







卷积神经网络
为什么要用卷积神经网络?
1.可以处理空间结构丰富的数据(二维如图片,一维音频、文本和时间序列分析),关注数据的上下文信息(像素之间的相关性)
2.卷积神经网络需要的参数少于全连接架构的网络,而且卷积也很容易用GPU并行计算
6.1. 从全连接层到卷积
6.11不变性
-
平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。编程:v(i,j,a,b)=v(a,b)不随i,j像素位置变化而变化
-
局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。编程:a,b>dlt时a,b=0即大于dlt的值就不看了
(全连接层到卷积w->v,多了行和高) 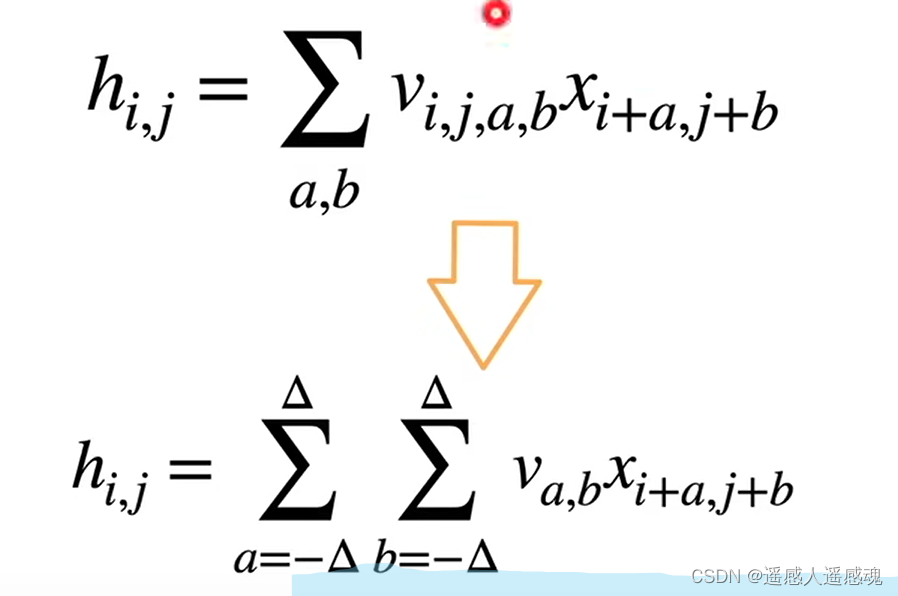
6.2图像卷积
卷积运算不填充,输出图像大小
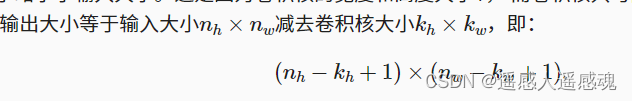
6.2.1卷积层
卷积层对输入和卷积核权重进行互相关(卷积)运算,并在添加标量偏置之后产生输出。卷积层中的两个被训练的参数是卷积核权重和标量偏置。
class Conv2D(nn.Module): def __init__(self, kernel_size): super().__init__() self.weight = nn.Parameter(torch.rand(kernel_size))#卷积核大小 self.bias = nn.Parameter(torch.zeros(1)) def forward(self, x): return corr2d(x, self.weight) + self.bias#前向传播调用corr2d函数执行互相关运算#卷积块一般包含卷积层,激活函数(卷积运算后的结果通过激活函数,可实现非线性化),池化层
6.2.2学习卷积核
lr = 3e-2 # 学习率 for i in range(10): Y_hat = conv2d(X) l = (Y_hat - Y) ** 2#输出层和输入层平方误差 conv2d.zero_grad() l.sum().backward() # 迭代卷积核 conv2d.weight.data[:] -= lr * conv2d.weight.grad#计算梯度 if (i + 1) % 2 == 0: print(f'epoch {i+1}, loss {l.sum():.3f}')可以自动计算卷积核参数
6.23特征映射和感受野
卷积层有时被称为特征映射(feature map),因为它可以被视为一个输入映射到下一层的空间维度的转换器。
感受野: 给定2×2卷积核,阴影输出元素值19的感受野是输入阴影部分的四个元素。 假设之前输出为Y,其大小为2×2,现在我们在其后附加一个卷积层,该卷积层以Y为输入,输出单个元素z。 在这种情况下,Y上的z的感受野包括Y的所有四个元素,而输入的感受野包括最初所有九个输入元素。 因此,当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络。#感受野是随着卷积层数增加而不断变大的,因为包含相关计算的像素范围扩大
6.3填充和步幅
填充后输出情况

在许多情况下,我们需要设置ph=kh−1和pw=kw−1,使输入和输出具有相同的高度和宽度。
卷积核通常选为奇数,可以底部和顶部填充相同数量的行,左右两侧填充相同数量的列。填充完以后进行卷积则原图(i,j)就对应卷积图的(i,j)
步幅,上图
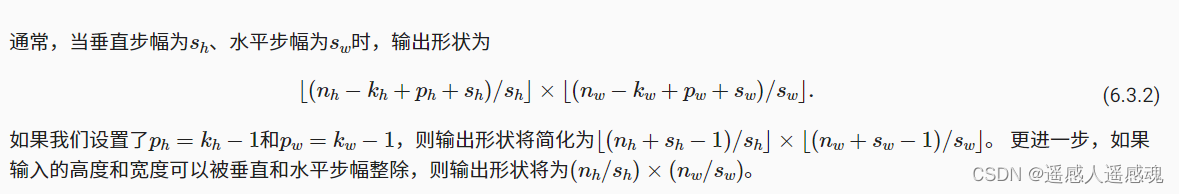
6.4多输入输出通道
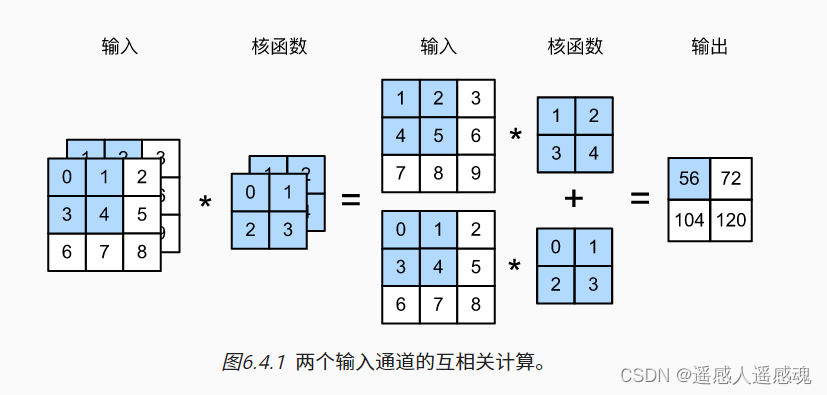
6.4.1多输入通道
及ci>1,RGB格式图像ci=3,
6.4.2多输出通道
随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作是对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
6.4.3 1*1矩阵
1×1卷积层通常用于调整网络层的通道数量和控制模型复杂性。
6.5汇聚层(池化层)
汇聚(pooling)层,它具有双重目的:降低卷积层对位置的敏感性,同时降低对空间降采样表示的敏感性。
在处理多通道输入数据时,汇聚层在每个输入通道上单独运算,而不是像卷积层一样在通道上对输入进行汇总。 这意味着汇聚层的输出通道数与输入通道数相同。
6.6卷积神经网络
6.6.1LeNet
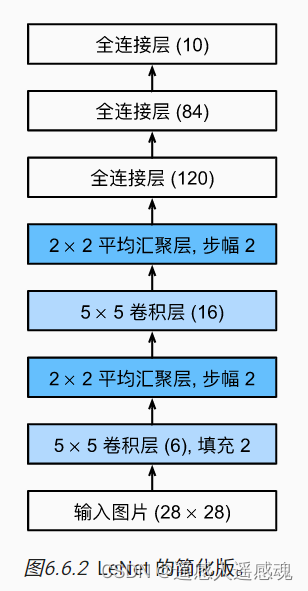
可修改这些提高性能
-
调整卷积窗口大小。
-
调整输出通道的数量。
-
调整激活函数(如ReLU)。
-
调整卷积层的数量。
-
调整全连接层的数量。
-
调整学习率和其他训练细节(例如,初始化和轮数)
编程:1.with用法















 1666
1666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









