







k-NN算法是一种很简单的分类算法。简单来讲,它没有训练的过程,只是简单粗暴的计算输入特征与训练集中特征点的距离,然后选这些距离中最小的k个值,根据这k个值所对应数据点的类别情况预测输入实例的分类情况。所以,k-NN算法的三个基本要素为:距离度量, 分类决策规则, k值。
距离度量
两个特征的距离反应了它们的相似程度。可以选择Lp距离计算:
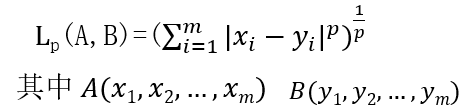
一般取p=2,即欧几里得距离。
- k值
- 分类决策规则
往往选择多数表决,即由k个邻近实例中占多数的类作为预测结果
k-NN 的python代码如下:
def classify (dataset, labels, k, x):
N = dataset.shape[0]
matx = (tile(x,(N, 1)) - dataset) ** 2
distance = matx.sum(axis = 1) ** 0.5
sortdistance = distance.argsort()
result = {}
for i in range(k):
result[labels[sortdistance[i]]] = result.get(labels[sortdistance[i]], 0) + 1
sortresult = sorted(result.iteritems(), key = operator.itemgetter(1), reverse = True)
print sortresult[0][0]如果数据集中某一个特征的值普遍大于其他特征,则需要对所有数据进行归一化,将数据转化到特定区间。如将数据转化到[0,1]的区间:
(dataVector - min) / (max - min)
但是k近邻算法的执行效率不高,要计算N个点的距离,计算非常耗时。可以考虑用kd树的数据结构。
- kd树
- 构造kd树

a. 选择xi(1)轴,将x1-xn个向量中xi(1)轴的坐标的中位数作为切分点,将集合一分为二,xi(1)坐标等于中位数的向量存在根节点中
b. 继续选下一个轴xi(2)重复a的步骤继续对子集分类,同样将中位数对应的向量存在根节点中
c. 直到选择第k个轴分类结束,此时满足分类条件的向量存在同一个节点,即为叶节点。
b. 继续选下一个轴xi(2)重复a的步骤继续对子集分类,同样将中位数对应的向量存在根节点中
c. 直到选择第k个轴分类结束,此时满足分类条件的向量存在同一个节点,即为叶节点。
- 搜索kd树(以k=1为例)
a. 由根节点的分类条件一层层向下寻找输入实例对应的叶节点
b. 以目标点为圆心,叶节点中与目标点最近的点所对应的的距离为半径确定一个圆
c. 向上返回到叶节点的根节点,查看圆域与该根节点的另一个子节点有无相交,如果没有,继续向上访问上一级根节点;如果有,检查相交区域里有没有训练集中的点,无点则同样继续向上访问上一级根节点,有点则以目标点与该点的距离为半径更新圆域
d. 重复c步骤直到回退到最顶层的父节点。















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









