







Elasticsearch[六]:相关度分数评分算法分析及相关度分数优化
ES 相关度评分算法靠三个部分来依次实现,没有先后顺序,是一个逐层推进的逻辑
- Boolean 模型 根据过滤条件 true,false 来过滤 doc
- TFIDF 模型
- VSM 空间向量模型
1.ES 相关度分数评分算法
- Booolean
boolean 根据搜索条件过滤 doc 的国车过是不做相关度分数计算的,只是为了标记出来哪些 doc 是符合搜索条件要求的
- TFIDF模型
了解文档分词处理的都听过 TFIDF 模型,TF 词频,IDF 逆文本频率,说白了就是单词 term 出现了再所有文档中出现了多少次,出现越多,说明这个单词越没有标识度,越不重要,和文档的相关度分数越低
比如下面多个文章 ABC 中出现多次吃饭,一个文章 C 中出现一次原子弹,那肯定原子弹肯定对文章 C 很重要 很有标识度,原子弹这个单词对 C 来说 权重很高,这就是 TFIDF 模型
文章DOC A :{ 吃饭, 喝酒, 喝茶}
文章DOC B: {吃饭,原子弹}
文章DOC C:{吃饭, 喝酒}

- VSM 空间向量模型
VSM 这个就更为专业
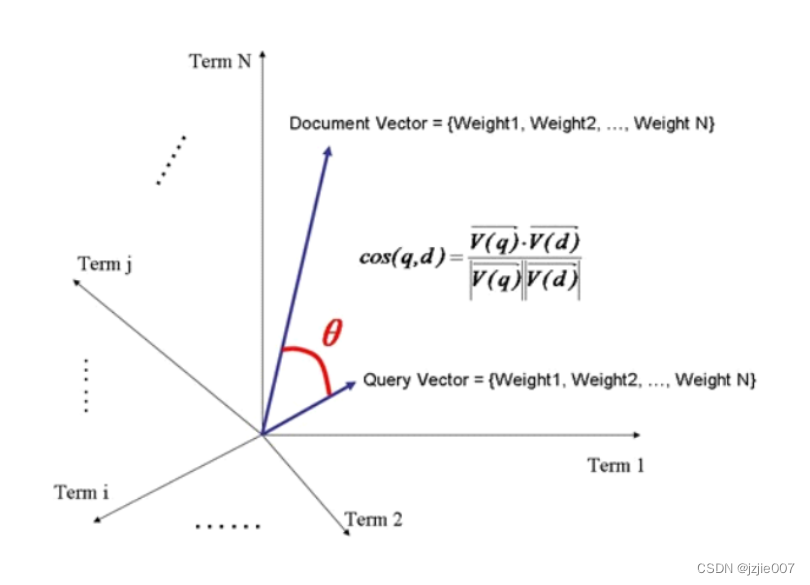
- 我们从 document 出发。document 由若干个 term 组成,通过 TF/IDF 算法计算后,我们可以得知每一个 term 在 document 中的权重,而不同的 term 又会根据自己的权重影响当前 document 的相关度得分
- 我们将当前 document 中出现的所有 term 的权重组合起来,形成一条向量 Document Vector, Document Vector 可能会有多条
- 有了向量可以根据 余弦函数 cos 计算两个向量的夹角,夹角越大,说明偏离越远,两个向量越不相似,进而得出文章不相似
Document = {term1, term2, …… ,termN}
Document Vector = {weight1, weight2, …… ,weightN}
2.ES 相关度分数优化
2.1 准备数据
先构造 index:testquery, 然后构造 mapping 结构, 插入测试数据
#构建 库index testquer
put /testquery
#构建mapping结构
put /testquery/_mapping
{
"properties" : {
"address" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"age" : {
"type" : "long"
},
"area" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"city" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"content" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"deptName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"empId" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"info" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"mobile" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"copy_to" : [
"info"
]
},
"provice" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
},
"fielddata" : true
},
"salary" : {
"type" : "long"
},
"sex" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"addtime" : {
"type":"date",
//时间格式 epoch_millis表示毫秒
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
插入测试数据
put /testquery/_bulk
{"index":{"_id": 1},"addtime":"1658041203000"}
{"empId" : "111","name" : "员工1","age" : 20,"sex" : "男","mobile" : "19000001111","salary":1333,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"光谷大道","address":"湖北省武汉市洪山区光谷大厦","content" : "i like to write best elasticsearch article", "addtime":"1658140003000"}
{"index":{"_id": 2}}
{"empId" : "222","name" : "员工2","age" : 25,"sex" : "男","mobile" : "19000002222","salary":15963,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i think java is the best programming language"}
{"index":{"_id": 3},"addtime":"1658040045600"}
{ "empId" : "333","name" : "员工3","age" : 30,"sex" : "男","mobile" : "19000003333","salary":20000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"经济技术开发区","address" : "湖北省武汉市经济开发区","content" : "i am only an elasticsearch beginner"}
{"index":{"_id": 4},"addtime":"1658040012000"}
{"empId" : "444","name" : "员工4","age" : 20,"sex" : "女","mobile" : "19000004444","salary":5600,"deptName" : "销售部","provice" : "湖北省","city":"武汉","area":"沌口开发区","address" : "湖北省武汉市沌口开发区","content" : "elasticsearch and hadoop are all very good solution, i am a beginner"}
{"index":{"_id": 5},"addtime":"1658040593000"}
{ "empId" : "555","name" : "员工5","age" : 20,"sex" : "男","mobile" : "19000005555","salary":9665,"deptName" : "测试部","provice" : "湖北省","city":"高新开发区","area":"武汉","address" : "湖北省武汉市东湖隧道","content" : "spark is best big data solution based on scala ,an programming language similar to java"}
{"index":{"_id": 6},"addtime":"1658043403000"}
{"empId" : "666","name" : "员工6","age" : 30,"sex" : "女","mobile" : "19000006666","salary":30000,"deptName" : "技术部","provice" : "武汉市","city":"湖北省","area":"江汉区","address" : "湖北省武汉市江汉路","content" : "i like java developer","addtime":"1658041003000"}
{"index":{"_id": 7}}
{"empId" : "777","name" : "员工7","age" : 60,"sex" : "女","mobile" : "19000007777","salary":52130,"deptName" : "测试部","provice" : "湖北省","city":"黄冈市","area":"边城区","address" : "湖北省黄冈市边城区","content" : "i like elasticsearch developer","addtime":"1658040008000"}
{"index":{"_id": 8}}
{"empId" : "888","name" : "员工8","age" : 19,"sex" : "女","mobile" : "19000008888","salary":60000,"deptName" : "技术部","provice" : "湖北省","city":"武汉","area":"汉阳区","address" : "湖北省武汉市江汉大学","content" : "i like spark language","addtime":"1656040003000"}
{"index":{"_id": 9}}
{"empId" : "999","name" : "员工9","age" : 40,"sex" : "男","mobile" : "19000009999","salary":23000,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市郑州大学","content" : "i like java developer","addtime":"1608040003000"}
{"index":{"_id": 10}}
{"empId" : "101010","name" : "张湖北","age" : 35,"sex" : "男","mobile" : "19000001010","salary":18000,"deptName" : "测试部","provice" : "湖北省","city":"武汉","area":"高新开发区","address" : "湖北省武汉市东湖高新","content" : "i like java developer i also like elasticsearch","addtime":"1654040003000"}
{"index":{"_id": 11}}
{"empId" : "111111","name" : "王河南","age" : 61,"sex" : "男","mobile" : "19000001011","salary":10000,"deptName" : "销售部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am not like java ","addtime":"1658740003000"}
{"index":{"_id": 12}}
{"empId" : "121212","name" : "张大学","age" : 26,"sex" : "女","mobile" : "19000001012","salary":1321,"deptName" : "测试部",,"provice" : "河南省","city":"开封市","area":"金明区","address" : "河南省开封市河南大学","content" : "i am java developer thing java is good","addtime":"165704003000"}
{"index":{"_id": 13}}
{"empId" : "131313","name" : "李江汉","age" : 36,"sex" : "男","mobile" : "19000001013","salary":1125,"deptName" : "销售部","provice" : "河南省","city":"郑州市","area":"二七区","address" : "河南省郑州市二七区","content" : "i like java and java is very best i like it do you like java ","addtime":"1658140003000"}
{"index":{"_id": 14}}
{"empId" : "141414","name" : "王技术","age" : 45,"sex" : "女","mobile" : "19000001014","salary":6222,"deptName" : "测试部",,"provice" : "河南省","city":"郑州市","area":"金水区","address" : "河南省郑州市金水区","content" : "i like c++","addtime":"1656040003000"}
{"index":{"_id": 15}}
{"empId" : "151515","name" : "张测试","age" : 18,"sex" : "男","mobile" : "19000001015","salary":20000,"deptName" : "技术部",,"provice" : "河南省","city":"郑州市","area":"高新开发区","address" : "河南省郑州高新开发区","content" : "i think spark is good","addtime":"1658040003000"}
2.2 Boost 增加搜索条件权重
设置 boost 查询条件权重可以实现影响搜索结果评分的目的,比如 查询条件后面加上 boost,实现当前条件关联度倍增的效果
#不加boost条件查询
get /testquery/_search
{
"query":{
"bool": {
"should": [
{
"match": {
"provice.keyword": "湖北省"
}
},
{
"match": {
"address": "开发区"
}
}
]
}
}
}
不加条件查询结果

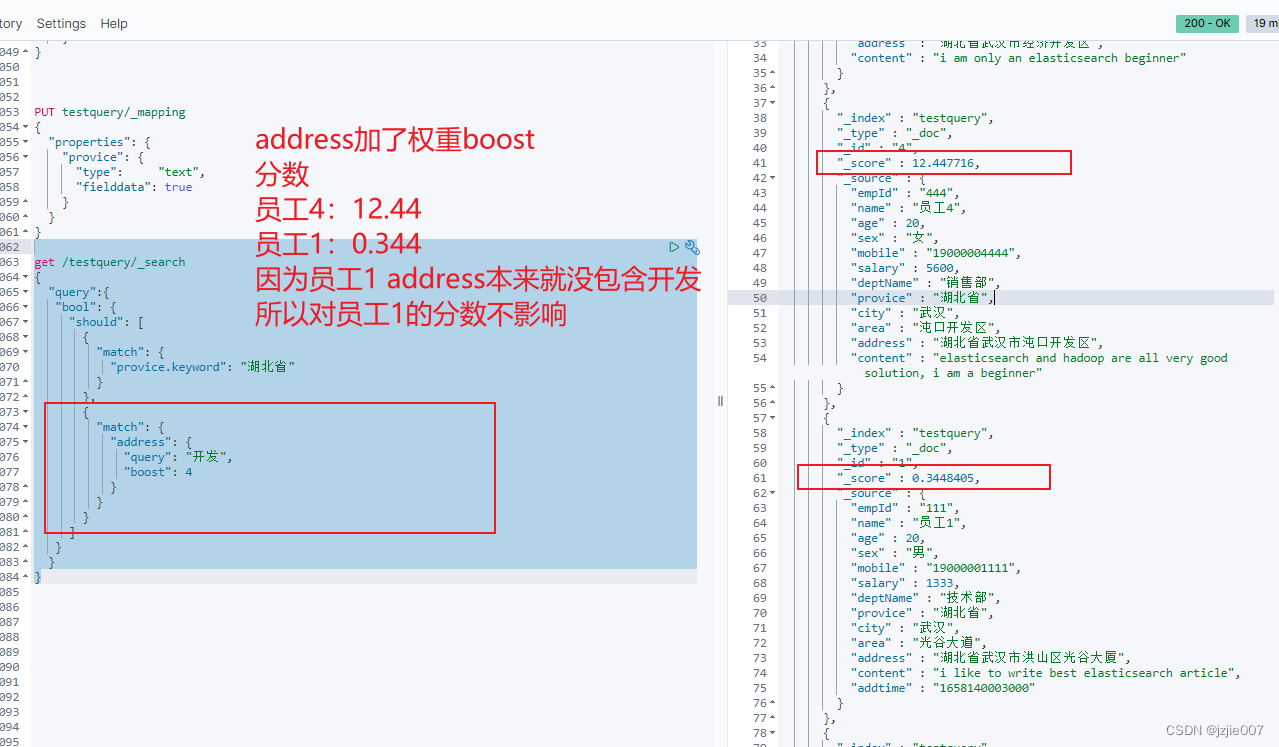
现在给 address 地址 加权重 boost,认为 address 包含开发的排名更优先
然后员工 4 中 address 包含开发,分数直接飙升到 12.44
员工 1 中 address 并没有开发 两个字,所以 address 的 boost 对员工 1 的分数没有影响依旧是 0.344 分
2.3 Negative boost 削弱搜索条件权重
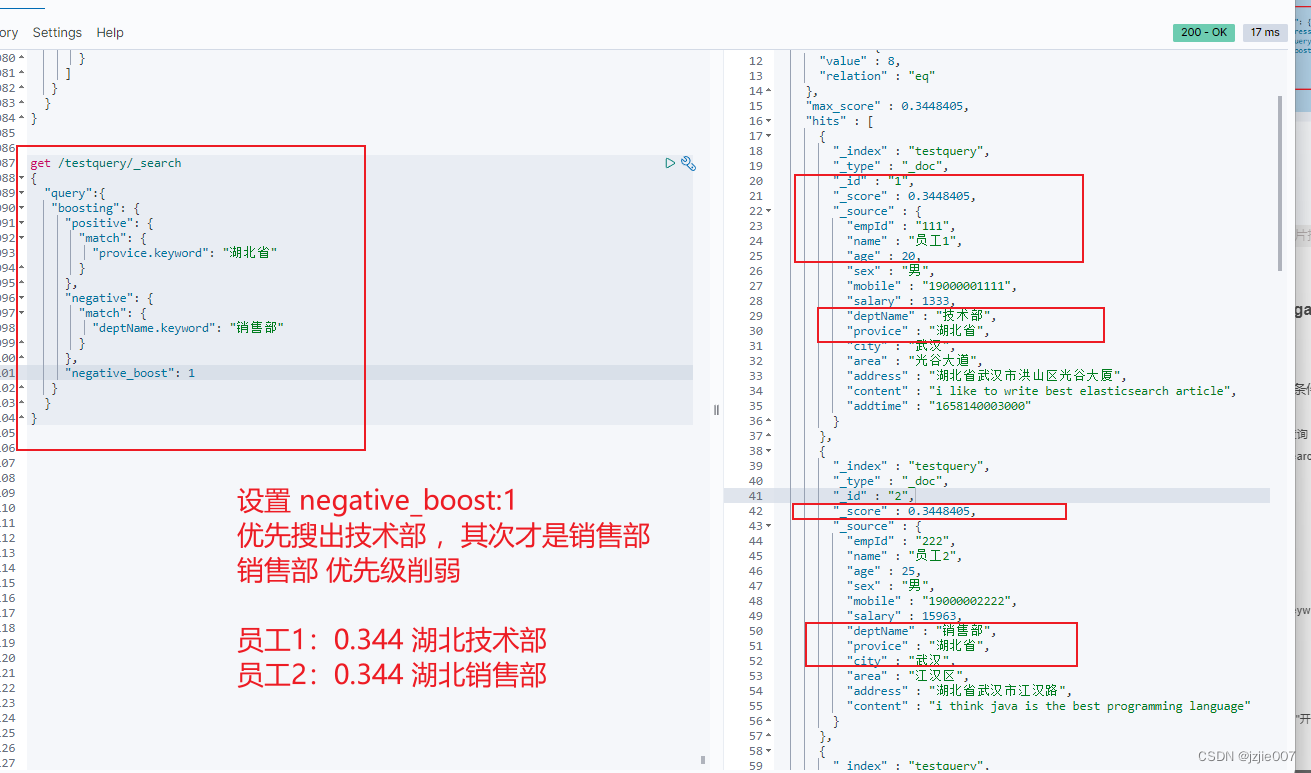
设置 negative boost 削弱查询条件的权重 可以实现影响搜索结果评分的目的,削弱查询条件对分数的影响
#设置 negative_boost 权重为 1 看下结果
get /testquery/_search
{
"query":{
"boosting": {
"positive": {
"match": {
"provice.keyword": "湖北省"
}
},
"negative": {
"match": {
"deptName.keyword": "销售部"
}
},
"negative_boost": 1
}
}
}
设置 negative_boost 权重为 1 看下结果
员工 1:0.344 湖北省技术部
员工 2:0.344 湖北省销售部
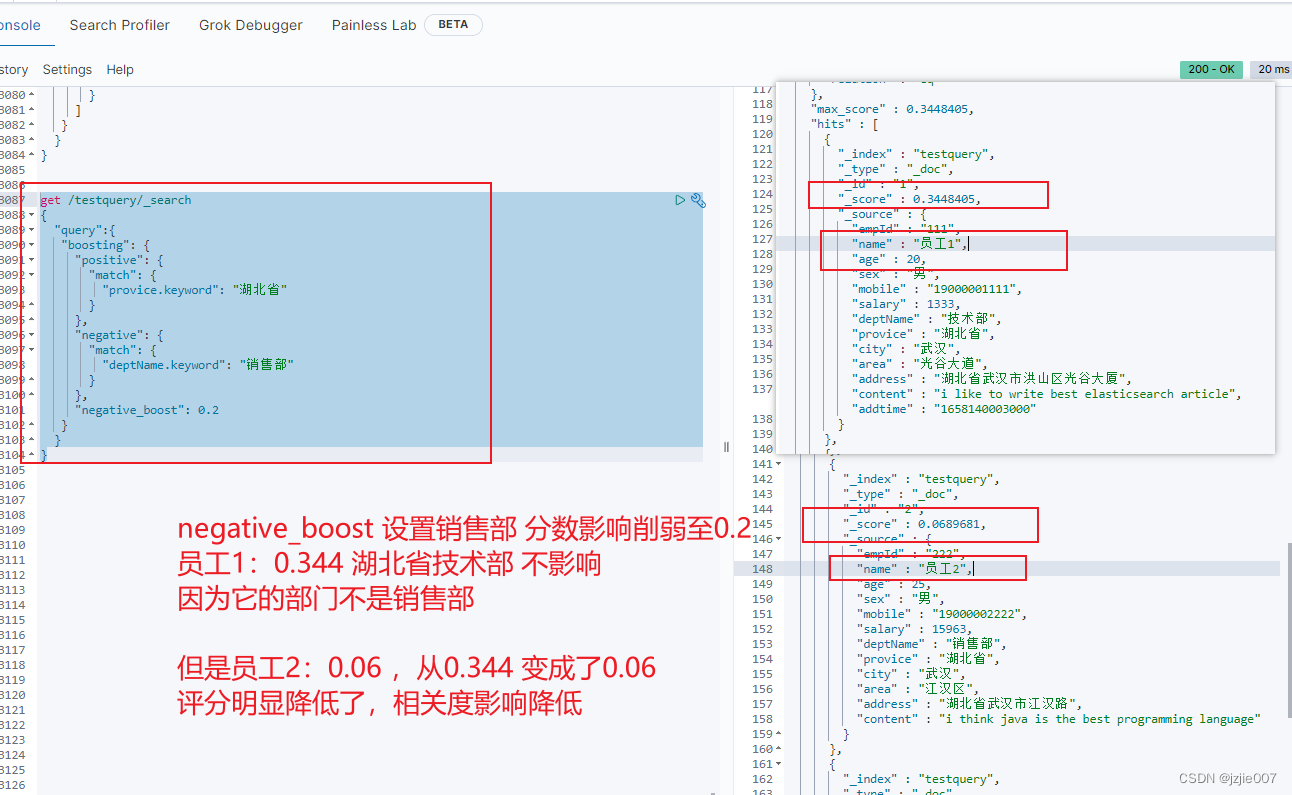
现在 negative_boost 修改为 0.2 看下结果
员工 1:0.344 湖北技术部 不受影响,因为他的部门 deptname 不是销售部,所以削弱销售部的权重不影响他
员工 2:0.068 湖北销售部 受影响,分数明显降低,相关度降低
2.4 Function score 自定义相关分数算法
场景:
现在我想把 相关度分数和 文章的浏览量关联起来, 浏览量越大,分数越高,怎么实现
分数算法有几个关键点
- query 内部使用 function_score 表明我要使用自定义相关度分数
- function_score 内部 使用 field_value_factor 表明参与到分数计算的字段 设置,及按照什么来计算等
- function_score 的 field 表示 对哪个字段进行积分
- modifier 表示 对哪个字段进行积分 比如 ln, log1p, log2p log 等等算式
- factor 表示 对 你要计算的字段 field 的值 与 factor 相乘 处理
- boost_mode 表示 分数 旧分数和新分数 如何处理 累加 / 减 / 乘 / 除 / max/min 等等
- max_boost 表示 限制计算出来的分数不要超过 max_boost 指定的值 , 不是最终得分不超过多少
我们下一篇文章 单独讲解一下 如何实现这种场景及 自定义相关度分数算法如何实现, 每个参数都是如何使用的详解
至此 我们已经学习了 ES 相关度分数评分算法分析, 也了解了 ES 实现相关度分析底层原理 使用 boolean 模型,TFIDF,VSM 空间向量模型计算相关度,也会使用 boost, negativeboost 来增加,削弱 查询条件权重 等等
3.ES相关度分数评分优化及FunctionScore 自定义相关度分数算法
- ES 相关度评分算法调优
- boost 增加权重
- negative boost 削弱权重
- funciton_score 自定义相关度分数算法
场景:
现在我想把 相关度分数和 文章的浏览量关联起来, 浏览量越大,分数越高,怎么实现, 就要用自定义分数算法
3.1.ES 自定义相关分数算法 Function Score
3.1.1 Function Score 原理
自定义分数计算方式, 定义 function score 指定字段直接参与到相关度分数计算中,甚至可以替换掉 ES 的相关度算分, 自定义分数算法有几个关键点
- query 内部使用 function_score 表明我要使用自定义相关度分数
- function_score 内部 使用 field_value_factor 表明参与到分数计算的字段 设置,及按照什么来计算等
- function_score 的 field 表示 对哪个字段进行积分
- modifier 表示 对哪个字段进行积分 比如 ln, log1p, log2p log 等等算式
- factor 表示 对 你要计算的字段 field 的值 与 factor 相乘 处理
- boost_mode 表示 分数 旧分数和新分数 如何处理 累加 / 减 / 乘 / 除 / max/min 等等
- max_boost 表示 限制计算出来的分数不要超过 max_boost 指定的值 , 不是最终得分不超过多少
上面讲了基本原理及参数,下面开始实战
3.1.2 准备数据
POST /saytest/_bulk
{"index" : { "_id" : "1" }}
{"countnum" : 10, "say" : "hello world"}
{"index" : { "_id" : "2" }}
{"countnum" : 20, "say" : "hello java"}
{"index" : { "_id" : "3" }}
{"countnum" : 5, "say" : "hello spark learning"}
{"index" : { "_id" : "4" }}
{"countnum" : 15, "say" : "hello bye bye"}
{"index" : { "_id" : "5" }}
{"countnum" : 13, "say" : "hi world"}
查一下 如果不用 function_score 查询条件获取的基本分数 是多少
#不使用 function_score基本分数查询
GET /saytest/_search
{
"query": {
"match": {
"say": "java spark"
}
}
}

查询结果
| 文档 | 分数 | 分数 |
|---|---|---|
| id:2 | hello java | 1.4877305 |
| id:3 | java spark | 1.2576691 |
| 文档 | 内容 | 分数 |
|---|---|---|
| id:2 | hello java | 1.4877305 |
| id:3 | java spark | 1.2576691 |
3.1.3 自定义计算方式实现 function_score boost_mode 相乘
查询公式及参数如下:
- field 参与计算字段式 是文章的浏览量 countnum
- boost_mode 是 multiply 相乘的方式 计算方式 old_score x 新分数
- modifier 计算方式 式 log1p , 就是 log(1+xxx) 的计算方式 new_score = old_score * log(1+countnum)
- factor 是 1 且 boost_mode 是 multiply 相乘的方式 计算方式 new_score = old_score * log(1+ factor x countnum)
GET /saytest/_search
{
"query": {
"function_score": {
"query": {
"match": {
"say": "java spark"
}
},
"field_value_factor": {
"field": "countnum",
"modifier": "log1p",
"factor": 1
},
"boost_mode": "multiply",
"max_boost": 2
}
}
}
自定义公式查询结果 :

这个分 如何算出来的 ? 我们来看一下原理
| 文档 | 内容 | 原分数 | 自定义分数 |
|---|---|---|---|
| id:2 | hello java | 1.4877305 | 1.967106 |
| id:3 | java spark | 1.2576691 | 0.978656 |
对于 id-2 文档 doc,countnum=20, 计算方式 new_score = old_score * log(1+ factor*countnum)
也就是 1.4877305 * log (1+ 1 x 20) = 1.967105 ~ 就是 算出来的 1.967106
对于 id-3 文档 doc, countnum = 5
也就是 1.2576691 * log (1+ 1 x 5) = 0.97865678273 ~ 同样也是 算出来的 0.978656

3.1.4 自定义 function_score 修改 modifier 及 factor 及 boost_mode 相加
查询公式及参数如下:
- field 参与计算字段式 是文章的浏览量 countnum
- boost_mode 是 sum 累加的方式 计算方式
- modifier 计算方式 式 ln , 就是 ln(xxx) 的计算方式 new_score = old_score + ln(countnum)
- factor 是 0.8 且 boost_mode 是 sum 累加的方式 计算方式 new_score = old_score + ln(factor x countnum)
!!! 注意 改了 boost_mode 的方式,变为累加
!!! 注意 改了 boost_mode 的方式,变为累加
!!! 注意 改了 boost_mode 的方式,变为累加
GET /saytest/_search
{
"query": {
"function_score": {
"query": {
"match": {
"say": "java spark"
}
},
"field_value_factor": {
"field": "countnum",
"modifier": "ln",
"factor": 0.8
},
"boost_mode": "sum",
"max_boost": 10
}
}
}
自定义公式查询结果 :

这个分 如何算出来的 ? 我们来看一下原理
| 文档 | 内容 | 原分数 | 自定义分数 |
|---|---|---|---|
| id:2 | hello java | 1.4877305 | 3.4877305 |
| id:3 | java spark | 1.2576691 | 2.6439636 |
对于 id-2 文档 doc,countnum=20, 计算方式 new_score = old_score + ln(factor x countnum)
也就是 1.4877305 + ln (0.8 x 20) = 4.26031922224 ~ 就是 算出来的 4.260319,
对于 id-3 文档 doc, countnum = 5
也就是 1.2576691 + ln(0.8 x 5) = 2.64396346112 ~ 同样也是 算出来的 2.6439636

3.1.5 自定义 function_score max_boost 限制算出来的最大分
上一步 我们看了一下 算分 原理, max_boost 其实是限制的 ln(factor x countnum) 分数, 我们修改下 max_boost 试试 效果,看看 是否能够限制 计算出来的分数
#max_boost 限制最大算出来的分=2
GET /saytest/_search
{
"query": {
"function_score": {
"query": {
"match": {
"say": "java spark"
}
},
"field_value_factor": {
"field": "countnum",
"modifier": "ln",
"factor": 0.8
},
"boost_mode": "sum",
"max_boost": 2
}
}
}

| 文档 | 内容 | 原分数 | 自定义分数 |
|---|---|---|---|
| id:2 | hello java | 1.4877305 | 3.4877305 |
| id:3 | java spark | 1.2576691 | 2.6439636 |
对于 id-2 文档 doc,countnum=20, 计算方式 new_score = old_score + ln(factor x countnum)
也就是 ln (0.8 x 20) = 2.77258872224 ,累加旧的分数 1.4877305 + 2.77258872224 = 4.26031922224 ~
为啥 id-2 的分数是 3.4877305 呢?
- 原因就是 max_boost=2 限制了 计算出来的分的最大值是 2, 即使 ln (0.8 x 20) = 2.77258872224 > 2 , 累加旧分的时候,用设置的 max_boost=2 去累加 , 因此 实际计算的过程就是 1.4877305 + 2 = 3.4877305
- 对于 id-3 文档 doc, countnum = 5 计算出来的分 ln(0.8 x 5)=1.38629436112 < 2 , 小于 2 累加旧分用算出来的值 1.2576691 + 1.38629436112 = 2.64396346112 ~ 即 2.6439636
再试一下,把 max_boost 调整为 1 看下结果, 也是符合正确的

至此 我们已经学习了 ES Function score 自定义相关度分数算法的 实现逻辑, 并且可以根据自己的业务场景去定制算法了
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









