








 超级会员免费看
超级会员免费看

 本文介绍了如何使用KWS(Keyword Spotting)实现自定义唤醒词的语音唤醒功能。通过编辑keywords_raw.txt文件并遵循特定规则定义唤醒词,然后运行代码生成keywords.txt文件。提供了一个GitHub链接及模型下载地址,帮助用户完成相关安装步骤,并指出了进一步功能实现的方向。
本文介绍了如何使用KWS(Keyword Spotting)实现自定义唤醒词的语音唤醒功能。通过编辑keywords_raw.txt文件并遵循特定规则定义唤醒词,然后运行代码生成keywords.txt文件。提供了一个GitHub链接及模型下载地址,帮助用户完成相关安装步骤,并指出了进一步功能实现的方向。
代码:https://github.com/k2-fsa/sherpa-onnx/blob/master/python-api-examples/keyword-spotter.py
模型下载:https://k2-fsa.github.io/sherpa/onnx/kws/pretrained_models/index.html
安装:
pip install sherpa-onnx>=1.9.11
1、自定义唤醒词
参考:https://k2-fsa.github.io/sherpa/onnx/kws/pretrained_models/index.html
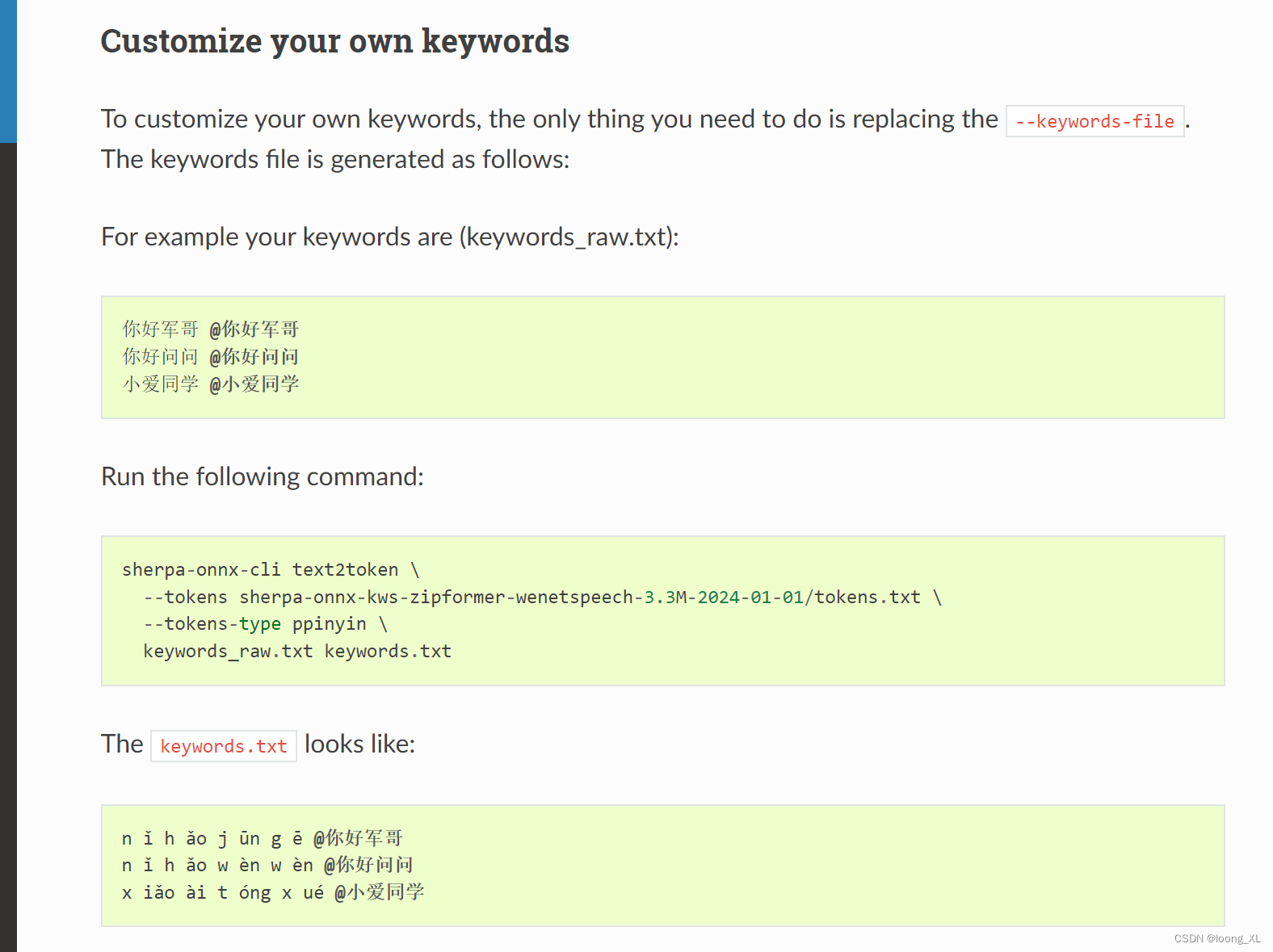
需要先编辑keywords_raw.txt文件,里面按规则自定义:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











