







『写在前面』
ImageNet分类SOTA,Transfer learning SOTA。提出一种放缩网络大小的方法,可以根据实际硬件条件进行调节,且该方法可以适用于当下几乎所有主流的分类模型中。
作者机构:Mingxing Tan等,Google Brain.
文章标题:《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》
原文链接:https://arxiv.org/pdf/1905.11946
相关repo:https: //github.com/tensorflow/tpu/tree/master/models/official/efficientnet
目录
5.1 在MobileNets和ResNes上试验复合缩放方法
摘要
CNN通常是在固定资源下开发的,若资源充足,则可以考虑放大模型以得到更高的精度,反之如果再移动端上进行运算,则可能需要考虑压缩模型。本文重点在于研究如何通过合适的方式缩放模型以平衡网络深度、宽度和分辨率从而得到更佳的性能。
首先NAS出一个baseline模型(EfficientNet-B0),然后使用复合缩放的方法获得一系列模型,称之为EfficientNets。
EfficientNet-B7达到新的SOTA,而且模型大小减少了8.4倍(相比GPipe),速度提高了6.1倍。
在CIFAR-100,Flowers等数据集上迁移效果也是SOTA,同时参数量减少了一个数量级。

1 介绍
基于广泛应用的一些分类模型,我们可能会在实际中根据资源条件对模型进行一些放缩,比如:增减网络层数、放大/缩小输入图像尺寸、增减网络中间层滤波器个数等。这种做法尽管有效,但并不高效,并且需要一些经验。本文作者出发点就是为了找到一种可以扩展CNN的原则,以实现更高的准确率或效率。结论是:提出了一种复合缩放方法,平衡网络宽度、深度与输入分辨率是关键,而且简单地以恒定比例缩放即可。
复合缩放方法简述:
如果想要使用倍的计算资源,那么可以通过同时将网络深度乘以
,宽度乘以
,图像大小乘以
来实现。其中,αβγ是通过在原始模型上通过small grid search确定的一组常数。
为什么复合缩放方法奏效?
直观来说,假如输入图像分辨率更大,也就需要更多层来扩大感受野,同时也需要更多的通道来捕捉更多的特征。反之亦然。
本文首先证明了提出的模型缩放方法在现有的CNN模型(MobileNets,ResNets等)上的有效性。因为模型扩展的有效性在很大程度上受baseline模型影响,所以又借助NAS开发了新的baseline,并使用提出的复合缩放方法进行扩展得到了一系列模型,统称为EfficientNets。最后结果是除了在ImageNet上达到了新的高度,还在广泛使用的8个公开迁移数据集上,5个达到SOTA。
2 相关工作
ConvNet 精度
| Model(Year) | ImageNet Acc | Parameters |
|---|---|---|
| GoogLeNet(2014) | 74.8% | 6.8M |
| SENet(2017) | 82.7% | 145M |
| GPipe(2018) | 84.3% | 557M |
虽然更高的精度对于许多应用来说至关重要,但不能一直增加模型参数量,因为我们已经达到硬件存储器限制,因此进一步提高精度需要更高的效率。
ConvNet 效率
在提高CNN模型有效性方面,有如下几种代表性工作:
- 为了减轻模型的参数冗余,进行模型压缩;
- 为了适用于移动端设备上,手工设计高效CNN网络,如SqueezeNets,MobileNets,ShuffleNets等;
- 基于NAS技术搜索高效网络结构,比如MNasNet,MobileNet-v3等。
ConvNet 模型缩放
通常来说,可以从三个方面入手进行对模型进行放缩:
- 增减深度,如Res-18,ResNet-200;
- 增减通道数,如MobileNets中的multiplier;
- 增减输入图像分辨率,提高图像分辨率有助于更好地进行分类,毋庸置疑。
本文工作旨在以一种统一的方式综合上述三方面来进行高效地放缩CNN模型。
3 复合模型缩放
3.1 问题建模
一个典型的卷积层可以定义为这样的函数形式:
而一个ConvNet可以表示为:
在现在流行的ConvNet中,大多都有数个stage,每个stage中的各层结构相仿,比如ResNet一般有5个stage,每个stage中除了第一个层负责下采样以外,其他层都是相同的卷积
因此,可以将这类ConvNet进一步表示为:
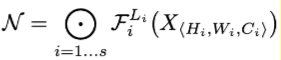
其中,表示在第
个stage中,
重复堆叠
次。
一般的卷积网络设计,旨在找到最好的结构,比如Inception、Residual Block、SE Module等等。与其不同,本文旨在不改变模型结构
的情况下,通过修改网络的深度、宽度、输入尺寸来进行模型放缩。
一句话概括,目标就是就是最大化任何给定资源约束情况的模型精度。
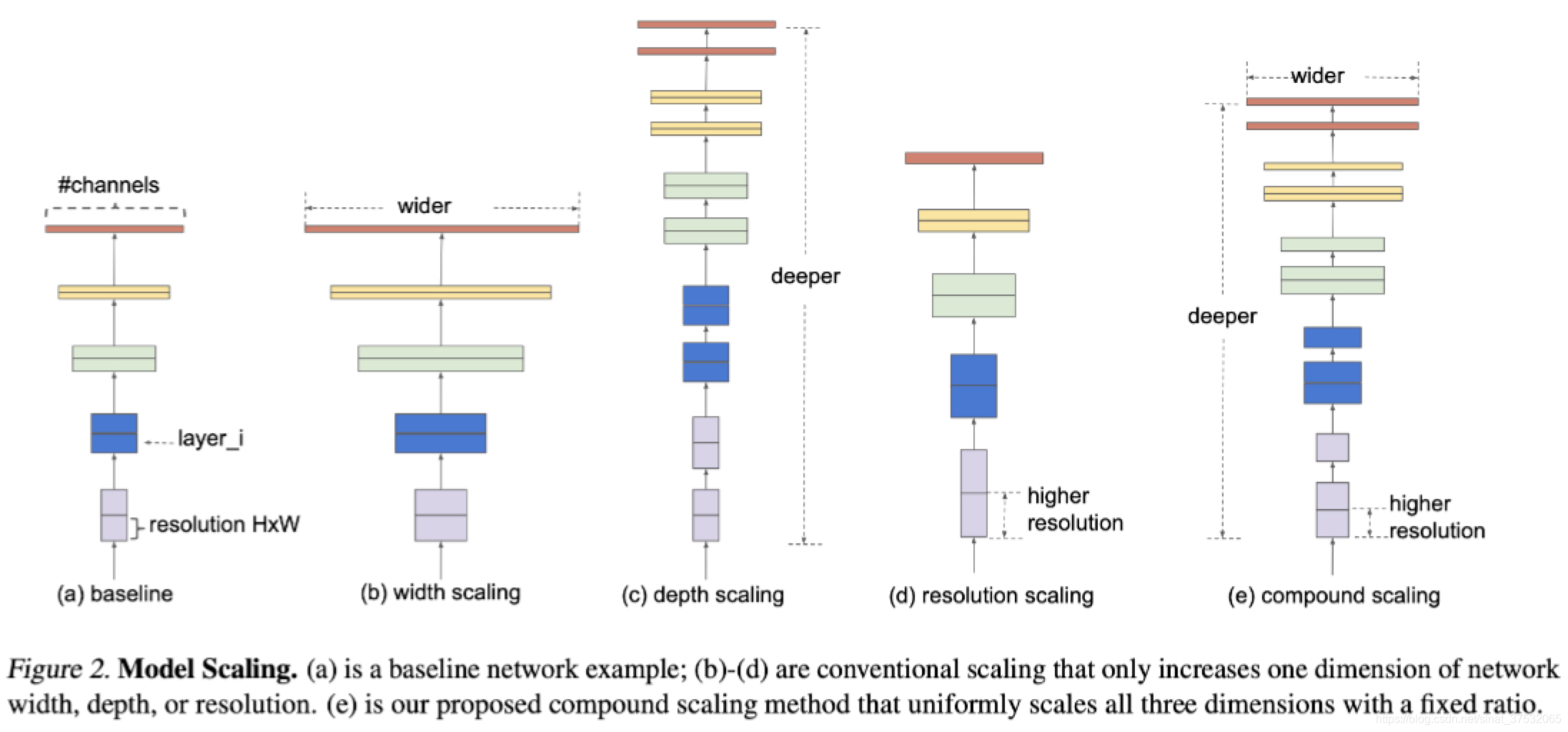
问题描述如下图所示:

3.2 维度缩放
上一节提出的问题,主要困难在于dwr三者相互依赖,并且在不同的资源约束下依赖关系也不同。出于这种影响,传统方法主要在其中某个维度做放缩来扩展ConvNet。
深度 Depth(d)
直观来说,越深的网络越利于捕捉丰富且复杂的特征,并且可更好地泛化到新任务上。
但由于梯度消失,训练难度也更大。通过跳跃连接、BN等操作,缓解了训练难的问题。
但网络精度并不会随着模型加深而不断提高,比如Res-1000和ResNet-101精度相当。
宽度 Width(w)
更宽的网络往往能够捕获更细粒度的特征,并且更容易训练。
然而极宽但浅的网络往往难以捕获高层特征。而且试验结果表明,随着w变大,准确度会迅速饱和。
分辨率 Resolution(r)
使用更高分辨率的输入图像,网络可以捕获更细粒度的特征。
分类模型从最早的224 * 224,到299 * 299,331 * 331,再到GPipe的480 * 480。检测模型一般使用更大的分辨率,比如600 * 600等。
越高的分辨率确实精度越高,但过高的话增益减小。
最后结论
作者使用EfficientNet-B0作为baseline,做了一系列试验,结果如下图所示。
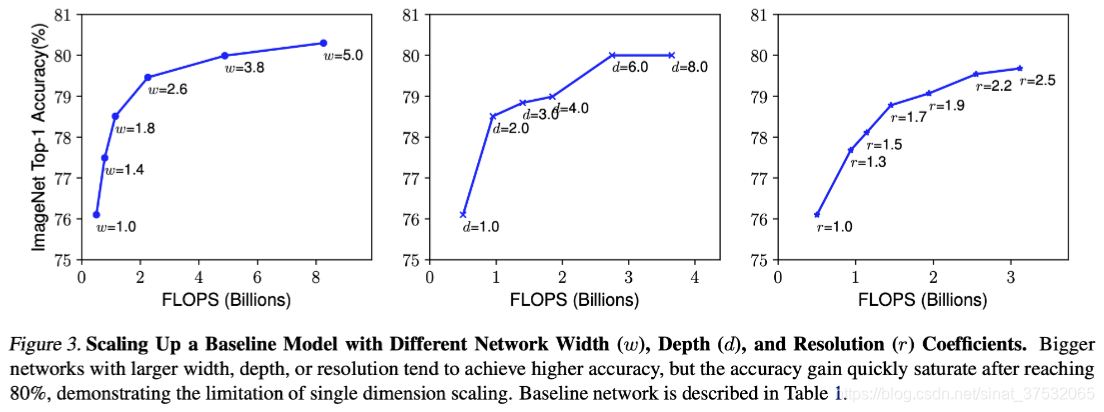
见解1 - 扩展WHR三者任意其一都可以提高准确性,但对于越大的模型而言,精度的增益会降低。
3.3 复合缩放
见解2 - 为了追求更高的准确性和效率,在ConvNet扩展期间平衡网络宽度,深度和分辨率的所有维度至关重要。
复合缩放方法解释
通过一个复合系数来统一地缩放W/D/R:

其中,α/β/γ是通过small grid search确定的常数。
注意一点,标准卷积OP的FLOPS正比于d,w²,r².因此,通过上面公式对卷积模型进行缩放,会将整体的FLOPS放缩倍。在本文中,令
,因此通过调节
可以将整体FLOPS放缩
倍。
4 EfficientNet 网络结构
因为模型缩放不会改变baseline,所以良好的baseline模型很关键。为了更好的展示本文提出的方法的有效性,开发了新的mobile-size的模型,EfficientNet。
通过NAS,搜索合适的结构以同时优化准确和FLOPS。值得一提的是,基于与MnasNet相同的搜索空间,并使用作为优化目标。其中,
和
分别表示模型
的准确率和运算量,
表示目标FLOPS,
是一个超参数来权衡Acc和FLOPS.
使用FLOPS作为优化目标,而不是延迟。是因为这里不依赖于任何特定的硬件设备,旨在找到一个最高效的网络,最终的搜索结果命名为EfficientNet-B0.
因为使用了与搜索MnasNet相同的搜索空间,所以除了EfficientNet-B0比较大以外,最终得到的模型结构也与MnasNet相似。因为这里设置的目标FLOPS是400M.
下图为EfficientNet-B0的模型结构,其基本构成单元是MBConv & SE.
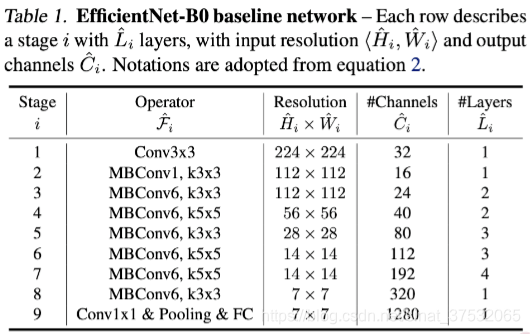
基于EfficientNet-B0,基于前面提出的复合缩放方法,通过以下两步来缩放它:
STEP-1: 首先固定,即假设有2倍资源可用,在前面提出的约束下,对αβγ进行小网格搜索,最终得到
,
,
是最优值。
STEP-2: 然后固定,按上述复合缩放方法带入不同的
进行放缩,得到B1-B7。
需要注意的是,在大模型上搜索可以得到更高的精度,但是代价过大,所以本文仅在小baseline模型上进行了一次搜索,然后其他模型都是通过复合放缩得到的。
5 实验
5.1 在MobileNets和ResNes上试验复合缩放方法
实验结果如下表所示。可以看出,不论是对MobileNets还是ResNets,通过复合缩放方法,都可以得到明显的精度提升。并且,与通过单一缩放网络深度、宽度、分辨率相比,可以在相当的FLOPS达到更高的精度。

5.2 EfficientNet在ImageNet上的表现
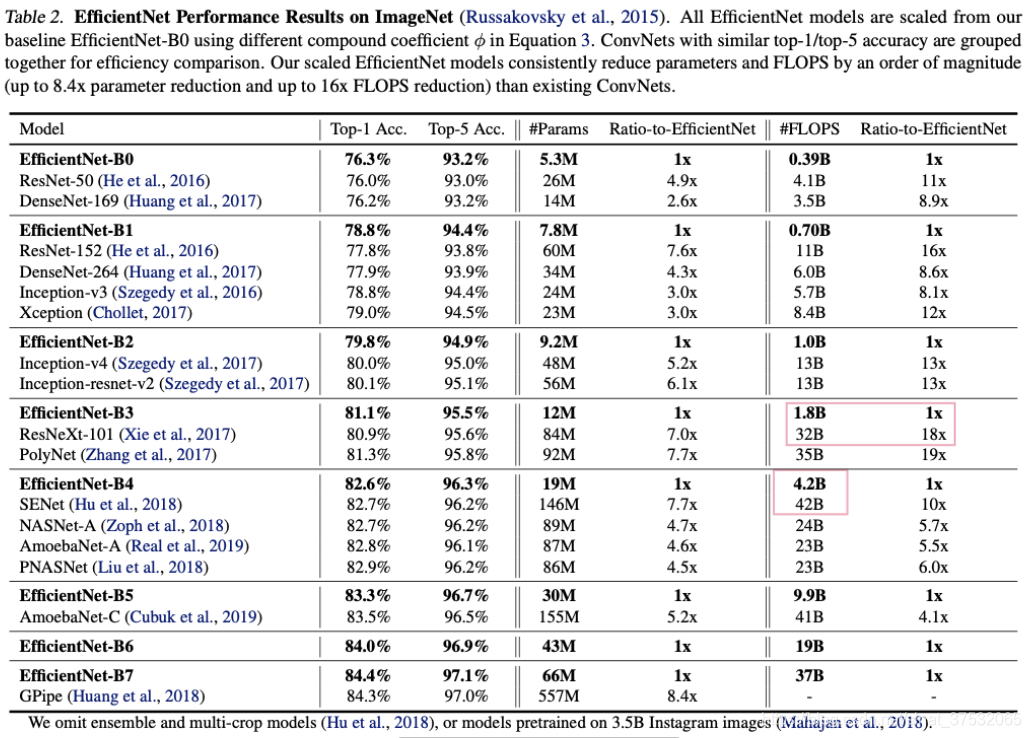
简而言之就是全面超越现有各种不同时期的分类网络。比如:
- EfficientNet-B3与ResNeXt-101精度相当,但模型参数量仅为后者的七分之一,FLOPS仅为后者的18分之一。
- EfficientNet-B4与SENet相比,精度相当,但FLOPS仅为后者的十分之一。
- EfficientNet-B7超越GPipe,成为新的SOAT,但后者模型参数量是它的8.4倍。
5.3 迁移学习表现
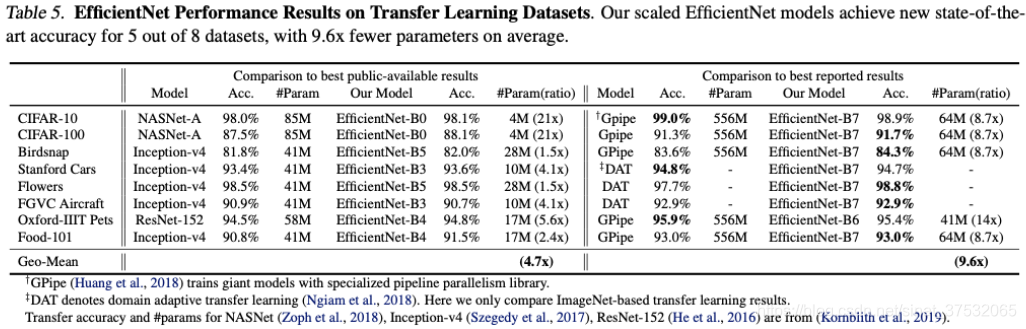
在8个常用迁移学习数据集上,5个达到了新的高度。
6 讨论
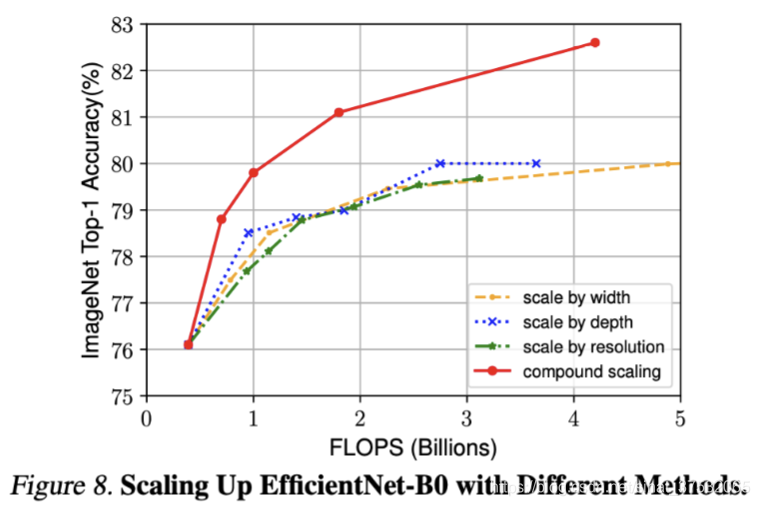
复合缩放与单一维度缩放比较如下图所示,可以看出明显的差距。
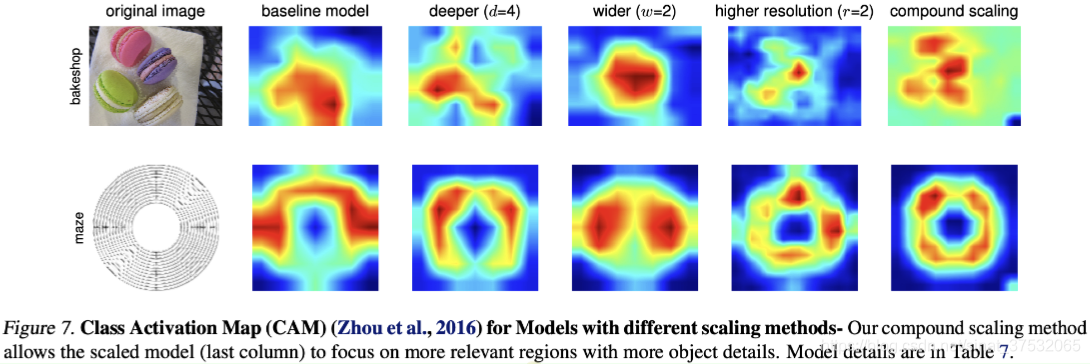
CAM可视化分析如下图所示。定性来说,基于复合缩放的模型更倾向于关注具有更多对象细节的相关区域。而其他缩放方法,要么缺少细节,要么无法捕获所有对象。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









