







论文链接:《FastReID: A Pytorch Toolbox for General Instance Re-identification》
代码链接:https://github.com/JDAI-CV/fast-reid
什么是目标重识别(ReID)?
简单理解就是对于一个特定的目标(可能是行人、车辆、人脸或者其他特定物体),在候选图像集中检索到它,或称图像中目标的实例级检索。如在视频监控领域,行人重识别是各大厂商重点研发的技术。

Abstract
本文介绍了FastReID作为一个在JD AI研究中广泛应用的通用实例再识别(re-id)软件系统,已应用于视频分析如人的re-id、车辆的re-id和图像检索。在FastReID中,高模块化和可扩展性的设计使得研究者可以很容易地实现新的研究思路。友好的可管理的系统配置和工程部署功能允许从业者快速地将模型部署到产品中。
我们已经实施了一些最先进的项目,包括人员识别、部分识别、跨领域识别和车辆识别,并计划在多个基准数据集上发布这些预训练的模型。FastReID是目前为止最通用和高性能的工具箱,支持单个和多个GPU服务器,你可以非常容易地复制我们的项目结果,非常欢迎使用它,代码和模型可在https: https://github.com/JDAI-CV/fast-reid。
1. Introduction
一般实例再识别(reid)是一种实例中心AI技术,目的是在大量视频中找到特定的人/车/感兴趣的物体。它为各种需要痛苦和无聊的视频观看的应用提供了便利,包括搜索视频镜头与电视剧中的男主角有关,与摄像机中的购物中心走失的孩子有关,与城市监控系统中的可疑车辆有关。许多研究者实现了一个基于开放源代码的任务,可扩展性和可重用性的修改使得很难重现结果。此外,学术研究与模型部署往往存在差距,使得学术研究模型难以快速转化为产品。
为了加快包括学术界和工业界的研究人员和实践者在内的普通实例重新识别社区的进展,我们现在发布了一个名为 FastRelD的统一实例重新识别库。我们引入了一种更强大的模块化、可扩展设计,使研究人员和从业者可以轻松地将他们的oven设计的模块插入reid系统,而无需重复编写代码基,从而进一步快速地将研究思路转换为生产模型。可管理的系统配置使其更加灵活和可扩
展,易于扩展到一系列任务,如一般的图像检索和人脸识别等。在 FastRelD的基础上,我们提供了许多先进的预训练模型,用于人识别、跨领域人识别、部分人识别和车辆识别等多种任务,未来我们还将发布人脸识别和物体检索模型。此外,我们希望库可以提供一个公平的比较不同的方法。
最近, FastRelD已经成为JDA研究中广泛使用的开源库之一。我们将不断完善它,并向其添加新特性。我们热忱欢迎个人、实验室使用我们的开源库,期待与您携手加速人工智能研究,实现技术突破。
2. Higlight of FastReID
FastRelD为培训、评估、调整和模型部署提供了一个完整的工具包。此外,Fas-tReD提供强大的基线,能够在多个任务上实现最先进的性能。
模块化和灵活的设计。在 FastRelD中,我们引入了一种模块化设计,允许用户将定制设计的模块插入到重新识别系统的几乎任何部分。帮助用户快速验证新思路,而不需要重写数十万行代码。
易于管理的系统配置。在PyTorch中实现的 FastRelD,能够在多GPU服务器上提供快速培训。模型结构、培训和测试可以用YAML文件方便定义,FastReID支持许多可选组件,如主干(backbone)、头聚合层(head aggregation layer)和损失函数(loss function),和训练策略(training strategy)。
丰富的评估系统。目前,许多研究者仅提供了单一的CMC评价指标。为满足实际场景中模型部署的需求, FastRelD提供了更为丰富的评价指标(不仅实现了CMC评价指标),如ROC和mINP,能够更好地反映模型的性能。
易于工程部署。太深的模型很难部署在边缘计算硬件和人工智能芯片中,因为耗时的推理和无法实现的层。FastRelD不仅实现了知识蒸馏模块,以获得更精确、高效的轻量级模型。FastRelD还提供了一个转换工具,如 PyTorch-Caffe和 PyTorch-TensorRT实现快速的模型部署。
众多的最先进的pre-trained模型。FastRelD提供了最先进的推理模型,包括人员重识别、部分可见的人员重识别、跨域人员重识别和车辆重识别。我们计划发布这些预先训练好的模型FastRelD很容易扩展到一般的对象检索和人脸识别。我们希望一个共同的软件能把先进的新思想应用到应用中去。
3. Architecture of FastReID
在本节中,我们将详细介绍 FastRelD的管道,如图1所示。整个流水线由图像预处理、主干、聚合和head四个组成,我们将逐一详细介绍。

图1. FastReID库的管道 (上下分别为训练和推理)
3.1. Image Pe-processing
预处理Pre-processing,其实就是各种数据增广方法,如 Resize,Flipping,Random erasing,Auto-augment,Random patch,Cutout等;
收集到的图像大小不同,我们首先将图像调整为固定大小的图像。图像可以批量打包,然后输入到网络中。为了获得更健壮的模型,翻转(flipping)作为一种数据增强方法,通过镜像源图像使数据更加多样化。随机擦除(Random erasing)、随机 patch(Random patch)、随机 patch[1]和 Cutout[2]也是在图像中随机选取一个矩形区域,用随机值、另一个图像 patch和零值擦除其像素点的增强方法,使模型有效降低过拟合风险,对遮挡具有鲁棒性。自动增强(Auto-augment)是基于自动技术来实现有效的数据增强,以提高特征表示的鲁棒性。该算法采用自动搜索算法来寻找平移、旋转和剪切等图像处理函数的融合策略。

图2. 图像预处理
3.2. Backbone
骨干网(Backbone),包括主干网的选择(如ResNet,ResNest,ResNeXt等)和可以增强主干网表达能力的特殊模块(如non-local、instance batch normalization (IBN)模块等);
骨干网络是推断图像特征图的网络,如没有最后average pooling layer的 ResNet。 FastRelD实现了三个不同的主干,包括 ResNet[3]、ResNext[4]和 ResNeSt[5]。我们还将注意力类non-local[6]模块和instance batch normalization(IBN)[7]模块添加到主干中,以学习更健壮的特性。
3.3. Aggregation
聚合模块(Aggregation),用于将骨干网生成的特征聚合成一个全局特征,如max pooling, average pooling, GeM pooling , attention pooling等方法;
聚合层旨在将主干生成的特征图聚合为一个全局特征。我们将介绍四种聚合方法:max pooling、average pooling、GeM pooling和attention pooling。pooling层取![]() 输入,生成一个向量
输入,生成一个向量![]() 作为 pooling过程的输出,其中W,H,C分别表示 feature map的宽度,高度和通道。在最大池的情况下全局向量
作为 pooling过程的输出,其中W,H,C分别表示 feature map的宽度,高度和通道。在最大池的情况下全局向量![]() ,平均池化,GeM池化和注意池化分别由下面给出。
,平均池化,GeM池化和注意池化分别由下面给出。
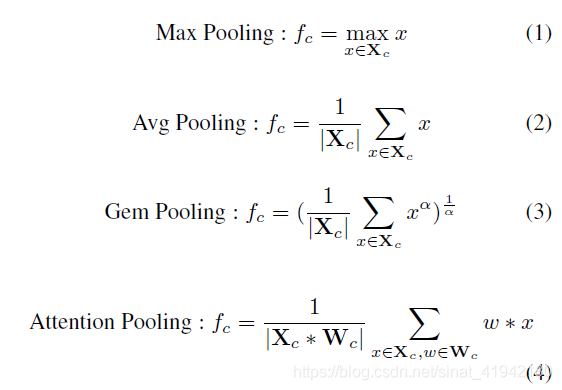
其中,![]() 是控制系数且
是控制系数且![]() 是softmax注意力权重。
是softmax注意力权重。
3.4. Head
Head 模块,用于对生成的全局特征进行归一化、纬度约减等。
Head是对聚合模块生成的全局向量进行处理的部分,包括批归一化(BN)Head(batch normalization head)、线性Head(Linear head)和简化Head(Reduction head)。三种类型的头如图3所示,线性头只包含一个decision层,BN头包含一个BN层和一个decision层,简化头包含conv+BN+relu+dropout操作,一个reduction层和一个decision层。
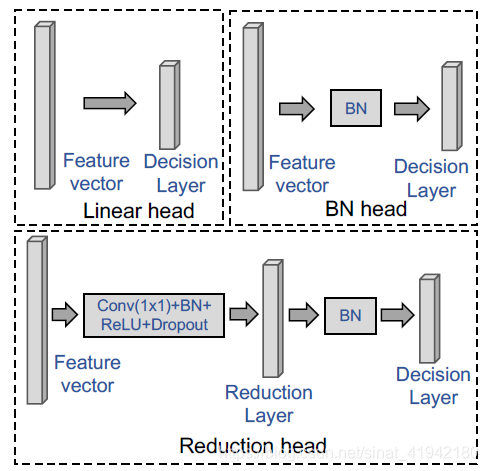
图3. FastReID中不同head的实现
批量归一化[8]用于解决内部协变位移,因为很难训练具有饱和非线性的模型。给定一批特征向量![]() (m为一个批次中的样本数),则bn层的特征向量
(m为一个批次中的样本数),则bn层的特征向量![]() 可计算为
可计算为
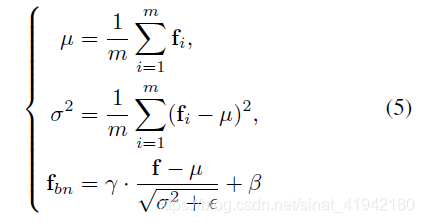
在这里![]() 和
和![]() 是可培训的scale和shift参数,
是可培训的scale和shift参数,![]() 是为数值稳定性添加到小批次(mini-batch)方差的常数。
是为数值稳定性添加到小批次(mini-batch)方差的常数。
简化层(Reduction layer)旨在将高维特征变成低维特征,即2048维-512维。
决策层(Decision layer)输出不同类别的概率,区分不同类别,用于后续的模型训练。
4. Training
4.1. Loss Function
特别值得一提的是其损失函数,不仅包括常见的Cross-entropy loss, Triplet loss,Arcface loss,还实现了今年上半年刚出的旷视CVPR 2020 Oral 论文中的Circle loss!(被认为是目前在各种度量学习任务中表现最好的)可见FastReID开发团队紧跟前沿。
在Fast-ReID中实现了四种不同的损失函数。
交叉熵损失(Cross-entropy loss)通常用于多分类的一种,可以定义为
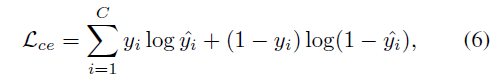
其中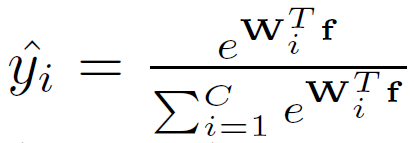 ,交叉熵损失使得logit预测值与地面真实值接近。它鼓励最大logit与其他所有logit之间的差异变得更大,而这与有界梯度(bounded gradient)结合在一起降低了模型的适应能力,导致模型对其预测过于自信。这进而会导致过拟合。为了建立一个能很好地推广的鲁棒模型,谷歌 Brain提出了标签平滑的方法来解决这个问题。它鼓励倒数第二层的激活靠近正确类的模板,与不正确类的模板距离相同。因此交叉熵损失的 ground truth label可定义为
,交叉熵损失使得logit预测值与地面真实值接近。它鼓励最大logit与其他所有logit之间的差异变得更大,而这与有界梯度(bounded gradient)结合在一起降低了模型的适应能力,导致模型对其预测过于自信。这进而会导致过拟合。为了建立一个能很好地推广的鲁棒模型,谷歌 Brain提出了标签平滑的方法来解决这个问题。它鼓励倒数第二层的激活靠近正确类的模板,与不正确类的模板距离相同。因此交叉熵损失的 ground truth label可定义为![]() 和
和
![]() 。
。
Arcface loss[9]将笛卡尔坐标映射到球坐标。它将logit转换成![]()
![]() ,其中
,其中![]() 是权重
是权重![]() 和特征
和特征![]() 的角度,它通过
的角度,它通过![]() 正则化修复了单个权重
正则化修复了单个权重![]()
![]() ,也通过
,也通过![]() 正则化修复了嵌入特性f,并且改变大小为
正则化修复了嵌入特性f,并且改变大小为![]() 。所以
。所以![]()
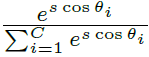 。为了同时增强类内紧致性和类间差异,Arcface在类内度量中添加了角边缘惩罚m
。为了同时增强类内紧致性和类间差异,Arcface在类内度量中添加了角边缘惩罚m
,所以![]() 被重写为
被重写为 。
。
圆的损失(Cicle loss)。圆损失的推导过程这里不详细描述,可以参考[10]。
三联体损失(Triplet loss)确保一个特定的人的图像相比于其他人的任何图像,更接近于同一个人的其他图像。在图像嵌入空间中,想让一个特定的人的一个图像![]() (anchor),相比于任何其他人的任何图像
(anchor),相比于任何其他人的任何图像![]() (negative),更接近同一个人的所有其他图像
(negative),更接近同一个人的所有其他图像![]() (positive)。因此,我们需要
(positive)。因此,我们需要![]() ,其中
,其中![]() 是关于人的图像对的距离度量。那么N个样本的Triplet Loss被定义为
是关于人的图像对的距离度量。那么N个样本的Triplet Loss被定义为![]() ,其中m是一对正和负之间的边界。
,其中m是一对正和负之间的边界。
4.2. Training Strategy
训练策略,包含Learning rate warm-up,Backbone freeze等。
图4显示了包含多种技巧的训练策略,包括不同迭代(diffierent iteration)、网络的学习率热身(warm-up)和冻结(freeze)。
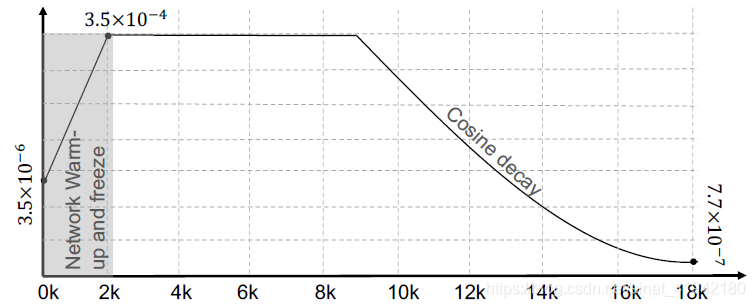
图4. 作为迭代次数的函数的学习速率曲线
Learning rate warm-up有助于减缓模型训练的初始阶段的小批量过早过拟合。此外,它有助于保持模型深层的稳定性。因此,我们会 给一 个非常小的学习率,如在最初的训练是![]() ,然后在2k个迭代里逐渐增加它。然后在2k个迭代到9k个迭代里,学习率一直保持在
,然后在2k个迭代里逐渐增加它。然后在2k个迭代到9k个迭代里,学习率一直保持在![]() 。然后,在9k个迭代之后,学习速率以余弦规则从
。然后,在9k个迭代之后,学习速率以余弦规则从![]() 下降到
下降到![]() ,在18k个迭代后结束。
,在18k个迭代后结束。
Backbone freeze. 为了重新训练一个分类网络以满足我们的任务要求,我们使用从任务中收集的数据对ImageNet预训练的模型进行微调。通常我们添加一个收集网络的分类器,如ResNet,并随机初始化分类器参数。为了更好地初始化分类器的参数,我们在训练开始时只训练分类器参数,并且冻结网络参数,不进行更新(2k次迭代)。经过2k次迭代后,将释放网络参数进行端到端训练。
5. Testing
5.1. Distance Metric
度量部分,除支持常见的余弦和欧式距离,还添加了局部匹配方法 deep spatial reconstruction (DSR);
在FastReID中实现了欧几里德测度和余弦测度。并实现了一种局部匹配方法:深度空间重构(DSR)。
深度空间重建(Deep Spatial rexonstruction)。假设有一对行人图像![]() 和
和![]() ,
,![]() 对应的主干网络(backbone)的空间特征图
对应的主干网络(backbone)的空间特征图![]() 的维度为
的维度为![]()
![]() ,
,![]() 对应的主干网络(backbone)的空间特征图
对应的主干网络(backbone)的空间特征图![]() 的维度为
的维度为![]() 。从
。从![]() 个区域得到的总共
个区域得到的总共![]() 个空间特征整合成一个矩阵
个空间特征整合成一个矩阵![]() ,其中
,其中![]()
![]() 。与此同时,我们也构建了gallery的特征矩阵
。与此同时,我们也构建了gallery的特征矩阵 ![]()
![]() ,其中
,其中![]() 。然后,
。然后,![]() 可以在
可以在![]() 中找到最相似的空间特征,并且它的匹配分数为
中找到最相似的空间特征,并且它的匹配分数为![]() 。因此,我们试着获得关于
。因此,我们试着获得关于![]() 的所有
的所有![]() 的空间特征的的相似的分数,而且最后的匹配分数可以被定义为
的空间特征的的相似的分数,而且最后的匹配分数可以被定义为![]() 。
。
5.2. Post-processing
后处理部分,指对检索结果的处理,包括K-reciprocal coding 和 Query Expansion (QE) 两种重排序方法。
在FastReID中的两种re-rank方法:k -倒数编码[11](K-reciprocal coding)和查询扩展[12](Query Expansion)。
查询扩展(Query expansion)。给定一个查询图像,并使用它来查找![]() 个相似的图库图像。定义查询特征为
个相似的图库图像。定义查询特征为![]() ,定义
,定义![]() 个相似库特征为
个相似库特征为![]() 。然后将验证过的库特征与查询特征进行平均,构造新的查询特征。因此,新的查询特征
。然后将验证过的库特征与查询特征进行平均,构造新的查询特征。因此,新的查询特征![]() 可以定义为
可以定义为
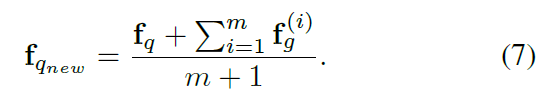
然后使用新的查询特征![]() 进行后续图像检索。QE可以很容易地用于实际场景。
进行后续图像检索。QE可以很容易地用于实际场景。
5.3. Evaluation
对于性能评估,我们采用了大多数人再识别文献中的标准度量,即累积匹配治愈(CMC)和平均平均精度(mAP)。此外,我们还增加了两个指标:受试者工作特性(ROC)曲线和平均负惩罚(mINP)[13]。
5.4. Visualization
我们提供了检索结果的排名列表工具,有助于检查我们的算法中尚未解决的问题。
6. Deployment
一般来说,模型越深,性能越好。但是,深度过深的模型不容易部署到边缘计算硬件和AI芯片上,因为1)需要耗时的推理;2)在AI芯片上很难实现很多层。考虑到这些原因,我们在FastReID中实现了知识蒸馏模块,实现了高精度、高效率的轻量化模型。
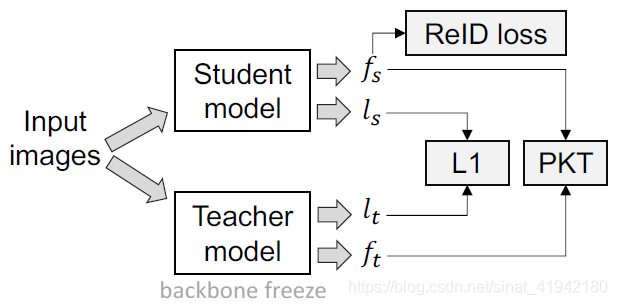
图5. 知识蒸馏模块说明
如图5所示,在reid数据集上给出一个预训练的Student model和一个预训练的Teacher model,Teacher model是一个带有non-local模块、ibn模块和一些有用的tricks的更深入的模型。Student model简单而肤浅。采用双流方式(two-stream)训练带有teacher 主干冻结的Student model。Student model和Teacher model分别输出分类器logits ![]() 和特征
和特征![]() 。我们想让Student model尽可能多地学习Teacher model的分类能力,logit学习可以定义为
。我们想让Student model尽可能多地学习Teacher model的分类能力,logit学习可以定义为
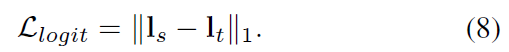
为了保证Student model和Teacher model在特征空间分布上的一致性,使用基于Kullback-Leibler散度的概率知识转移模型对Student model进行优化:
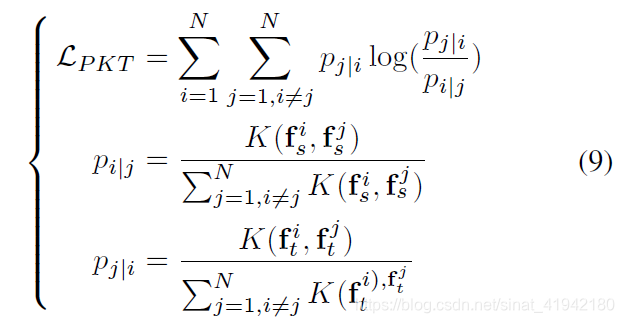
其中![]() 是余弦相似度测量。
是余弦相似度测量。
同时,student model需要ReID loss ![]() 来优化整个网络。因此,总损失为:
来优化整个网络。因此,总损失为:
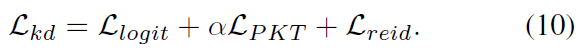
训练完成后,使用![]() 进行推理。
进行推理。
我们还在在FastReID库里提供了模型转换工具(PyTorch->Caffe和PyTorch->TensorRT)。
7. Projects
7.1. Person Re-identification
数据集(Datasets)。用于评估FastReID的三种行人re-id基准数据集:Market1501[27], DukeMTMC [28], MSMT17[29]。我们不会在这里讨论数据库的细节。
FastReID设置(FastReID Setting)。我们使用翻转,随机擦除和自动增强来处理训练图像。带有Non-local模块的IBN-ResNet101用作主干网络。gem pooling 和bnneck分别作为head层和aggregation层。对于batch hard triplet loss函数,每批次4个目标,每个目标有16幅不同的图像,我们采用cicle loss 和triplet loss对整个网络进行训练。
结果(Result)。表1列出了在CVPR、ICCV、ECCV 2018-2020年发布的最先进的算法,在rank-1/mAP精度方面,FastReID在市场上取得了最好的性能,分别为Market1501 96.3%(90.3%),DukeMTMC 92.4%(83.2%)和MSMT17 85.1%(65.4%)。图6显示了三个基准数据集的ROC曲线。
FastReID 取得了三大数据集上的所有评价指标的最高精度!超越了之前最高的 CVPR 2020 的 Circle Loss!
可见FastReID的实现质量很高,且其包含的各个模块的组合是十分有效的。
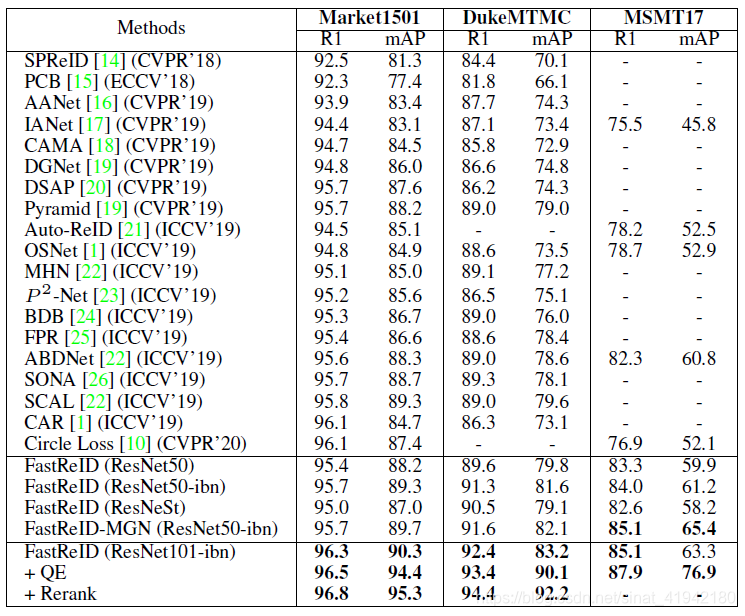
表1. Market1501,DukeMTMC和MSMT17数据集的人员重识别性能比较。
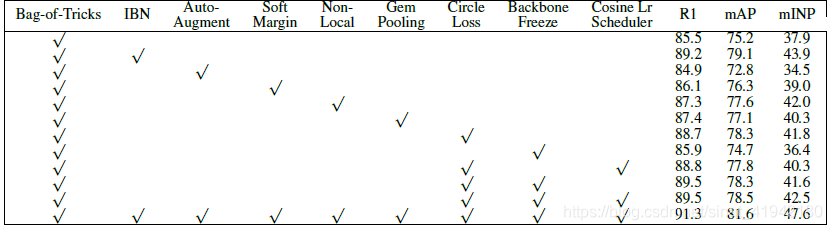
表2. FastReID在DukeMTMC上的消融研究。(ResNet50,384x128)。

图6. FastReID的三个基准数据集的ROC曲线以及类内和类间样本的分布曲线(ResNet101-ibn)
7.2. Cross-domain Person Re-identification
问题的定义(Problem definition)。跨域人员重识别是指调整模型使得其在有标注的源域数据集训练而在另一个无标注的目标域数据集仍然具有推广性,不同的域往往图像差异很大。
设置(Setting)。提出了一种跨域方法FastReIDMLT,该方法采用混合标签传输的方式,通过多粒度策略学习伪标签。我们首先使用源域数据集训练一个模型,然后使用目标域数据集的伪标签对预训练的模型进行微调。FastReID-MLT是由ResNet50主干、gem pooling和bnneck head实现的。对于batch hard triplet loss函数,一个batch包含4个目标,每个目标有16张不同的图像,使用circle loss和triplet loss来训练整个网络。详细配置可以在GitHub网站上找到。FastReID-MLT的框架如图7所示。
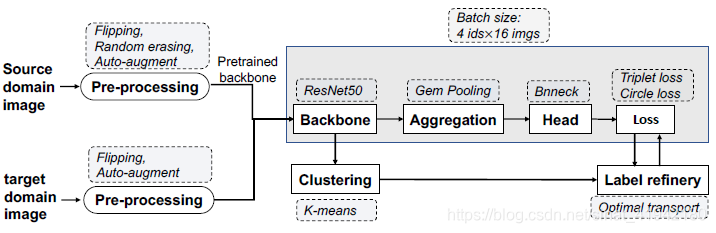
图7. FastReID-MLT的框架
结果(Result)。表3显示了几个数据集的结果,FastReID-MLT在D->M,M->D的设置里可以达到92.7%(77。5%),82.7%(69.2%)。其结果与监督学习结果相近。
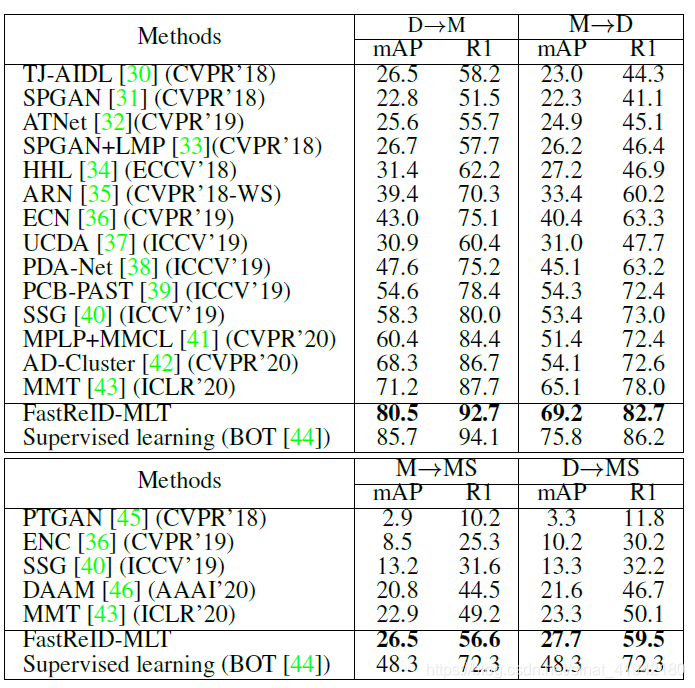
表3. 在三个基准数据集上与无监督跨域re-id SOTA方法的性能比较。“BOT”指的是“小把戏包”方法,它是ReID任务中的一个强大的基线。M: Market1501, D: DukeMTMC, MS: MSMT17
可见在FastReID-MLT超过了绝大多数该方向的算法,且接近监督学习方法的结果。
7.3. Partical Persion Re-identificastion
问题的定义(Problem denification)。部分可见的人员重识别(Partial Person Re-identification)即只有某人的部分不完整图像,在候选图像中检索这个人。
设置(Setting)。设置如图8所示。
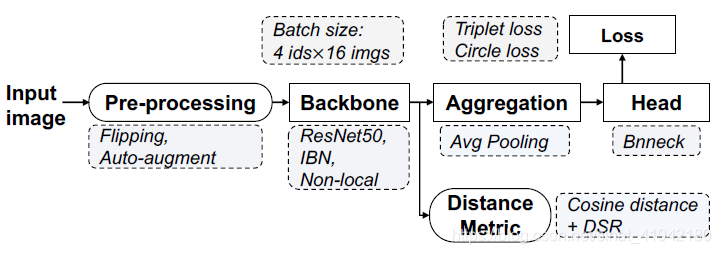
图8. FastReID-DSR的框架
结果(Result)。表4显示了在PartialREID、OccludedREID和PartialiLIDS数据集上的结果。在rank-1/mAP指标上,FastReID-DSR可以达到82.7%(76.8%)、81.6%(70.9%)和73.1%(79.8)。
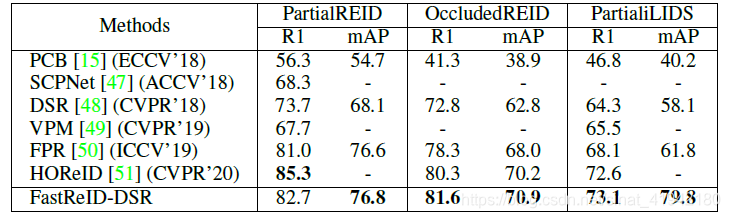
表4. 在PartialREID、OccludedREID和PartialiLIDS数据集上最新方法的比较
FastReID-DSR 同样达到了在绝大多数指标上的最好结果。
7.4. Vehicle Re-identification
数据集(Datasets)。三个车辆re-id基准数据集:VeRi,VehicleID和VERI-Wild被用于评估提出的FastReID。我们不会在这里讨论数据库的细节。
设置(Settings)。设置如图9所示。
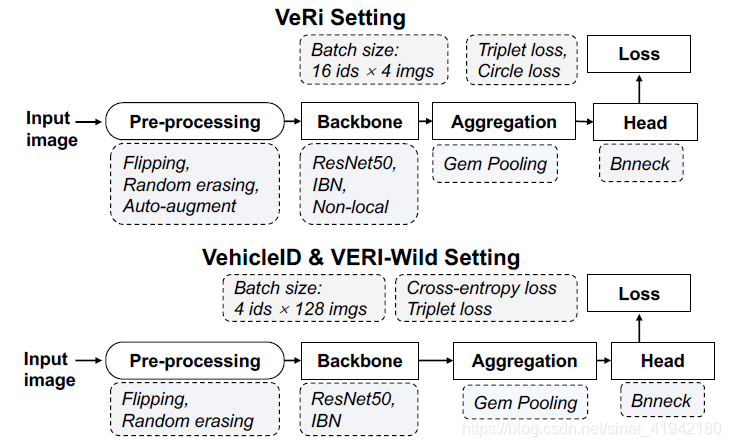
图9. 在VehicleID和VERI-Wild上的FastReID的框架
结果(Result)。表5、表6、表7列出了2015-2019年发布的最先进的算法。FastReID在VeRi、vehicle和VERI-Wild上的性能最好。
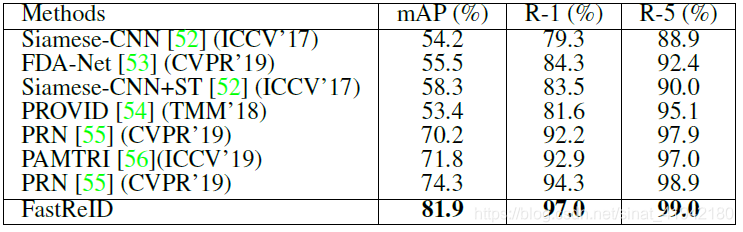
表5. 在VeRi数据集上比较最先进的车辆重新识别方法
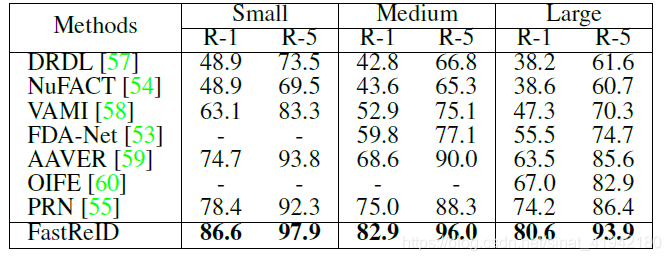
表6. 在车辆数据集上比较最先进的车辆重新识别方法
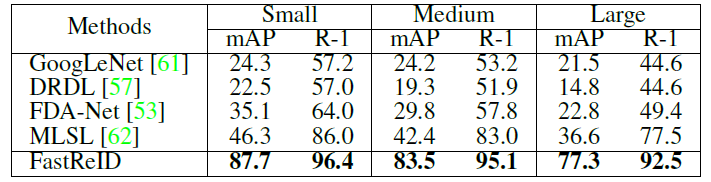
表7. 在VERI-Wild数据集上比较最先进的车辆重新识别方法
在这个问题上结果异常好,FastReID 匪夷所思地实现了对17-19年出现的SOTA算法碾压式超越!
8. Conclusion
本文介绍了一个用于重新识别的开放源码库FastReID。实验结果表明,该算法在人员再识别和车辆再识别等多种任务上具有通用性和有效性。我们共享FastReID是因为开源研究平台对于整个社区(包括学术界和工业界的研究人员和从业者)在人工智能方面的快速发展至关重要。我们希望释放FastReID将继续加速在人员/车辆重新识别方面的进展。我们也期待相互合作,相互学习,共同推动计算机视觉的发展。
为什么FastReID在各种任务中都表现这么抢眼?我想就如YOLOv4一样,不是去创造新算法而是组合各种最佳实践,开发团队实现了业界验证过的诸多有效的SOTA算法和tricks,这也使得它对于实际项目的开发者更具吸引力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









