







Provably Robust Recommender Systems against Data Poisoning Attacks
摘要
数据中毒攻击欺骗了一个推荐系统,通过向推荐系统中注入精心设计的评分分数,从而做出任意的、攻击者想要的建议。我们设想一个猫捉老鼠的游戏,这样的数据中毒攻击和他们的防御,也就是说,新的防御被设计来防御现有的攻击,新的攻击被设计来打破它们。为了防止这种猫捉老鼠的游戏,我们提出了PORE,本工作是第一个构建可证明的鲁棒推荐系统的框架。PORE可以将任何现有的推荐系统转换为对任何非目标数据中毒攻击的稳健性,其目的是降低推荐系统的整体性能。假设PORE在没有攻击时向用户推荐top-N项。我们证明了在任何数据中毒攻击下,PORE仍然至少向用户推荐N个项目中的r个,其中r是攻击中假用户数量的函数。此外,我们还为每个用户设计了一个有效的计算机算法。我们在流行的基准数据集上对PORE进行了实证评估。
一、引言
许多web服务平台(例如,亚马逊、YouTube和抖音)利用推荐系统来吸引用户并改善用户体验。通常,一个平台首先收集大量用户给项目的评分,这被称为评分-分数矩阵。然后,该平台利用它们来构建一个推荐系统,以模拟用户兴趣和项目属性之间的复杂关系。最后,推荐系统向每个用户推荐符合其兴趣的前n项。
但是,由于推荐系统的开放性,即任何人都可以注册用户并对项目提供评分,因此推荐系统对数据中毒攻击[11,12,18,22,23,27,42]根本不是很健壮的。具体来说,在数据中毒攻击中,攻击者会在推荐系统中创建虚假用户并为各个项目分配精心设计的评分。不同的数据中毒攻击本质上使用不同的方法来伪造虚假用户的评分。当推荐系统是基于毒-评分矩阵,其中包括真实和假用户的评分分数时,它向用户推荐攻击者选择的任意前n项目。因此,推荐性能(例如,精度@N、Recall@N和F1-Score@N)会大大降低。数据中毒攻击对推荐系统的鲁棒性/安全性提出了严重的挑战
为了提高推荐系统对数据中毒攻击的鲁棒性,人们提出了许多防御方法。特别是,[7,12,41,44,47]的一个防御家族旨在在建立推荐系统之前检测虚假用户。这些方法依赖于这样一个假设,即虚假用户和真实用户的评分分数有统计上不同的模式,它们利用这些模式来区分虚假用户和真实用户。[8,17,25,26,30,35,43]的另一个家族的目标是设计新的训练推荐系统的方法,即使他们在中毒的评级分数矩阵上进行训练,例如,使用修剪学习[17]。然而,这些防御只能实现经验的鲁棒性,导致攻击和防御之间无休止的猫捉老鼠游戏:一种新的经验防御被提出来减轻现有的攻击,但可以被适应防御的新攻击所打破。例如,虚假用户可以调整他们的评分分数,这样他们就不能基于评分分数的统计模式[11,12,18]被检测到。因此,推荐系统的性能仍然被强大的自适应攻击大大下降。
我们的工作:在这项工作中,我们的目标是通过提出PORE来结束这种猫捉老鼠的游戏,这是第一个构建可证明的健壮的推荐系统的框架,以对抗任何非目标的数据中毒攻击。假设在没有攻击的情况下,推荐系统算法在一个干净的评分矩阵上训练推荐系统,该矩阵向用户u推荐一组前n项(表示为Γu)。在攻击下,推荐系统算法在中毒评分矩阵上训练推荐系统,该矩阵向用户推荐一组前n项(记为Γ‘u)。我们说,如果Γu和Γ‘u之间的交集包含至少r项,当最多有假用户时,对于用户u,无论攻击者如何制作假用户的鲁棒性。换句话说,一个(e,r)可证明健壮的推荐系统保证了推荐的前n项中至少有r不受虚假用户的影响,无论他们使用什么评分。我们注意到r取决于假用户的数量e,我们称之为r认证的交集大小。一个可证明的鲁棒推荐系统可以保证在任何数据中毒攻击下的推荐性能的下界,即,无论假用户如何制作他们的评分分数。
假设一个子矩阵由评分-分数矩阵中的s个行组成,即,一个子矩阵包含s个用户的评分分数。直观地说,当虚假用户的比例有界时,一个随机抽样的子矩阵很可能不包含虚假用户,因此基于该子矩阵建立的推荐系统不受虚假用户的影响。基于这种直觉,PORE使用bagging[5],一种著名的集成方法,来实现可证明的鲁棒性。特别是,PORE聚合了来自多个基本推荐系统的建议,以向每个用户推荐top-N项。具体地说,我们可以使用任何推荐系统算法(称为基本算法)来在一个子矩阵上建立一个推荐系统(称为基本推荐系统)。因此,我们可以建立(n s)基推荐系统,因为有(n s)子矩阵,其中n是用户总数。每个基础推荐系统都会向用户提出推荐。我们用pi表示向用户u推荐项目i的(n s)基本推荐系统的分数。我们把它称为项目概率。1 PORE向用户u推荐项目概率最大的前n个项目。
我们的主要理论结果是,我们证明了PORE是可证明的(e,r)鲁棒的。此外,对于任意给定数量的假用户e,我们推导出每个真实用户的认证交集大小r,这是一个优化问题的解决方案。PORE依赖于项目的概率pi来提出建议。此外,计算r的优化问题也涉及到项目概率。然而,计算精确的项目概率是具有挑战性的,因为它需要建立(n s)基础推荐系统。为了解决这一挑战,我们设计了一种有效的算法,通过建立T≪(n s)基推荐系统来估计项目概率的下界/上界,其中T基推荐系统可以并行建立。PORE在实践中根据估计的项目概率提出建议。此外,我们利用估计的项目概率来解决优化问题,得到每个用户的r。我们在三个基准数据集上对PORE进行了实证评估,即Movie镜头-100k、电影镜头-1M和Movie电影镜头-10M。此外,我们考虑了两种最先进的基础算法,即基于项目的推荐(IR)[3]和贝叶斯个性化排序(BPR)[29],以显示PORE的通用性。我们还推广了机器学习分类器的鲁棒防御[19]来推荐系统,并与PORE进行了比较。从我们的实验结果中,我们有三个关键的观察结果。
首先,PORE大大优于分类器的广义防御。
其次,当没有数据中毒攻击时,PORE具有建立在整个评分矩阵上的标准推荐系统(即精度@N、召回@N和F1-Score@N)。
第三,在任何数据中毒攻击下,PORE都可以保证推荐性能的下界,而标准的推荐系统则不能。
我们的主要贡献总结如下:
•我们提出了PORE,第一个构建推荐系统的框架,该系统具有针对非目标数据中毒攻击的鲁棒性。
•证明了PORE的鲁棒性保证,并推导了其证明的交集大小。此外,我们还设计了一种算法来计算经认证的交集大小。
•我们使用两种最先进的基准推荐系统算法对流行的基准数据集进行广泛的评估。
二、背景

图1:左:没有数据中毒攻击的推荐系统。右图:攻击者注入虚假用户u5以操控u1和u3
2.1推荐系统
评分矩阵
Top- N 推荐项目
推荐器系统算法:已经提出了许多算法来构建推荐系统,例如基于项目的推荐(IR)[31,24,3],贝叶斯个性化排名(BPR)[ 29],矩阵分解[ 21],神经协同过滤(NCF)[ 16]和LightGCN [ 15]。例如,IR基于不同项目的评级分数来计算它们之间的相似性,使用这样的相似性来预测用户的缺失评级分数,并且向用户推荐用户尚未评级但具有最大预测评级分数的 N 项目。由于其可扩展性,IR已被广泛部署在工业中,例如,亚马逊[ 24].根据微软最近发布的基准测试[ 2],BPR达到了最先进的性能,例如,BPR甚至优于更复杂的算法,如NCF [ 16]和LightGCN [ 15]。
2.2数据中毒攻击
许多研究[ 22,27,23,42,12,11,18]表明,推荐系统对数据中毒攻击不鲁棒(第6节讨论了更多细节)。在数据中毒攻击中,攻击者在推荐系统中创建虚假用户,并为他们分配精心制作的评级分数,使得基于真实和虚假用户的评级分数构建的推荐系统做出攻击者期望的任意推荐。例如,数据中毒攻击可以显著降低推荐系统的性能;并且数据中毒攻击可以促进某些项目(例如,YouTube上的视频和亚马逊上的产品)通过欺骗推荐系统将它们推荐给许多真正的用户。图1说明了数据中毒攻击。
我们用 𝐌′ 表示中毒评级得分矩阵。数据中毒攻击旨在通过精心设计虚假用户的评分来减少 𝒜(𝐌,u) 和 𝒜(𝐌′,u) 之间的交集。不同的攻击本质上为虚假用户分配不同的评级分数。
三、问题表述
威胁模型:我们假设攻击者可以通过注册和维护虚假帐户将虚假用户注入推荐系统[ 36]。我们认为攻击者最多可以向推荐系统注入 e 个虚假用户,例如,因为注册和维护假账户的资源有限。然而,我们假设每个假用户可以任意地对攻击者想要的尽可能多的项目进行评级。此外,我们假设攻击者具有对推荐系统的白盒访问,例如,攻击者可以访问所有真实用户的评级分数以及推荐系统算法及其参数。换句话说,我们考虑强大的攻击者,他们可以执行任何数据中毒攻击。
中毒评级分数矩阵 𝐌′ 将评级分数矩阵 𝐌 扩展最多 e 行,其对应于最多 e 个虚假用户的评级分数。不同的数据中毒攻击本质上为虚假用户选择不同的评级分数,并导致不同的中毒评级分数矩阵 𝐌′ 。我们使用 ℒ(𝐌,e) 来表示当干净的评分矩阵为 𝐌 并且虚假用户的数量至多为 e 时所有可能的中毒评分矩阵的集合。 ℒ(𝐌,e) 基本上表示所有可能的数据中毒攻击,最多有 e 个假用户。形式上,我们定义 ℒ(𝐌,e) 如下:
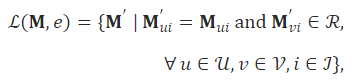 (1)
(1)
其中 ℛ 是评级分数的域, 𝒰 是真实用户的集合, 𝒱 是至多 e 个假用户的集合(即, |𝒱|≤ e ), ℐ 是项的集合。
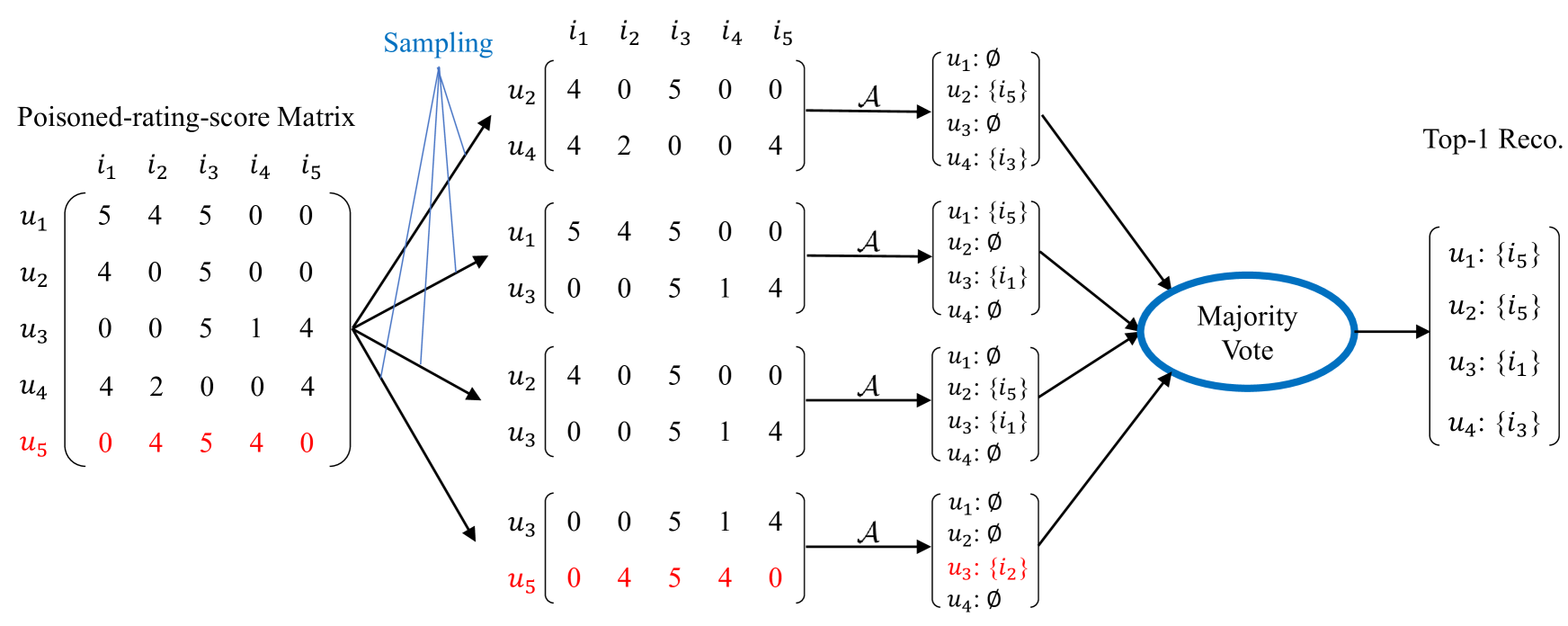
图2:我们的集成推荐系统对数据中毒攻击的鲁棒性。
可证明鲁棒的推荐系统算法:如果推荐系统算法为用户推荐的一定数量的前 N 项可证明不受任何数据中毒攻击的影响,则我们说推荐系统算法可证明对数据中毒攻击是鲁棒的。具体地,给定一组项目 ℐu ,我们说推荐系统算法 𝒜 对于用户u 是可证明鲁棒的,如果它满足以下属性:
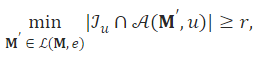 (2)
(2)
其中 ℒ(𝐌,e) 是所有可能的中毒评级分数矩阵的集合(即,所有可能的数据中毒攻击,最多有e 假用户), |ℐu∩𝒜(𝐌′,u)| 是在攻击下推荐给 u 的 ℐu 和前 N 项之间的交集的大小, 𝒜 被称为认证交集大小。请注意, r 可能依赖于用户 u 和假用户e 的数量,但为了简单起见,我们省略了它对 u 和 e 的显式依赖性。
当 ℐu 是在没有攻击的情况下由 𝒜 推荐给用户 u的前 N 项的集合时,即, ℐu=𝒜(𝐌,u) ,我们可证明的鲁棒性意味着 𝒜(𝐌,u) 中的 N 项中至少有 r 项在最多有 e 假用户的任何攻击下仍然被推荐给 u 。当 ℐu 是用于 u 的实况测试项的集合(即, u 确实感兴趣的项目集),我们可证明的鲁棒性意味着至少 r 的真实测试项目在攻击下被推荐给 u 。正如我们将在实验中讨论的更多细节,在后一种情况下, r 可以用于导出推荐性能的下限,例如在任何数据中毒攻击下的Precision@ N ,Recall@ N 和F1-Score@ N 。我们正式定义了一个可证明鲁棒的推荐系统算法如下:
定义1( (e,r) -可证明鲁棒的推荐系统)。假设虚假用户的数量最多为 e ,并且数据中毒攻击可以任意地为虚假用户制作评级分数。我们说推荐系统算法 𝒜 对于用户 u 是 (e,r) 可证明鲁棒的,如果其用于 u 的认证交集大小至少是 r ,即,如果满足等式(2)。
四、PORE
4.1概述
我们的关键直觉是,当虚假用户的数量有界时,少量用户的随机子集可能只包括真正的用户。因此,使用这样的随机用户子集的评级分数构建的推荐系统不受虚假用户的影响。基于直觉,PORE使用随机的用户子集构建多个推荐系统,并在其中进行多数投票以向用户推荐项目。
具体来说,我们从评分矩阵中创建多个子矩阵,其中每个子矩阵包含 s 个随机选择的不同用户的评分,即,s 从评分矩阵中随机选择的行。然后,我们使用一个任意的基算法来建立一个推荐系统(称为基推荐系统)的每个子矩阵,并使用它来推荐项目的用户。最后,我们建立了一个集成推荐系统,它采取了大多数投票的基础推荐系统作为最终推荐项目为每个用户。图2显示了我们的集成推荐系统及其对数据中毒攻击的鲁棒性。
接下来,我们首先在PORE中正式定义了我们的集成推荐系统。然后,我们证明了PORE对数据中毒攻击具有可证明的鲁棒性。特别是,给定用户 u 的任意一组项目 ℐu ,我们证明了在任何数据中毒攻击下,PORE推荐给 u 的前N 项中至少有 r 项保证在 ℐu 中。此外,我们推导出认证的交集大小 r 。最后,我们设计了一个算法来同时计算所有用户的认证交集大小 r 。


















 735
735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









