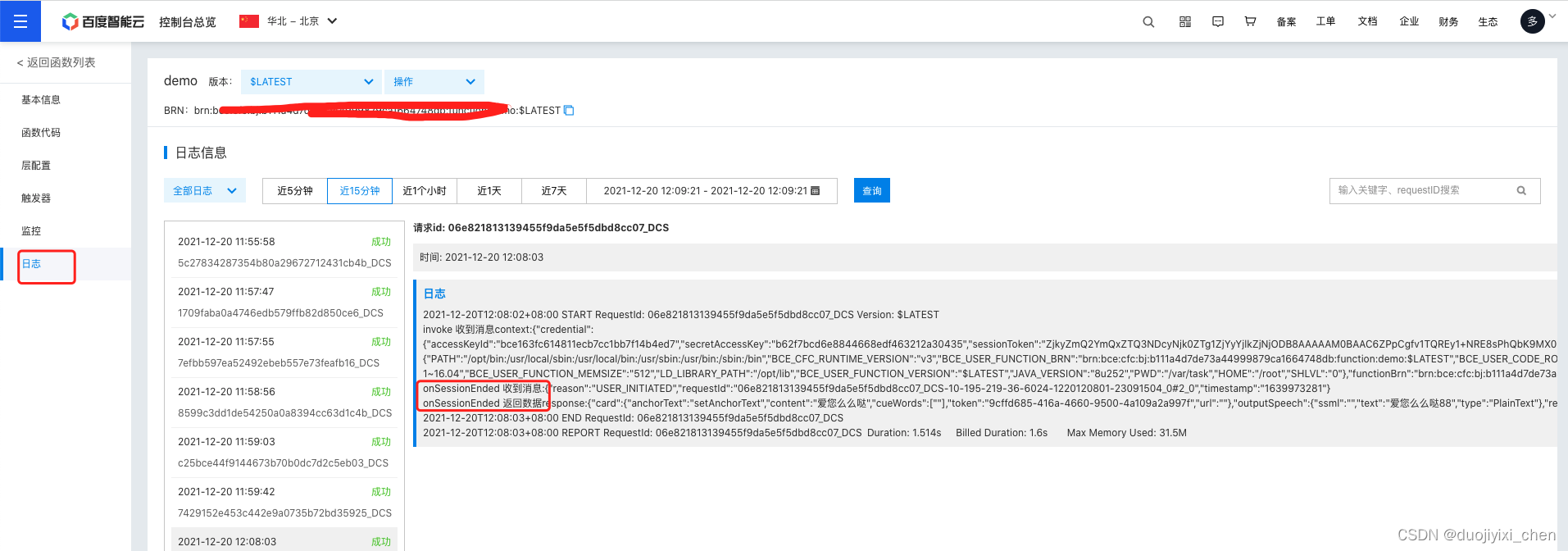
测试ok

















 3247
3247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









