







一、引言
前文回顾:
【Python时序预测系列】基于Holt-Winters方法实现单变量时间序列预测(源码)
【Python时序预测系列】基于ARIMA法实现单变量时间序列预测(源码)
SARIMA (Seasonal Autoregressive Integrated Moving Average) 是一种常用于时序数据预测的模型,它结合了自回归 (AR)、差分 (I) 和移动平均 (MA) 的概念,并考虑了数据的季节性。
二、实现过程
导入相关的库
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
from statsmodels.tsa.holtwinters import ExponentialSmoothing
import matplotlib.pyplot as plt2.1 读取数据集
# 读取数据集
data = pd.read_csv('data.csv')
# 将日期列转换为日期时间类型
data['Month'] = pd.to_datetime(data['Month'])
# 将日期列设置为索引
data.set_index('Month', inplace=True)data:
2.2 划分数据集
# 拆分数据集为训练集和测试集
train_data = data.iloc[:-12]
test_data = data.iloc[-12:]
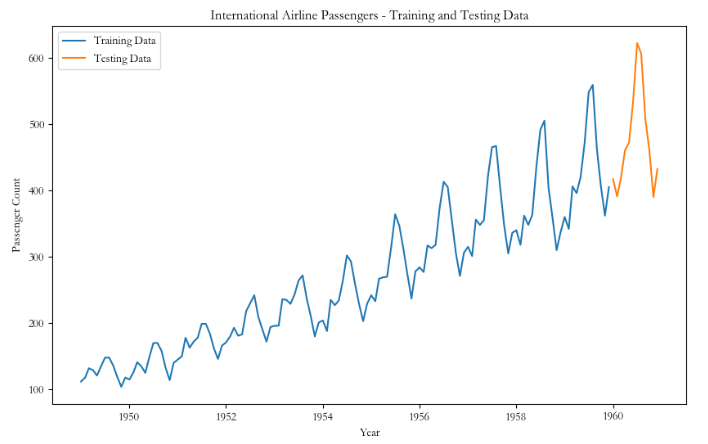
# 绘制训练集和测试集的折线图
plt.figure(figsize=(10, 6))
plt.plot(train_data, label='Training Data')
plt.plot(test_data, label='Testing Data')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Training and Testing Data')
plt.legend()
plt.show()训练集和测试集:
2.3 建立模拟合模型进行预测
# 拟合 SARIMA 模型
model = SARIMAX(data, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12))
model_fit = model.fit()
# 进行预测
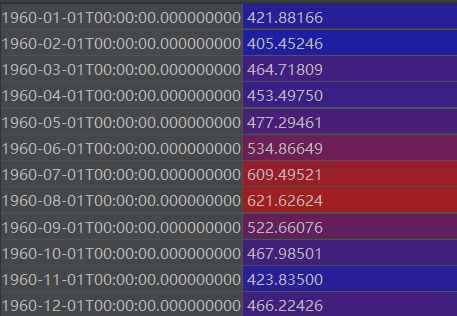
predictions = model_fit.predict(start=test_data.index[0], end=test_data.index[-1])
# predictions = model_fit.forecasts(len(test_data))SARIMAX(data, order=(p, d, q), seasonal_order=(P, D, Q, s))
-
自回归阶数 (p):表示当前观测值与前几个观测值的相关性。
-
差分阶数 (d):表示为使数据平稳所需的差分次数。
-
移动平均阶数 (q):表示当前观测值与前几个观测值的移动平均相关性。
-
季节性自回归阶数 (P):表示当前观测值与同一季节前几个季节的观测值的相关性。
-
季节性差分阶数 (D):表示为使数据平稳所需的季节性差分次数。
-
季节性移动平均阶数 (Q):表示当前观测值与同一季节前几个季节的移动平均相关性。
-
季节周期 (s):表示数据的季节性周期长度。
predictions:
2.4 预测效果展示
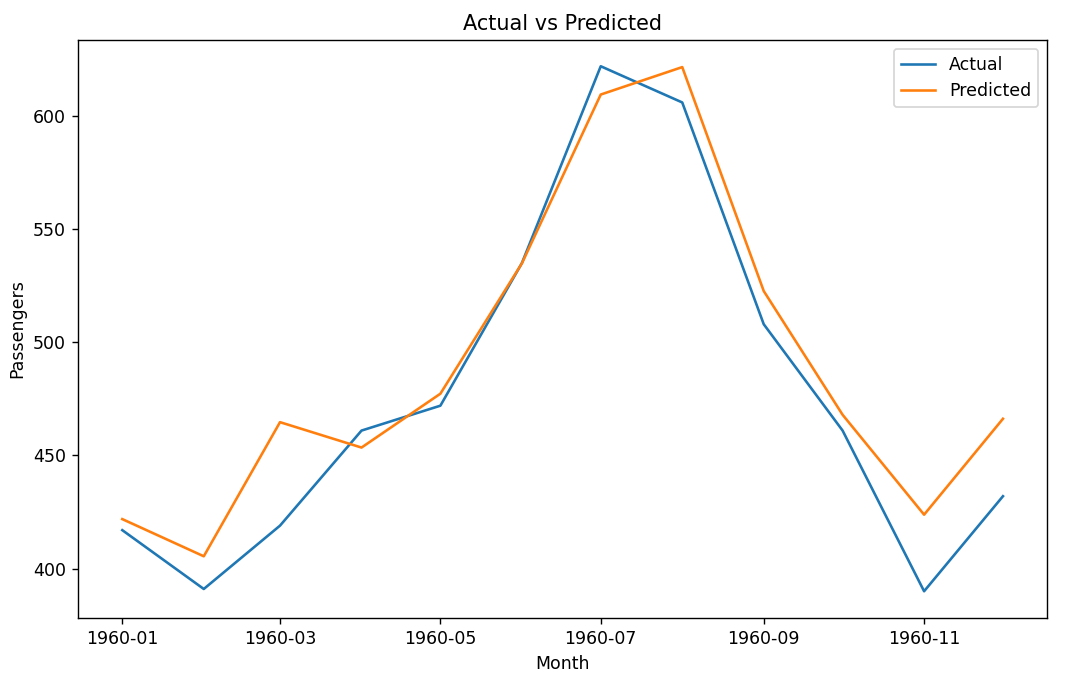
# 绘制测试集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(test_data.index, test_data, label='Actual')
plt.plot(predictions.index, predictions, label='Predicted')
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.title('Actual vs Predicted')
plt.legend()
plt.show()测试集真实值与预测值:
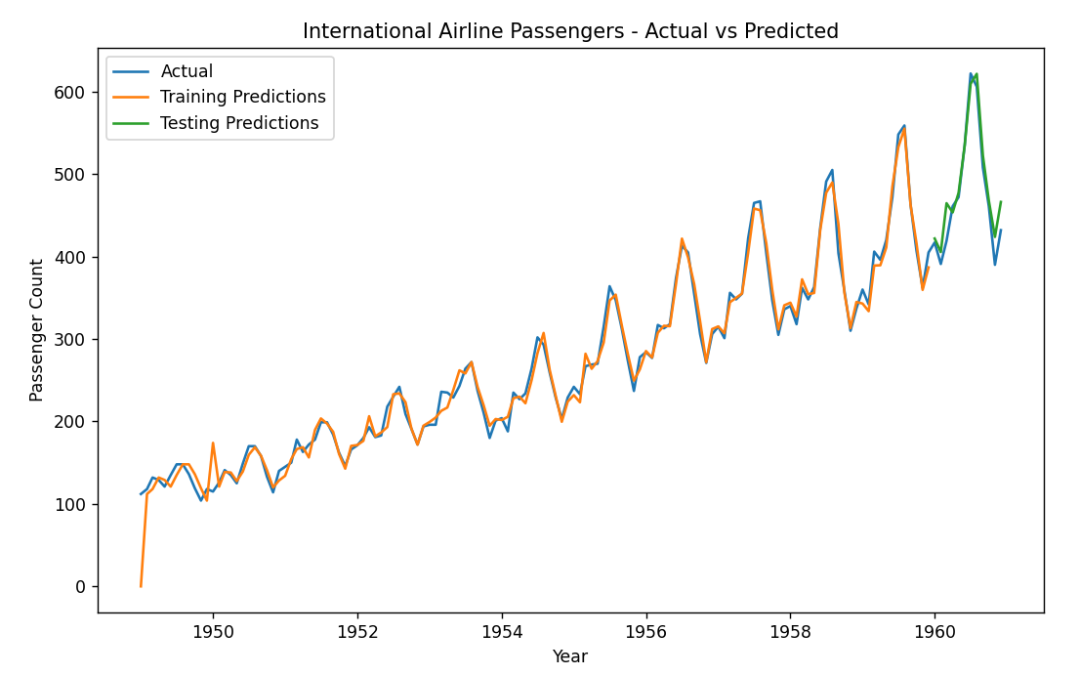
# 绘制原始数据、训练集预测结果和测试集预测结果的折线图
plt.figure(figsize=(10, 6))
plt.plot(data, label='Actual')
plt.plot(train_data.index, model_fit.fittedvalues, label='Training Predictions')
plt.plot(test_data.index, predictions, label='Testing Predictions')
plt.xlabel('Year')
plt.ylabel('Passenger Count')
plt.title('International Airline Passengers - Actual vs Predicted')
plt.legend()
plt.show()原始数据、训练集预测结果和测试集预测结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。















 3980
3980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











