






目录
1. 通信系统
通信的本质就是一个【编码+传输+解码】的过程。典型的通信系统具有六大要素:发送者(信息源)、信道、接收者、信息、上下文、编解码。这六大要素关系如下所示:

其中 表示发送者发出的原始信息,
表示将
编码后的信息,接收者则要用特定的解码方式将
还原成
。上面这个通信系统表示的过程本质上就是自然语言处理的过程。
那如何才能成功解码呢?将 解码成
的过程,其实就是寻找能让这个条件概率
达到最大值的
。用数学公式表达这个意思如下所示:
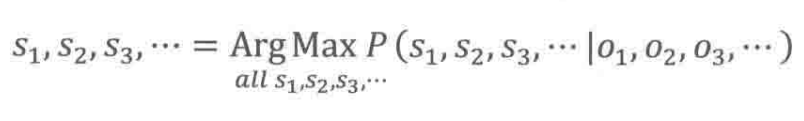
我们利用贝叶斯公式将这个条件概率展开,得:
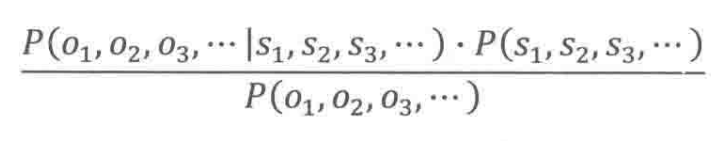
其中, 表示接收端收到
的概率,这在真实场景中是一个可以被忽略的常数项(因为一旦需要启动解码
的工作,就证明这个编码信息已经存在了,完全消除不确定性了)。
表示
是一段合乎情理的有意义的话的概率。
因为 是一个常数,因此后续我们只要考虑分子的大小就行:
![]()
那如何估计上面的概率值呢?这个时候,就得请出隐马尔可夫模型(Hidden Markov Model)了。
2. 各种“马尔可夫”们
首先声明下,“隐马尔可夫模型”并非是19世纪俄罗斯数学家马尔可夫(Andrey Markov)提出的,而是由美国数学家鲍姆(LeonardE.Baum)等人在20世纪六七十年代提出的。之所以被称为“隐马尔可夫模型”,是因为这个模型是基于马尔可夫假设提出的。
2.1 马尔可夫假设
马尔可夫假设,听起来感觉高大上,但其实它描述了一个非常直观的概念。想象一下,我们要预测明天的天气“是晴还是雨”。马尔可夫假设就是说,明天的天气只与今天的天气有关,而与前天及以前的天气无关。
用更专业的语言来说,马尔可夫假设认为在给定时间段内,一个系统的未来状态只取决于它的当前状态,而与它过去的状态无关。这就像是在一个迷宫中,你只需要知道你现在在哪里,就可以推测出下一步应该往哪里走,而不需要关心你之前是怎么走到这里的。可以用下面的数学公式来表示马尔可夫假设:
![]()
即当前的状态 的出现概率只与前一个状态
直接相关,而与更早的状态无关。
2.2 马尔可夫链
马尔可夫链,简单来说,就是一系列遵循马尔可夫假设的随机事件或状态。这些事件或状态按照时间顺序排列,形成一个链条。在这个链条中,每个事件或状态的发生概率只取决于前一个事件或状态。作者举了如下一个简单的马尔可夫链:

其中 分别表示4种不同的状态,每条带有箭头的有向线段表示一种状态转变,线段上的数字表示转移概率。比如状态
后面有两条转化路径,一条是转化到状态
,概率为0.4;另一条是转化到状态
,概率为0.6。
2.3 隐马尔可夫模型
有些情况下,上面的状态 并不能直接观察到,能看到的则是与这些状态息息相关的信号
。为了简化问题,统计学家们提出了“独立输出假设”,指在每个时刻
,模型会输出一个符号
,而且
跟
相关且仅跟
相关。如下图所示,作者展示了一个简单的隐马尔可夫模型:
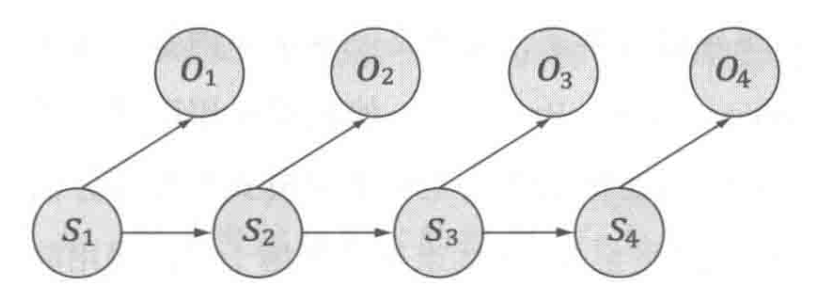
简而言之,可以将【隐马尔可夫模型】看做是【马尔可夫假设】+【独立输出假设】结合的产物。
2.3.1 将隐马尔可夫模型应用于解码问题
请注意,上图中表示的隐马尔可夫模型,本质上能够表达一种映射关系(即原文 与其编码后的
的映射关系),正因为这个特性,隐马尔可夫模型可被用于通信的解码问题,即我们可以计算出信息源发出某个特定的消息序列
产生出特定的符号序列
的概率,其数学公式的表达形式如下:

其中:
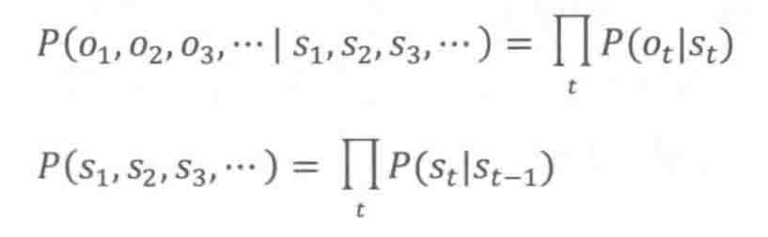
大家是不是觉得眼熟?是的,上面的公式正是通信系统的解码过程中的目标函数,目的就是找到使 值最大时对应的原文句子
。隐马尔可夫模型给我们提供了一个简单易行的估计
值的方法,但至于如何能快速找到最大的
值,就得利用维特比算法(Viterbi Algorithm)了,这里面的细节我们会在后面的读书笔记中介绍。
2.3.2 如何训练隐马尔可夫模型
作者提出,围绕隐马尔可夫模型有三个基本问题:
1)如何计算给定模型下特定输出序列 的概率?
2)如何找到给定模型和特定输出序列下最可能的状态序列 ?
3)如何利用大量观测数据来估计隐马尔可夫模型的参数?
问题一最简单,这通常通过前向算法(Forward Algorithm)或后向算法(Backward Algorithm)来计算,就类似于初中求解概率值的问题。
问题二就用前面的提到的维特比算法进行求解,这个后续章节会介绍。
问题三就涉及到如何训练隐马尔可夫模型的问题了。通常,隐马尔可夫模型的参数主要有两个:
1)转移概率:从前一个状态 转移到下一个状态
的概率,即
。
2)生成概率:每个状态 产生输出符号
的概率,即
。
现在参数明确了,接下来的问题就是如何去估计这两个参数。
2.3.2.1 有监督的训练
将 和
用贝叶斯公式展开,得:
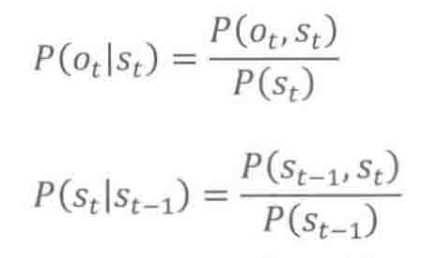
如果我们有足够多的人工标注数据,就能数出状态 出现的次数
,再统计出状态
输出符号
的次数
,最后相除,即可估算出上面参数之一的生成概率
的值:
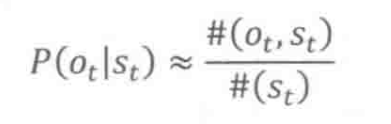
至于转移概率 的估算,对前面几章读书笔记还有印象的同学应该能反应过来,这个其实表示的就是统计语言模型。因此,基于训练语料库,可以用下面的公式进行估计:
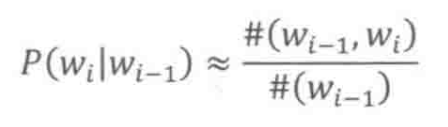
尽管有监督的训练方法因其直接性而易于理解,但其核心挑战在于高质量的人工标注数据的稀缺性。并非所有现实问题都能轻松找到相应的人工标注数据。为了应对这一挑战,科学家们提出了无监督的训练方法,旨在无需人工标注的情况下从数据中学习模式。
2.3.2.2 无监督的训练
隐马尔可夫模型最常用的无监督训练算法当属鲍姆-韦尔奇算法(Baum-WelchAlgorithm),它通过迭代方法估计模型参数,使得观测序列 的概率最大化。该算法是一种期望最大化(Expectation-Maximization, EM)算法的实现。它的基本思想是通过迭代来估计模型参数,每次迭代都包括一个E步(Expectation Step)和一个M步(Maximization Step)。
1)初始化:首先,随机设定模型的初始参数,包括状态转移概率、符号生成概率等,得到初始化模型 。
2)E步骤:接着,初始化模型 ,找到这个模型产生观测序列
的所有可能的隐藏状态路径
以及这些路径的概率。这些可能的路径,实际上记录了每个隐藏状态经历了多少次,到达了哪些其他的隐藏状态,对应输出了哪些符号,因此可以将它们看做是“标注的训练数据”。
3)M步骤:然后,根据E步骤中得到的所谓“标注的训练数据”,模仿上一节监督训练里的方式,计算新的转移概率和生成概率,进而得到新模型 ,以使得模型生成观测序列的总概率增加。可以数学证明:
![]()
4)重复EM步骤:不断重复E步骤和M步骤,直到模型参数收敛,即参数的变化非常小,此时认为模型已经学习到了数据的统计特性。
此外,在实际操作中,通常会设置阈值来判断参数是否已足够接近最优解,或者设定最大迭代次数以防止无限循环。鲍姆-韦尔奇算法的本质是通过反复迭代,逐渐优化模型参数,最终找到能够较好解释观测数据的模型参数。















 2780
2780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









