







数据预处理-样本分布(正态分布、偏态分布)
转载自:
https://blog.csdn.net/lanchunhui/article/details/53239441
https://www.cnblogs.com/gczr/p/6802998.html
一、何为数据的偏态分布?
频数分布有正态分布和偏态分布之分。正态分布是指多数频数集中在中央位置,两端的频数分布大致对称。
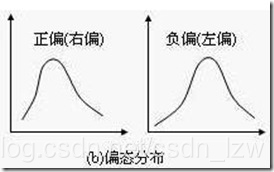
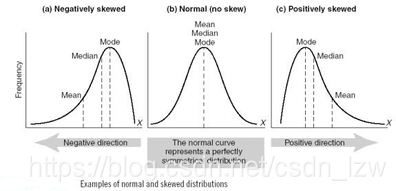
偏态分布是指频数分布不对称,集中位置偏向一侧。若集中位置偏向数值小的一侧,称为正偏态分布;集中位置偏向数值大的一侧,称为负偏态分布。
如果频数分布的高峰向左偏移,长尾向右侧延伸称为正偏态分布,也称右偏态分布;同样的,如果频数分布的高峰向右偏移,长尾向左延伸则成为负偏态分布,也称左偏态分布。
峰左移,右偏,正偏 偏度大于0
峰右移,左偏,负偏 偏度小于0
二、构建模型时为什么要尽量将偏态数据转换为正态分布数据?
数据整体服从正态分布,那样本均值和方差则相互独立。正态分布具有很多好的性质,很多模型假设数据服从正态分布。例如线性回归(linear regression),它假设误差服从正态分布,从而每个样本点出现的概率就可以表示成正态分布的形式,将多个样本点连乘再取对数,就是所有训练集样本出现的条件概率,最大化这个条件概率就是LR要最终求解的问题。这里这个条件概率的最终表达式的形式就是我们熟悉的误差平方和。总之, ML中很多model都假设数据或参数服从正态分布。
三:如何检验样本是否服从正态分布?
可以使用Q-Q图来进行检验
https://baike.baidu.com/item/Q-Q图
统计学里Q-Q图(Q代表分位数)是一个概率图,用图形的方式比较两个概率分布,把他们的两个分位数放在一起比较。首先选好分位数间隔。图上的点(x,y)反映出其中一个第二个分布(y坐标)的分位数和与之对应的第一分布(x坐标)的相同分位数。因此,这条线是一条以分位数间隔为参数的曲线。
如果两个分布相似,则该Q-Q图趋近于落在y=x线上。如果两分布线性相关,则点在Q-Q图上趋近于落在一条直线上,但不一定在y=x线上。Q-Q图可以用来可在分布的位置-尺度范畴上可视化的评估参数。
由于P-P图和Q-Q图的用途完全相同,只是检验方法存在差异。要利用QQ图鉴别样本数据是否近似于正态分布,只需看QQ图上的点是否近似地在一条直线附近,而且该直线的斜率为标准差,截距为均值.
四 :如果不是正态分布怎么办?
数据右偏的话可以对所有数据取对数、取平方根等,它的原理是因为这样的变换的导数是逐渐减小的,也就是说它的增速逐渐减缓,所以就可以把大的数据向左移,使数据接近正态分布。
如果左偏的话可以取相反数转化为右偏的情况。
五、Box-Cox
https://blog.csdn.net/lcmssd/article/details/80179102?utm_source=blogxgwz0
参加kaggle比赛过程中,看到很多人在预处理阶段会对某些特征X做如下操作 Y = log(1+X), 说是可以把这个特征的分布正态化, 使其更加符合后面数据挖掘方法对数据分布的假设
y = (x**lmbda - 1) / lmbda, for lmbda > 0
log(x), for lmbda = 0
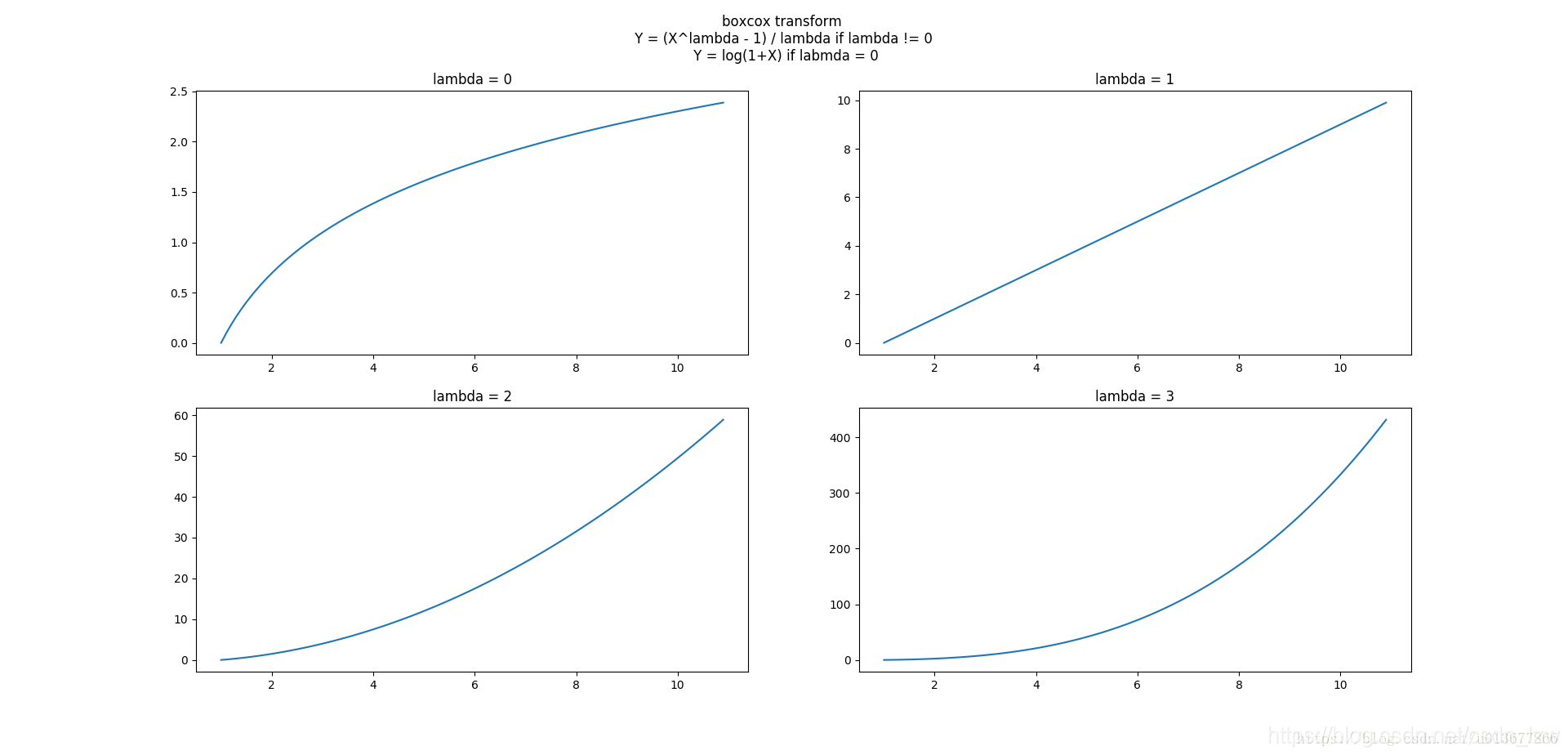
上图lambda取不同值时, (X,Y)的曲线, boxcox变换的工作原理就在这些曲线的斜率中: 曲线斜率越大的区域,则对应区域的X变换后将被拉伸, 变换后这段区域的方差加大; 曲线斜率越小的区域, 对应区域的X变换后将被压缩, 变换后这段区域的方差变小.
右图中看出lambda = 0时, 取值较小的部分被拉伸, 取值较大的部分被压缩; lambda > 1时则相反
http://onlinestatbook.com/2/transformations/box-cox.html














 1486
1486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









