






CTR任务中可以手工构造交叉组合特征,线性模型会记住出现频率高的特征(记忆性),但是缺点是模型只能在给定的特征范围内进行记忆且手工构造特征难度很大;另一个方向是引入DNN结构,目的是为了加强模型的泛化能力。具体操作是将将高维稀疏特征编码为低维稠密的Embedding vector,但是对于长尾分布的数据,长尾的一些特征值无法被充分学习,其对应的Embedding vector是不准确的,这便会造成模型泛化过度。有一种解决方法:重采样,是在已有数据不均衡的情况下,人为的让模型学习时接触到的训练样本是类别均衡的,从而一定程度上减少对头部数据的过拟合。不过由于尾部的少量数据往往被反复学习,缺少足够多的样本差异,不够鲁棒,而头部拥有足够差异的大量数据又往往得不到充分学习。
wide&deep模型能够从历史数据中学习到高频共现的特征组合的能力(Memorization)。能够利用特征之间的传递性去探索历史数据中从未出现过的特征组合(Generalization)。
<div align=center>
<img src="http://ryluo.oss-cn-chengdu.aliyuncs.com/Javaimage-20200910214310877.png" alt="image-20200910214310877" style="zoom:65%;" />
</div>
wide&deep模型本身的结构是非常简单的,但是需要根据具体问题决定哪些特征放在Wide部分(增强模型的“记忆能力”,对应上面提到的线性模型),哪些放在Deep部分(增强模型的“泛化能力”,对应上面的DNN)。
wide将部分原始特征和原始特征的交叉特征作为输入,交叉特征用 c k i c_{ki} cki表示,当第i个特征属于第k个特征组合时, c k i c_{ki} cki的值为1,否则为0, x i x_i xi是第i个特征的值,其子特征同时为1则1,否则为0。
训练时候使用带
L
1
L_1
L1正则的FTRL算法(Follow-the-regularized-leader)进行优化,而L1 FTLR是非常注重模型稀疏性质的,也就是说W&D模型采用L1 FTRL是想让Wide部分变得更加的稀疏,即Wide部分的大部分参数都为0,这就大大压缩了模型权重及特征向量的维度。**Wide部分模型训练完之后留下来的特征都是非常重要的,那么模型的“记忆能力”就可以理解为发现"直接的",“暴力的”,“显然的”关联规则的能力。**例如Google W&D期望wide部分发现这样的规则:用户安装了应用A,此时曝光应用B,用户安装应用B的概率大。
FTRL:应用在在线学习的场景中,SGD优化算法在Online模式下,由于训练周期短且样本实时到达,样本本身数量小,分布不均衡,难以得到最优解尤其是稀疏解。FTRL 综合考虑了 FOBOS 和 RDA 对于正则项和 限制的区别,其特征权重的更新公式为: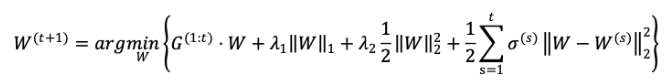
Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中),Deep部分的数学形式如下:
a
(
l
+
1
)
=
f
(
W
l
a
(
l
)
+
b
l
)
a^{(l+1)} = f(W^{l}a^{(l)} + b^{l})
a(l+1)=f(Wla(l)+bl)
**我们知道DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。**对于Deep部分的DNN模型作者使用了深度学习常用的优化器AdaGrad,这也是为了使得模型可以得到更精确的解。
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。















 236
236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









