







LeNet 是一种经典的卷积神经网络(Convolutional Neural Network,CNN)架构,由 Yann LeCun 和他的团队在 1989 年首次提出,用于手写数字识别,尤其是对 MNIST 数据集的分类任务。LeNet 是深度学习历史上的一个里程碑,是现代卷积神经网络的奠基模型之一。
LeNet 的基本架构
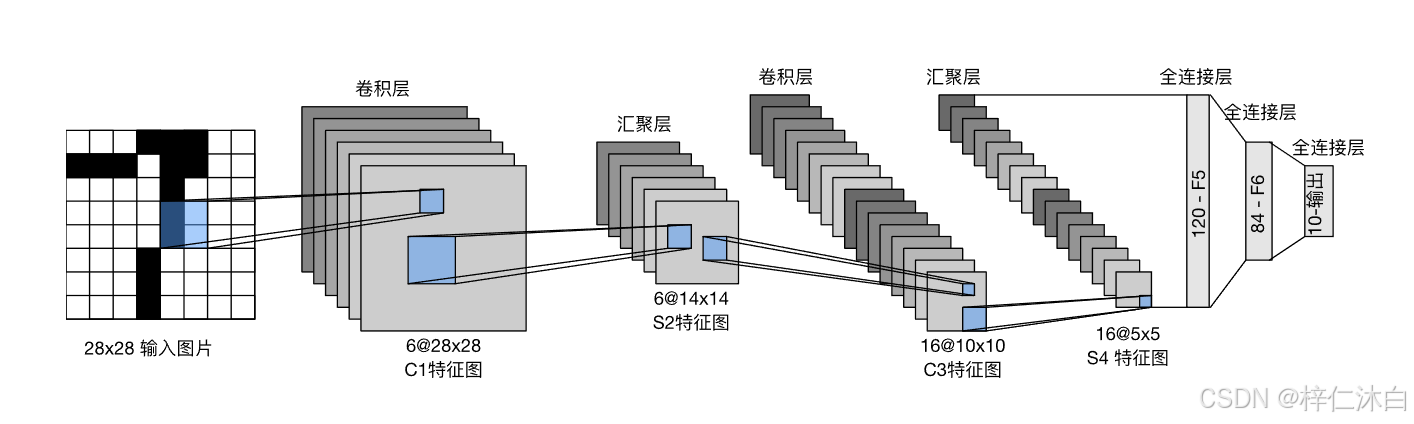
LeNet-5 是 LeNet 系列中最著名的版本,其架构包括以下层次:
-
输入层:
- 输入的是灰度图像,大小为 (32 \times 32) 像素。
- 如果输入是 MNIST 数据(通常为 (28 \times 28) 的图像),需要先将其调整到 (32 \times 32)。
-
卷积层 C1:
- 使用 6 个 (5 \times 5) 的卷积核(filter),步幅为 1,无填充。
- 输出的特征图大小为 (28 \times 28 )。
- 经过 ReLU 激活函数。
-
池化层 S2(子采样层):
- 平均池化(Average Pooling)或最大池化(Max Pooling)。
- 每个 (2 \times 2) 区域做降采样,步幅为 2。
- 输出特征图大小为 (14 \times 14)。
-
卷积层 C3:
- 使用 16 个 (5 \times 5) 的卷积核。
- 输出特征图大小为 (10 \times 10)。
- 经过 ReLU 激活函数。
-
池化层 S4:
- 再次应用 (2 \times 2) 的池化,输出大小为 (5 \times 5)。
-
全连接层 F5:
- 输入大小 (5 \times 5 \times 16 = 400),通过全连接层映射到 120 个神经元。
- 经过 ReLU 激活函数。
-
全连接层 F6:
- 120 个神经元进一步映射到 84 个神经元。
-
输出层:
- 最终使用一个 Softmax 层,输出 10 个类别对应的概率(用于手写数字 0 到 9 的分类)。
- 最终使用一个 Softmax 层,输出 10 个类别对应的概率(用于手写数字 0 到 9 的分类)。
LeNet 的关键特点
-
卷积层和池化层交替使用:
- 卷积层提取空间特征。
- 池化层用于降低特征图的分辨率,减少计算量并增加特征的不变性。
-
层次化特征学习:
- 初始层学到的是简单的边缘和纹理特征。
- 深层捕获更抽象的模式。
-
参数共享:
- 卷积核在特征图上滑动,减少了模型的参数量。
-
小型网络架构:
- 与现代深度神经网络(如 ResNet 或 Transformer)相比,LeNet 的规模很小,适合在当时有限的硬件资源上运行。
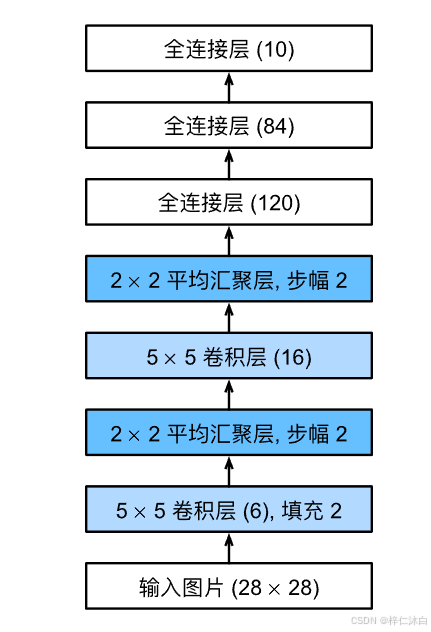
网络模型搭建
根据网络模型的架构图一层层搭建。
class MyLeNet5(nn.Module): # 定义一个继承自 nn.Module 的类
def __init__(self):
super(MyLeNet5, self).__init__() # 初始化父类
# 定义 LeNet-5 网络的层结构
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
# 第一层卷积:输入通道为 1(灰度图像),输出通道为 6,卷积核大小为 5×5,padding=2 保持输出尺寸不变
self.Sigmoid = nn.Sigmoid() # 定义 Sigmoid 激活函数
self.s2 = nn.AvgPool2d(kernel_size=2, stride=2)
# 第二层:平均池化层,窗口大小为 2×2,步幅为 2,将特征图缩小一半
self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 第三层卷积:输入通道为 6,输出通道为 16,卷积核大小为 5×5
self.s4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 第四层:平均池化层,窗口大小为 2×2,步幅为 2
self.c5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 第五层卷积:输入通道为 16,输出通道为 120,卷积核大小为 5×5
self.flatten = nn.Flatten() # 展平操作,将多维特征图转为一维向量
self.f6 = nn.Linear(120, 84)
# 全连接层:输入为 120,输出大小为 84 的向量
self.output = nn.Linear(84, 10)
# 输出层:输入为 84,输出大小为 10 的向量(10 个分类)
def forward(self, x): # 定义前向传播逻辑
x = self.Sigmoid(self.c1(x)) # 第一层卷积 + 激活
x = self.s2(x) # 第二层池化
x = self.Sigmoid(self.c3(x)) # 第三层卷积 + 激活
x = self.s4(x) # 第四层池化
x = self.c5(x) # 第五层卷积
x = self.flatten(x) # 展平为一维向量
x = self.f6(x) # 第六层全连接层
x = self.output(x) # 第七层输出层
return x
可以传入一个随机的张量,能够看到通过网络计算之后能够得到一个包含10个数字的张量。
因为传入X的批次为1,所以只有一组。
这10个数字的意思是和每一个类型的相似程度,这个例子中是识别 MNIST 手写数字,所以对应的类别就是‘0’,‘1’……‘9’ 这十个数字。就像这个随机张量和‘0’的相似度最高(第一个值最大),我们就可以认为这张图片是‘0’。
x = torch.rand([1,1,28,28])
model = MyLeNet5()
y = model(x)
y
tensor([[-0.2379, -0.0188, 0.0099, -0.0575, -0.0633, -0.2062, 0.1024, -0.0357,
-0.0536, -0.3207]], grad_fn=`<AddmmBackward0>`)
数据集加载与处理
datasets函数能加载所需要的MNIST手写数据集。如果本地没有数据集的话,会自动下载。
DataLoader函数提供了批量数据加载功能,将已经导入的数据集按照批次分好,并提供迭代器来进行迭代。
- 参数
shuffle=True可以打乱迭代器内的数据,防止在计算的过程中网络记住顺序。
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor() #预处理
batch_size=16
workers_num=4 #读取数据的进程数
#加载训练数据集
mnist_train = datasets.MNIST(
root="data",train=True,transform=trans,download=True)
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,#shuffle=True: 这表示在每个 epoch(训练周期)开始时,数据会被随机打乱。
num_workers=workers_num)
#加载测试数据集
mnist_test = datasets.MNIST(
root="data", train=False, transform=trans, download=True)
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=True,#shuffle=True: 这表示在每个 epoch(训练周期)开始时,数据会被随机打乱。
num_workers=workers_num)
mnist_train[0][0].shape
torch.Size([1, 28, 28])
调用net里面定义的模型,将模型转到转到GPU(如果GPU存在的话)
device= "cuda" if torch.cuda.is_available() else 'cpu'
model=MyLeNet5().to(device)
#定义一个损失函数(交叉熵)
loss_fn = nn.CrossEntropyLoss()
#定义一个优化器(随机梯度下降)
#lr=1e-3:学习率(Learning Rate)
# momentum=0.9 引入动量,提高收敛速度并减少震荡
optimizer = torch.optim.SGD(model.parameters(),lr=1e-3,momentum=0.9)
通过调整学习率,可以防止梯度变化过快。周期性减小学习率可以提高模型训练的稳定性。
#调整学习率,每隔10epoch,变为原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.1)
定义训练函数
def train(dataloader, model, loss_fn, optimizer):
model.train()
loss, current, n = 0.0, 0.0 ,0
#按批次取出数据,X是图片,y是标签
for batch, (X,y) in enumerate(dataloader):
#向前传播
X, y = X.to(device), y.to(device) #把数据传入显卡
output = model(X)
cur_loss = loss_fn(output, y) # 计算损失函数
_, pred = torch.max(output,axis=1)
#计算此轮精确度
cur_acc = torch.sum(y == pred) /output.shape[0]
#反向传播
optimizer.zero_grad() #清空梯度
cur_loss.backward() # 反向传播
optimizer.step() # 更新权重
loss += cur_loss.item() #累加此批次的loss值
current += cur_acc.item() #累加此批次的精确度
n = n + 1
print("train_loss" + str(loss/n))
print("train_acc" + str(current/n))
定义评估函数
def val(dataloader, model, loss_fn):
model.eval() # 切换到评估模式
loss, current, n = 0.0, 0.0, 0
with torch.no_grad(): # 禁止梯度计算
for batch, (X, y) in enumerate(dataloader):
# 向前传播
X, y = X.to(device), y.to(device) # 把数据传入显卡
output = model(X)
cur_loss = loss_fn(output, y) # 计算损失
_, pred = torch.max(output, axis=1) # 获取预测结果
# 计算此轮精确度
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item() # 累加此批次的loss值
current += cur_acc.item() # 累加此批次的精确度
n += 1
print("val_loss: " + str(loss / n))
print("val_acc: " + str(current / n))
return current / n
训练
进行epoch =20 次的训练,选取所有次数中,准确值最高的一次作为最终的结果(因为最后一次训练不一定是精确度最高的)。并保存为MNIST_model.pth模型文件。
#训练轮次
epoch = 20
max_acc = 0
for t in range(epoch):
print(f"epoch{t+1}\n----------------")
train(train_iter, model, loss_fn, optimizer)
a = val(test_iter, model, loss_fn)
#保存最好的模型权重
if a>max_acc :
folder = 'save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
max_acc = a
print("save best model")
torch.save(model.state_dict(),"save_model/MNIST_model.pth")
print("Done!")
| epoch1 |
|---|
| train_loss1.7376496023019155 |
| train_acc0.4217166666666667 |
| val_loss: 0.6831068386793137 |
| val_acc: 0.7862 |
| save best model |
| Done! |
| epoch2 |
| ---------------- |
| train_loss0.5122988376716773 |
| train_acc0.8426 |
| val_loss: 0.39851884398460385 |
| val_acc: 0.8814 |
| save best model |
| Done! |
…………………
| epoch20 |
|---|
| train_loss0.07184810269450924 |
| train_acc0.9780333333333333 |
| val_loss: 0.06246635895390064 |
| val_acc: 0.9792 |
| Done! |
测试函数
from torch.autograd import Variable
from torchvision.transforms import ToPILImage
import matplotlib.pyplot as plt
这是一个函数,用于绘制测试集的图像,让我们能更直观的看到测试图像。
# 定义一个函数,绘制图像和标题
def show_images_with_predictions(imgs, preds, num_rows, num_cols, titles=None, scale=1.5):
"""绘制图像列表,并显示预测结果"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() # 将 axes 从二维数组转换为一维数组
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy(), cmap='gray')
else:
# PIL 图片
ax.imshow(img, cmap='gray')
ax.axes.get_xaxis().set_visible(False) # 隐藏 X 轴
ax.axes.get_yaxis().set_visible(False) # 隐藏 Y 轴
if titles:
ax.set_title(f"{titles[i]}\nPred: {preds[i]}")
return axes
将之前保存的MNIST_model.pth文件作为model导入。
选20张照片用作测试。
model.load_state_dict(torch.load("save_model/MNIST_model.pth"))
# 从测试集中取一个批次
size = 20
X, y = next(iter(data.DataLoader(mnist_test, batch_size=size)))
# 使用已加载的模型进行预测
model.eval()
with torch.no_grad():
output = model(X.to(device))
preds = output.argmax(dim=1).cpu().numpy() # 获取预测标签
# 显示图像及预测结果
titles = [str(label.item()) for label in y]
show_images_with_predictions(X.reshape(size, 28, 28), preds, 2, (size + 1) // 2, titles=titles)
plt.show()
图像结果:

完整代码:
# %%
import os
import torch
from torch import nn
%matplotlib inline
import torchvision
from torch.optim import lr_scheduler
from torch.utils import data
from torchvision import transforms,datasets
# %% [markdown]
# ## 网络模型搭建
# 
# %%
class MyLeNet5(nn.Module): # 定义一个继承自 nn.Module 的类
def __init__(self):
super(MyLeNet5, self).__init__() # 初始化父类
# 定义 LeNet-5 网络的层结构
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
# 第一层卷积:输入通道为 1(灰度图像),输出通道为 6,卷积核大小为 5×5,padding=2 保持输出尺寸不变
self.Sigmoid = nn.Sigmoid() # 定义 Sigmoid 激活函数
self.s2 = nn.AvgPool2d(kernel_size=2, stride=2)
# 第二层:平均池化层,窗口大小为 2×2,步幅为 2,将特征图缩小一半
self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
# 第三层卷积:输入通道为 6,输出通道为 16,卷积核大小为 5×5
self.s4 = nn.AvgPool2d(kernel_size=2, stride=2)
# 第四层:平均池化层,窗口大小为 2×2,步幅为 2
self.c5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
# 第五层卷积:输入通道为 16,输出通道为 120,卷积核大小为 5×5
self.flatten = nn.Flatten() # 展平操作,将多维特征图转为一维向量
self.f6 = nn.Linear(120, 84)
# 全连接层:输入为 120,输出大小为 84 的向量
self.output = nn.Linear(84, 10)
# 输出层:输入为 84,输出大小为 10 的向量(10 个分类)
def forward(self, x): # 定义前向传播逻辑
x = self.Sigmoid(self.c1(x)) # 第一层卷积 + 激活
x = self.s2(x) # 第二层池化
x = self.Sigmoid(self.c3(x)) # 第三层卷积 + 激活
x = self.s4(x) # 第四层池化
x = self.c5(x) # 第五层卷积
x = self.flatten(x) # 展平为一维向量
x = self.f6(x) # 第六层全连接层
x = self.output(x) # 第七层输出层
return x
# %% [markdown]
# 
# %%
x = torch.rand([1,1,28,28])
model = MyLeNet5()
y = model(x)
y
# %% [markdown]
# ## 数据集加载与处理
# %%
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0~1之间
trans = transforms.ToTensor() #预处理
batch_size=16
workers_num=4 #读取数据的进程数
#加载训练数据集
mnist_train = datasets.MNIST(
root="data",train=True,transform=trans,download=True)
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,#shuffle=True: 这表示在每个 epoch(训练周期)开始时,数据会被随机打乱。
num_workers=workers_num)
#加载测试数据集
mnist_test = datasets.MNIST(
root="data", train=False, transform=trans, download=True)
test_iter = data.DataLoader(mnist_test, batch_size, shuffle=True,#shuffle=True: 这表示在每个 epoch(训练周期)开始时,数据会被随机打乱。
num_workers=workers_num)
# %%
mnist_train[0][0].shape
# %% [markdown]
# 调用net里面定义的模型,将模型转到转到GPU
# %%
device= "cuda" if torch.cuda.is_available() else 'cpu'
model=MyLeNet5().to(device)
# %%
#定义一个损失函数(交叉熵)
loss_fn = nn.CrossEntropyLoss()
# %%
#定义一个优化器(随机梯度下降)
#lr=1e-3:学习率(Learning Rate)
# momentum=0.9 引入动量,提高收敛速度并减少震荡
optimizer = torch.optim.SGD(model.parameters(),lr=1e-3,momentum=0.9)
# %%
#调整学习率,每隔10epoch,变为原来的0.1
lr_scheduler = lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.1)
# %% [markdown]
# ### 定义训练函数
# %%
def train(dataloader, model, loss_fn, optimizer):
model.train()
loss, current, n = 0.0, 0.0 ,0
#按批次取出数据,X是图片,y是标签
for batch, (X,y) in enumerate(dataloader):
#向前传播
X, y = X.to(device), y.to(device) #把数据传入显卡
output = model(X)
cur_loss = loss_fn(output, y) # 计算损失函数
_, pred = torch.max(output,axis=1)
#计算此轮精确度
cur_acc = torch.sum(y == pred) /output.shape[0]
#反向传播
optimizer.zero_grad() #清空梯度
cur_loss.backward() # 反向传播
optimizer.step() # 更新权重
loss += cur_loss.item() #累加此批次的loss值
current += cur_acc.item() #累加此批次的精确度
n = n + 1
print("train_loss" + str(loss/n))
print("train_acc" + str(current/n))
# %% [markdown]
# ### 定义评估函数
# %%
def val(dataloader, model, loss_fn):
model.eval() # 切换到评估模式
loss, current, n = 0.0, 0.0, 0
with torch.no_grad(): # 禁止梯度计算
for batch, (X, y) in enumerate(dataloader):
# 向前传播
X, y = X.to(device), y.to(device) # 把数据传入显卡
output = model(X)
cur_loss = loss_fn(output, y) # 计算损失
_, pred = torch.max(output, axis=1) # 获取预测结果
# 计算此轮精确度
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item() # 累加此批次的loss值
current += cur_acc.item() # 累加此批次的精确度
n += 1
print("val_loss: " + str(loss / n))
print("val_acc: " + str(current / n))
return current / n
# %% [markdown]
# ## 训练
# %%
#训练轮次
epoch = 20
min_acc = 0
for t in range(epoch):
print(f"epoch{t+1}\n----------------")
train(train_iter, model, loss_fn, optimizer)
a = val(test_iter, model, loss_fn)
#保存最好的模型权重
if a>min_acc:
folder = 'save_model'
if not os.path.exists(folder):
os.mkdir('save_model')
min_acc = a
print("save best model")
torch.save(model.state_dict(),"save_model/MNIST_model.pth")
print("Done!")
# %% [markdown]
# ## 测试函数
# %%
from torch.autograd import Variable
from torchvision.transforms import ToPILImage
import matplotlib.pyplot as plt
# %%
# 定义一个函数,绘制图像和标题
def show_images_with_predictions(imgs, preds, num_rows, num_cols, titles=None, scale=1.5):
"""绘制图像列表,并显示预测结果"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() # 将 axes 从二维数组转换为一维数组
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy(), cmap='gray')
else:
# PIL 图片
ax.imshow(img, cmap='gray')
ax.axes.get_xaxis().set_visible(False) # 隐藏 X 轴
ax.axes.get_yaxis().set_visible(False) # 隐藏 Y 轴
if titles:
ax.set_title(f"{titles[i]}\nPred: {preds[i]}")
return axes
# %%
model.load_state_dict(torch.load("save_model/MNIST_model.pth"))
# 从测试集中取一个批次
size = 20
X, y = next(iter(data.DataLoader(mnist_test, batch_size=size)))
# 使用已加载的模型进行预测
model.eval()
with torch.no_grad():
output = model(X.to(device))
preds = output.argmax(dim=1).cpu().numpy() # 获取预测标签
# 显示图像及预测结果
titles = [str(label.item()) for label in y]
show_images_with_predictions(X.reshape(size, 28, 28), preds, 2, (size + 1) // 2, titles=titles)
plt.show()



















 4224
4224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











