







电信保温杯笔记——《统计学习方法(第二版)——李航》第9章 EM算法及其推广
论文
EM算法:《Maximum Likelihood from Incomplete Data Via the EM Algorithm》
GEM算法:《A view of the EM algorithm that justifies incremental, sparse, and other variants》
介绍
电信保温杯笔记——《统计学习方法(第二版)——李航》
本文是对原书的精读,会有大量原书的截图,同时对书上不详尽的地方进行细致解读与改写。


EM算法
原理:定义一个
Q
(
θ
,
θ
(
i
)
)
Q(\theta, \theta^{(i)} )
Q(θ,θ(i)) 函数,求
Q
(
θ
,
θ
(
i
)
)
Q(\theta, \theta^{(i)} )
Q(θ,θ(i)) 最大值时的
θ
\theta
θ,同时又令它为
θ
(
i
+
1
)
\theta^{(i+1)}
θ(i+1),并将
θ
(
i
+
1
)
\theta^{(i+1)}
θ(i+1) 带入
Q
Q
Q 函数,再求
Q
(
θ
,
θ
(
i
+
1
)
)
Q(\theta, \theta^{(i+1)} )
Q(θ,θ(i+1)) 最大值时的
θ
\theta
θ,经过多次迭代后,可得到
P
(
y
∣
θ
)
P(y|\theta)
P(y∣θ)。

电信保温杯笔记——《统计学习方法(第二版)——李航》第4章 朴素贝叶斯法中的数学基础里,有最大后验概率估计和极大似然估计的解释。
下面例子中, A , B , C , π , p , q A,B,C,\pi,p,q A,B,C,π,p,q 就是隐藏变量,正反面就是观测值。每一个观测值只源于模型 B,C,而模型B,C 发生的只取决于A。
例子



步骤

Q
(
θ
,
θ
(
i
)
)
=
E
Z
[
log
P
(
Y
,
Z
∣
θ
)
∣
Y
,
θ
(
i
)
]
=
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
log
P
(
Y
,
Z
∣
θ
)
(
9.9
)
\begin{aligned} Q(\theta,\theta^{(i)} ) &= E_Z[ \log P(Y,Z|\theta) |Y, \theta^{(i)} ] \\ &= \sum_Z P(Z|Y, \theta^{(i)}) \log P(Y,Z|\theta) \quad\quad\quad\quad\quad\quad\quad\quad\quad (9.9) \end{aligned}
Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]=Z∑P(Z∣Y,θ(i))logP(Y,Z∣θ)(9.9)

推导

λ
j
=
P
(
Z
∣
Y
,
θ
(
i
)
)
,
y
j
=
P
(
Y
∣
Z
,
θ
)
P
(
Z
∣
θ
)
P
(
Z
∣
Y
,
θ
(
i
)
)
\lambda_j = P(Z|Y,\theta^{(i)}),y_j = \frac{ P(Y|Z,\theta) P(Z|\theta) }{ P(Z|Y, \theta^{(i)}) }
λj=P(Z∣Y,θ(i)),yj=P(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ)
L
(
θ
)
−
L
(
θ
(
i
)
)
=
log
(
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
P
(
Y
∣
Z
,
θ
)
P
(
Z
∣
θ
)
P
(
Z
∣
Y
,
θ
(
i
)
)
)
−
log
P
(
Y
∣
θ
(
i
)
)
≥
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
log
P
(
Y
∣
Z
,
θ
)
P
(
Z
∣
θ
)
P
(
Z
∣
Y
,
θ
(
i
)
)
−
log
P
(
Y
∣
θ
(
i
)
)
=
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
log
P
(
Y
∣
Z
,
θ
)
P
(
Z
∣
θ
)
P
(
Z
∣
Y
,
θ
(
i
)
)
−
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
log
P
(
Y
∣
θ
(
i
)
)
=
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
log
P
(
Y
∣
Z
,
θ
)
P
(
Z
∣
θ
)
P
(
Z
∣
Y
,
θ
(
i
)
)
P
(
Y
∣
θ
(
i
)
)
\begin{aligned} L(\theta ) - L(\theta^{(i)} ) &= \log \left( \sum_Z P(Z|Y,\theta^{(i)}) \frac{ P(Y|Z,\theta) P(Z|\theta) }{ P(Z|Y, \theta^{(i)}) } \right) - \log P(Y| \theta^{(i)}) \\ &\ge \sum_Z P(Z|Y,\theta^{(i)}) \log \frac{ P(Y|Z,\theta) P(Z|\theta) }{ P(Z|Y, \theta^{(i)}) } - \log P(Y| \theta^{(i)}) \\ &= \sum_Z P(Z|Y,\theta^{(i)}) \log \frac{ P(Y|Z,\theta) P(Z|\theta) }{ P(Z|Y, \theta^{(i)}) } - \sum_Z P(Z|Y,\theta^{(i)}) \log P(Y| \theta^{(i)}) \\ &= \sum_Z P(Z|Y,\theta^{(i)}) \log \frac{ P(Y|Z,\theta) P(Z|\theta) }{ P(Z|Y, \theta^{(i)}) P(Y| \theta^{(i)}) } \end{aligned}
L(θ)−L(θ(i))=log(Z∑P(Z∣Y,θ(i))P(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ))−logP(Y∣θ(i))≥Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ)−logP(Y∣θ(i))=Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ)−Z∑P(Z∣Y,θ(i))logP(Y∣θ(i))=Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)
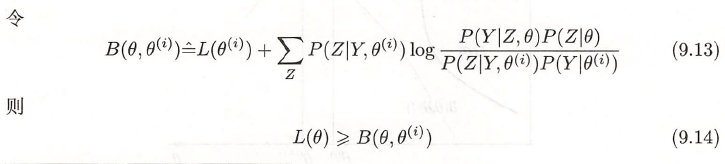

Q
(
θ
,
θ
(
i
)
)
=
E
Z
[
log
P
(
Y
,
Z
∣
θ
)
∣
Y
,
θ
(
i
)
]
=
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
log
P
(
Y
,
Z
∣
θ
)
(
9.9
)
\begin{aligned} Q(\theta,\theta^{(i)} ) &= E_Z[ \log P(Y,Z|\theta) |Y, \theta^{(i)} ] \\ &= \sum_Z P(Z|Y, \theta^{(i)}) \log P(Y,Z|\theta) \quad\quad\quad\quad\quad\quad\quad\quad\quad (9.9) \end{aligned}
Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]=Z∑P(Z∣Y,θ(i))logP(Y,Z∣θ)(9.9)


收敛性
感觉这一部分可以不用看,直接看GEM算法。




GEM算法

高斯混合模型

α k , σ k \alpha_k,\sigma_k αk,σk 决定每个高斯模型的高矮肥瘦。
使用EM算法估计高斯混合模型的参数

1. 明确隐变量,写出完全数据的对数似然函数

P
(
y
,
γ
∣
θ
)
=
∏
j
=
1
N
P
(
y
j
,
γ
j
1
,
γ
j
2
,
⋯
,
γ
j
K
∣
θ
)
=
∏
j
=
1
N
∏
k
=
1
K
[
α
k
ϕ
k
(
y
j
∣
θ
k
)
]
γ
j
k
=
∏
k
=
1
K
∏
j
=
1
N
α
k
γ
j
k
[
ϕ
k
(
y
j
∣
θ
k
)
]
γ
j
k
=
∏
k
=
1
K
α
k
∑
j
=
1
N
γ
j
k
∏
j
=
1
N
[
ϕ
k
(
y
j
∣
θ
k
)
]
γ
j
k
\begin{aligned} P(y, \gamma | \theta ) &= \prod\limits_{j = 1}^N P(y_j, \gamma_{j1},\gamma_{j2}, \cdots, \gamma_{jK} | \theta) \\ &= \prod\limits_{j = 1}^N \prod\limits_{k = 1}^K [\alpha_k \phi_k(y_j | \theta_k) ]^{\gamma_{jk}} \\ &= \prod\limits_{k = 1}^K \prod\limits_{j = 1}^N \alpha_k^{\gamma_{jk}} [ \phi_k(y_j | \theta_k) ]^{\gamma_{jk}} \\ &= \prod\limits_{k = 1}^K \alpha_k^{\sum\limits_{j = 1}^N \gamma_{jk}} \prod\limits_{j = 1}^N [ \phi_k(y_j | \theta_k) ]^{\gamma_{jk}} \\ \end{aligned}
P(y,γ∣θ)=j=1∏NP(yj,γj1,γj2,⋯,γjK∣θ)=j=1∏Nk=1∏K[αkϕk(yj∣θk)]γjk=k=1∏Kj=1∏Nαkγjk[ϕk(yj∣θk)]γjk=k=1∏Kαkj=1∑Nγjkj=1∏N[ϕk(yj∣θk)]γjk
那么,完全数据的对数似然函数为
log P ( y , γ ∣ θ ) = log [ ∏ k = 1 K α k ∑ j = 1 N γ j k ∏ j = 1 N [ ϕ k ( y j ∣ θ k ) ] γ j k ] = ∑ k = 1 K { ∑ j = 1 N γ j k log α k + ∑ j = 1 N γ j k [ log ( 1 2 π ) − log σ k − 1 2 σ k 2 ( y j − μ k ) 2 ) ] } \begin{aligned} \log P(y, \gamma | \theta ) &= \log \left[ \prod\limits_{k = 1}^K \alpha_k^{\sum\limits_{j = 1}^N \gamma_{jk}} \prod\limits_{j = 1}^N [ \phi_k(y_j | \theta_k) ]^{\gamma_{jk}} \right] \\ &= \sum\limits_{k = 1}^K \left\{ \sum\limits_{j = 1}^N \gamma_{jk} \log \alpha_k + \sum\limits_{j = 1}^N \gamma_{jk} \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \log \sigma_k - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} \\ \end{aligned} logP(y,γ∣θ)=log⎣ ⎡k=1∏Kαkj=1∑Nγjkj=1∏N[ϕk(yj∣θk)]γjk⎦ ⎤=k=1∑K{j=1∑Nγjklogαk+j=1∑Nγjk[log(2π1)−logσk−2σk21(yj−μk)2)]}
2. EM算法的E步:确定Q函数
Q
(
θ
,
θ
(
i
)
)
=
E
Z
[
log
P
(
Y
,
Z
∣
θ
)
∣
Y
,
θ
(
i
)
]
=
∑
Z
P
(
Z
∣
Y
,
θ
(
i
)
)
log
P
(
Y
,
Z
∣
θ
)
(
9.9
)
\begin{aligned} Q(\theta,\theta^{(i)} ) &= E_Z[ \log P(Y,Z|\theta) |Y, \theta^{(i)} ] \\ &= \sum_Z P(Z|Y, \theta^{(i)}) \log P(Y,Z|\theta) \quad\quad\quad\quad\quad\quad\quad\quad\quad (9.9) \end{aligned}
Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]=Z∑P(Z∣Y,θ(i))logP(Y,Z∣θ)(9.9)
Z
=
γ
Z = \gamma
Z=γ
Q
(
θ
,
θ
(
i
)
)
=
E
[
log
P
(
y
,
γ
∣
θ
)
∣
y
,
θ
(
i
)
]
=
E
{
∑
k
=
1
K
{
∑
j
=
1
N
γ
j
k
log
α
k
+
∑
j
=
1
N
γ
j
k
[
log
(
1
2
π
)
−
log
σ
k
−
1
2
σ
k
2
(
y
j
−
μ
k
)
2
)
]
}
}
=
∑
k
=
1
K
{
log
α
k
∑
j
=
1
N
(
E
γ
j
k
)
+
∑
j
=
1
N
(
E
γ
j
k
)
[
log
(
1
2
π
)
−
log
σ
k
−
1
2
σ
k
2
(
y
j
−
μ
k
)
2
)
]
}
(
9.28
)
\begin{aligned} Q(\theta,\theta^{(i)} ) &= E[ \log P(y,\gamma |\theta) |y, \theta^{(i)} ] \\ &= E\left\{ \sum\limits_{k = 1}^K \left\{ \sum\limits_{j = 1}^N \gamma_{jk} \log \alpha_k + \sum\limits_{j = 1}^N \gamma_{jk} \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \log \sigma_k - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} \right\} \\ &= \sum\limits_{k = 1}^K \left\{ \log \alpha_k \sum\limits_{j = 1}^N (E \gamma_{jk} ) + \sum\limits_{j = 1}^N (E \gamma_{jk} ) \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \log \sigma_k - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} \quad (9.28) \end{aligned}
Q(θ,θ(i))=E[logP(y,γ∣θ)∣y,θ(i)]=E{k=1∑K{j=1∑Nγjklogαk+j=1∑Nγjk[log(2π1)−logσk−2σk21(yj−μk)2)]}}=k=1∑K{logαkj=1∑N(Eγjk)+j=1∑N(Eγjk)[log(2π1)−logσk−2σk21(yj−μk)2)]}(9.28)
这里需要计算
E
(
γ
j
k
∣
y
,
θ
(
i
)
)
E( \gamma_{jk} | y, \theta^{(i)} )
E(γjk∣y,θ(i)),记为
γ
^
j
k
\hat{\gamma}_{jk}
γ^jk。
γ
^
j
k
=
E
(
γ
j
k
∣
y
,
θ
(
i
)
)
=
P
(
γ
j
k
=
1
∣
y
,
θ
(
i
)
)
⋅
1
+
P
(
γ
j
k
=
0
∣
y
,
θ
(
i
)
)
⋅
0
=
P
(
γ
j
k
=
1
∣
y
,
θ
(
i
)
)
=
P
(
γ
j
k
=
1
,
y
j
∣
θ
(
i
)
)
P
(
y
j
∣
θ
(
i
)
)
=
P
(
γ
j
k
=
1
,
y
j
∣
θ
(
i
)
)
∑
k
=
1
K
P
(
γ
j
k
=
1
,
y
j
∣
θ
(
i
)
)
(分母为互斥事件)
=
P
(
γ
j
k
=
1
∣
θ
(
i
)
)
P
(
y
j
∣
γ
j
k
=
1
,
θ
(
i
)
)
∑
k
=
1
K
P
(
γ
j
k
=
1
∣
θ
(
i
)
)
P
(
y
j
∣
γ
j
k
=
1
,
θ
(
i
)
)
=
α
k
(
i
)
ϕ
(
y
j
∣
θ
k
(
i
)
)
∑
k
=
1
K
α
k
(
i
)
ϕ
(
y
j
∣
θ
k
(
i
)
)
,
j
=
1
,
2
,
⋯
,
N
;
k
=
1
,
2
,
⋯
,
K
\begin{aligned} \hat{\gamma}_{jk} &= E( \gamma_{jk} |y, \theta^{(i)} ) = P(\gamma_{jk} = 1 |y, \theta^{(i)} ) \cdot 1 + P(\gamma_{jk} = 0 |y, \theta^{(i)} ) \cdot 0 \\ &= P(\gamma_{jk} = 1 |y, \theta^{(i)} ) \\ &= \frac{ P(\gamma_{jk} = 1 ,y_j | \theta^{(i)} ) }{ P(y_j | \theta^{(i)} ) } \\ &= \frac{ P(\gamma_{jk} = 1 ,y_j | \theta^{(i)} ) }{ \sum\limits_{k = 1}^K P(\gamma_{jk} = 1,y_j | \theta^{(i)} ) } \text{(分母为互斥事件)}\\ &= \frac{ P(\gamma_{jk} = 1 | \theta^{(i)} ) P(y_j | \gamma_{jk} = 1 ,\theta^{(i)} ) }{ \sum\limits_{k = 1}^K P(\gamma_{jk} = 1 | \theta^{(i)} ) P(y_j | \gamma_{jk} = 1 ,\theta^{(i)} ) } \\ &= \frac{ \alpha_k^{(i)} \phi ( y_j | \theta_k^{(i)} ) }{ \sum\limits_{k = 1}^K \alpha_k^{(i)} \phi ( y_j | \theta_k^{(i)} ) } , \quad j = 1,2,\cdots, N; \quad k = 1,2,\cdots, K \end{aligned}
γ^jk=E(γjk∣y,θ(i))=P(γjk=1∣y,θ(i))⋅1+P(γjk=0∣y,θ(i))⋅0=P(γjk=1∣y,θ(i))=P(yj∣θ(i))P(γjk=1,yj∣θ(i))=k=1∑KP(γjk=1,yj∣θ(i))P(γjk=1,yj∣θ(i))(分母为互斥事件)=k=1∑KP(γjk=1∣θ(i))P(yj∣γjk=1,θ(i))P(γjk=1∣θ(i))P(yj∣γjk=1,θ(i))=k=1∑Kαk(i)ϕ(yj∣θk(i))αk(i)ϕ(yj∣θk(i)),j=1,2,⋯,N;k=1,2,⋯,K
令
n
k
=
∑
j
=
1
N
γ
j
k
=
∑
j
=
1
N
E
γ
j
k
n_k = \sum\limits_{j = 1}^N \gamma_{jk} = \sum\limits_{j = 1}^N E\gamma_{jk}
nk=j=1∑Nγjk=j=1∑NEγjk

3. 确定EM算法的M步
θ
k
=
(
α
k
,
μ
k
,
σ
k
)
\theta_k = ( \alpha_k, \mu_k, \sigma_k )
θk=(αk,μk,σk)

∂
Q
(
θ
,
θ
(
i
)
)
∂
μ
k
=
∂
{
∑
k
=
1
K
{
n
k
log
α
k
+
∑
j
=
1
N
γ
^
j
k
[
log
(
1
2
π
)
−
log
σ
k
−
1
2
σ
k
2
(
y
j
−
μ
k
)
2
)
]
}
}
∂
μ
k
=
∑
j
=
1
N
γ
^
j
k
(
−
1
2
σ
k
2
⋅
2
(
μ
k
−
y
j
)
)
=
−
1
σ
k
2
∑
j
=
1
N
γ
^
j
k
(
μ
k
−
y
j
)
=
1
σ
k
2
∑
j
=
1
N
γ
^
j
k
(
y
j
−
μ
k
)
=
1
σ
k
2
(
∑
j
=
1
N
γ
^
j
k
y
j
−
μ
k
∑
j
=
1
N
γ
^
j
k
)
=
0
\begin{aligned} \frac{ \partial Q(\theta,\theta^{(i)} ) }{ \partial \mu_k } &= \frac{ \partial \left\{ \sum\limits_{k = 1}^K \left\{ n_k \log \alpha_k + \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \log \sigma_k - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} \right\} }{ \partial \mu_k } \\ &= \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left( - \frac{1}{2 \sigma_k^2 } \cdot 2( \mu_k - y_j ) \right) \\ &= - \frac{1}{ \sigma_k^2 } \sum\limits_{j = 1}^N \hat{\gamma}_{jk} ( \mu_k - y_j ) \\ &= \frac{1}{ \sigma_k^2 } \sum\limits_{j = 1}^N \hat{\gamma}_{jk} ( y_j - \mu_k ) \\ &= \frac{1}{ \sigma_k^2 } ( \sum\limits_{j = 1}^N \hat{\gamma}_{jk} y_j - \mu_k \sum\limits_{j = 1}^N \hat{\gamma}_{jk} ) \\ &= 0 \end{aligned}
∂μk∂Q(θ,θ(i))=∂μk∂{k=1∑K{nklogαk+j=1∑Nγ^jk[log(2π1)−logσk−2σk21(yj−μk)2)]}}=j=1∑Nγ^jk(−2σk21⋅2(μk−yj))=−σk21j=1∑Nγ^jk(μk−yj)=σk21j=1∑Nγ^jk(yj−μk)=σk21(j=1∑Nγ^jkyj−μkj=1∑Nγ^jk)=0
μ
^
k
=
μ
k
(
i
+
1
)
=
∑
j
=
1
N
γ
^
j
k
y
j
∑
j
=
1
N
γ
^
j
k
,
k
=
1
,
2
,
⋯
,
K
\hat{\mu}_k = \mu_k^{(i+1)} = \frac{ \sum\limits_{j = 1}^N \hat{\gamma}_{jk} y_j }{ \sum\limits_{j = 1}^N \hat{\gamma}_{jk} }, \quad k = 1,2,\cdots, K
μ^k=μk(i+1)=j=1∑Nγ^jkj=1∑Nγ^jkyj,k=1,2,⋯,K
∂
Q
(
θ
,
θ
(
i
)
)
∂
σ
k
2
=
∂
{
∑
k
=
1
K
{
n
k
log
α
k
+
∑
j
=
1
N
γ
^
j
k
[
log
(
1
2
π
)
−
log
σ
k
−
1
2
σ
k
2
(
y
j
−
μ
k
)
2
)
]
}
}
∂
σ
k
2
=
∂
{
∑
k
=
1
K
{
n
k
log
α
k
+
∑
j
=
1
N
γ
^
j
k
[
log
(
1
2
π
)
−
1
2
log
σ
k
2
−
1
2
σ
k
2
(
y
j
−
μ
k
)
2
)
]
}
}
∂
σ
k
2
=
∑
j
=
1
N
γ
^
j
k
(
−
1
2
σ
k
2
+
1
2
σ
k
4
⋅
(
μ
k
−
y
j
)
2
)
=
−
1
2
σ
4
∑
j
=
1
N
γ
^
j
k
(
σ
k
2
−
(
μ
k
−
y
j
)
2
)
=
−
1
2
σ
4
(
σ
k
2
∑
j
=
1
N
γ
^
j
k
−
∑
j
=
1
N
γ
^
j
k
(
μ
k
−
y
j
)
2
)
=
0
\begin{aligned} \frac{ \partial Q(\theta,\theta^{(i)} ) }{ \partial \sigma_k^2 } &= \frac{ \partial \left\{ \sum\limits_{k = 1}^K \left\{ n_k \log \alpha_k + \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \log \sigma_k - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} \right\} }{ \partial \sigma_k^2 } \\ &= \frac{ \partial \left\{ \sum\limits_{k = 1}^K \left\{ n_k \log \alpha_k + \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \frac{1}{2} \log \sigma_k^2 - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} \right\} }{ \partial \sigma_k^2 } \\ &= \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left( -\frac{1}{2 \sigma_k^2 } + \frac{1}{2 \sigma_k^4 } \cdot ( \mu_k - y_j )^2 \right) \\ &= - \frac{1}{ 2\sigma^4 } \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left( \sigma_k^2 - ( \mu_k - y_j )^2 \right) \\ &= - \frac{1}{ 2\sigma^4 } \left( \sigma_k^2 \sum\limits_{j = 1}^N \hat{\gamma}_{jk} - \sum\limits_{j = 1}^N \hat{\gamma}_{jk} ( \mu_k - y_j )^2 \right) \\ &= 0 \end{aligned}
∂σk2∂Q(θ,θ(i))=∂σk2∂{k=1∑K{nklogαk+j=1∑Nγ^jk[log(2π1)−logσk−2σk21(yj−μk)2)]}}=∂σk2∂{k=1∑K{nklogαk+j=1∑Nγ^jk[log(2π1)−21logσk2−2σk21(yj−μk)2)]}}=j=1∑Nγ^jk(−2σk21+2σk41⋅(μk−yj)2)=−2σ41j=1∑Nγ^jk(σk2−(μk−yj)2)=−2σ41(σk2j=1∑Nγ^jk−j=1∑Nγ^jk(μk−yj)2)=0
σ
^
k
2
=
σ
k
2
(
i
+
1
)
=
∑
j
=
1
N
γ
^
j
k
(
μ
k
−
y
j
)
2
∑
j
=
1
N
γ
^
j
k
,
k
=
1
,
2
,
⋯
,
K
\hat{\sigma}_k^2 = \sigma_k^{2(i+1)} = \frac{ \sum\limits_{j = 1}^N \hat{\gamma}_{jk} ( \mu_k - y_j )^2 }{ \sum\limits_{j = 1}^N \hat{\gamma}_{jk} }, \quad k = 1,2,\cdots, K
σ^k2=σk2(i+1)=j=1∑Nγ^jkj=1∑Nγ^jk(μk−yj)2,k=1,2,⋯,K

使用拉格朗日函数:
∂
{
Q
(
θ
,
θ
(
i
)
)
+
λ
(
1
−
∑
k
=
1
K
α
k
)
}
∂
α
k
=
∂
{
∑
k
=
1
K
{
n
k
log
α
k
+
∑
j
=
1
N
γ
^
j
k
[
log
(
1
2
π
)
−
log
σ
k
−
1
2
σ
k
2
(
y
j
−
μ
k
)
2
)
]
}
+
λ
(
1
−
∑
k
=
1
K
α
k
)
}
∂
α
k
=
n
k
1
α
k
−
λ
=
0
\begin{aligned} \frac{ \partial \left\{ Q(\theta,\theta^{(i)} ) + \lambda(1 - \sum\limits_{k = 1}^K \alpha_k ) \right\} }{ \partial \alpha_k } &= \frac{ \partial \left\{ \sum\limits_{k = 1}^K \left\{ n_k \log \alpha_k + \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \log \sigma_k - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} + \lambda(1 - \sum\limits_{k = 1}^K \alpha_k ) \right\} }{ \partial \alpha_k } \\ &= n_k \frac{1}{\alpha_k} - \lambda \\ &= 0 \end{aligned}
∂αk∂{Q(θ,θ(i))+λ(1−k=1∑Kαk)}=∂αk∂{k=1∑K{nklogαk+j=1∑Nγ^jk[log(2π1)−logσk−2σk21(yj−μk)2)]}+λ(1−k=1∑Kαk)}=nkαk1−λ=0
∂
{
Q
(
θ
,
θ
(
i
)
)
+
λ
(
1
−
∑
k
=
1
K
α
k
)
}
∂
λ
=
∂
{
∑
k
=
1
K
{
n
k
log
α
k
+
∑
j
=
1
N
γ
^
j
k
[
log
(
1
2
π
)
−
log
σ
k
−
1
2
σ
k
2
(
y
j
−
μ
k
)
2
)
]
}
+
λ
(
1
−
∑
k
=
1
K
α
k
)
}
∂
λ
=
1
−
∑
k
=
1
K
α
k
=
0
\begin{aligned} \frac{ \partial \left\{ Q(\theta,\theta^{(i)} ) + \lambda(1 - \sum\limits_{k = 1}^K \alpha_k ) \right\} }{ \partial \lambda } &= \frac{ \partial \left\{ \sum\limits_{k = 1}^K \left\{ n_k \log \alpha_k + \sum\limits_{j = 1}^N \hat{\gamma}_{jk} \left[ \log \left( \frac{1}{\sqrt{2\pi}} \right) - \log \sigma_k - \frac{1}{2 \sigma_k^2 } (y_j - \mu_k)^2) \right] \right\} + \lambda(1 - \sum\limits_{k = 1}^K \alpha_k ) \right\} }{ \partial \lambda } \\ &= 1 - \sum\limits_{k = 1}^K \alpha_k \\ &= 0 \end{aligned}
∂λ∂{Q(θ,θ(i))+λ(1−k=1∑Kαk)}=∂λ∂{k=1∑K{nklogαk+j=1∑Nγ^jk[log(2π1)−logσk−2σk21(yj−μk)2)]}+λ(1−k=1∑Kαk)}=1−k=1∑Kαk=0
α
^
k
=
α
k
(
i
+
1
)
=
n
k
λ
=
n
k
∑
k
=
1
K
n
k
=
n
k
N
=
∑
j
=
1
N
γ
^
j
k
N
,
k
=
1
,
2
,
⋯
,
K
\hat{\alpha}_k = \alpha_k^{(i+1)} = \frac{ n_k }{ \lambda } = \frac{ n_k }{ \sum\limits_{k = 1}^K n_k } = \frac{ n_k }{ N } = \frac{ \sum\limits_{j = 1}^N \hat{\gamma}_{jk} }{ N } , \quad k = 1,2,\cdots, K
α^k=αk(i+1)=λnk=k=1∑Knknk=Nnk=Nj=1∑Nγ^jk,k=1,2,⋯,K

步骤


EM算法的推广

F函数的极大-极大算法



GEM算法
GEM算法1

GEM算法2


GEM算法3


本章概要

备注
EM算法的推广这部分还没看,日后用到再回来细看。
相关视频
相关的笔记
hktxt /Learn-Statistical-Learning-Method
相关代码
Dod-o /Statistical-Learning-Method_Code
关于def loadData(mu0, sigma0, mu1, sigma1, alpha0, alpha1):
以概率
α
k
\alpha_k
αk 使第
k
k
k 个高斯模型生成数据
y
j
y_j
yj。并不像之前几个模型那样使用图像数据集。
关于def calcGauss(dataSetArr, mu, sigmod):
计算
















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









