







 本文介绍了一种基于多头自注意力机制的排名模型。该模型通过堆叠多头自注意力层来处理输入序列,并利用全连接网络进行最终的排名预测。实验在IstellaLETOR、MicrosoftLETOR30K及Yahoo!LETOR等数据集上进行,对比了多种基线方法,包括rankSVM、rankBoost等。
本文介绍了一种基于多头自注意力机制的排名模型。该模型通过堆叠多头自注意力层来处理输入序列,并利用全连接网络进行最终的排名预测。实验在IstellaLETOR、MicrosoftLETOR30K及Yahoo!LETOR等数据集上进行,对比了多种基线方法,包括rankSVM、rankBoost等。
总结
加序列emb,multi-head self-attention/transformer
细节
当输入list排序变化后,用rank模型输出不变的排序list。multi-head self-attention堆叠解决。
representation-encoding-ranking
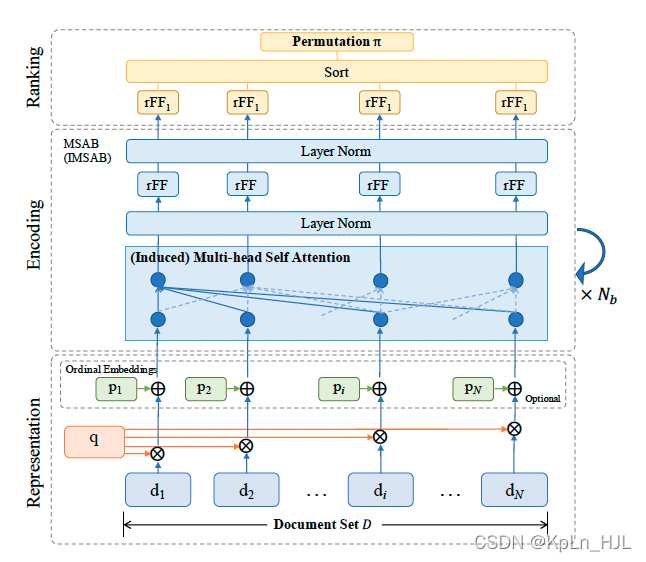
先用现有的ranking model做出来init ranking,再multi-head attention做encode,最后fnn做ranking。
交叉熵损失
实验
dataset
- Istella LETOR:http://blog.istella.it/istella-learning-to-rank-dataset/
- Microsoft LETOR 30K:http://research.microsoft.com/en-us/projects/mslr/
- Yahoo! LETOR:http://learningtorankchallenge.yahoo.com
baseline:rankSVM, rankBoost, MART, LambdaMart, DLCM, GSF
评估指标:ndcg@1,3,5,10

















 1579
1579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









