







 本文介绍了作者使用Python不依赖任何深度学习框架,手写出LeNet卷积神经网络的过程。核心代码已给出,并在GitHub上分享。文章强调了设计思路中的关键点,如使用numpy等库,类封装,以及初始化权重、反向传播和softmax优化的注意事项。通过训练,loss减少且accuracy提升,验证了代码的正确性。
本文介绍了作者使用Python不依赖任何深度学习框架,手写出LeNet卷积神经网络的过程。核心代码已给出,并在GitHub上分享。文章强调了设计思路中的关键点,如使用numpy等库,类封装,以及初始化权重、反向传播和softmax优化的注意事项。通过训练,loss减少且accuracy提升,验证了代码的正确性。
目的
在学习完BP神经网络的推导以及卷积神经网络的推导后,我已经用python(不带任何深度学习框架!)自己手写出一个LeNet卷积神经网络了!同时欢迎大家指出问题,一起学习与讨论~
由于篇幅限制,这里只会贴出核心代码(保证运行正确无误!!)。
打个广告:https://github.com/Site1997/LeNet-python
(这里包含所有代码,下载后直接运行LeNet.py即可~)
设计思路
本次设计我使用了numpy,scipy以及skimage库,为了简明易懂,使用类封装的方法,做了一个仿LeNet的神经网络,结构如下:(默默贴一个结构图,侵删)
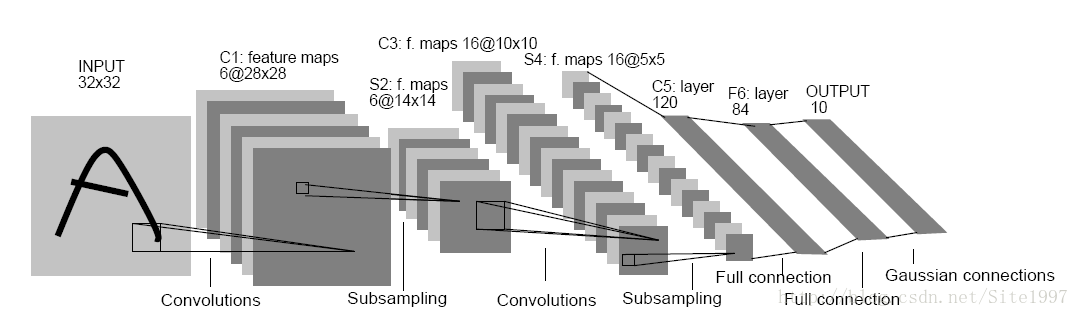
我设计的结构和上述图片的结构是类似的,唯一区别是我将每一层的输入维数都减小了一些,譬如输入是28*28的图片,全连接层的神经元个数变小了等等(加快运行速度)。具体网络结构可以见代码里面 超级详细的注释。
首先,我定义了一个LeNet神经网络的类,它包含初始化函数,前向传播函数,后向传播函数,卷积层函数,池化层函数,激励函数以及softmax函数。主函数中调用了fetch_MNIST.py,以便得到的数字图像和标签。
其次,我做出了上述函数的实现。对了!我写这段代码的过程中有几个 trick需要注意:
- softmax写法要优雅(避免 ex e x 浮点溢出)
- 全连接层和卷积层的反向传播一定要仔细写(卷积核要不要倒转180度,矩阵要不要转置)
- 初始化的权重和学习率一定要调小调小再调小!(否则更新权重时,参数大小会剧升导致浮点溢出)(这里我用的是xavier的初始化方法)
最后,我们定义好batch size,学习率以及最大迭代次数就可以跑起来啦!
核心代码以及结果
代码实现
# -*- coding: utf-8 -*-
'''
Author: Site Li
Website: http://blog.csdn.net/site1997
'''
import numpy as np
from scipy.signal import convolve2d
from skimage.measure import block_reduce
import fetch_MNIST
class LeNet(object):
#The network is like:
# conv1 -> pool1 -> conv2 -> pool2 -> fc1 -> relu -> fc2 -> relu -> soft 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









