









编译原理之词法分析
一、词法分析
1.1、主要任务
从左向右逐行扫描源程序的字符,识别出各个单词,并且确定单词的类型,将识别出的单词转换成统一的机内表示(词法单元形式)。
1.2、单词的类型
| 单词类型 | 种别 | 种别码 |
|---|---|---|
| 关键字 | program,if,else,then… | 一词一码 |
| 标识符 | 变量名,数组名,记录名,过程名… | 多词一码 |
| 常量 | 整型,浮点型,字符型,布尔型… | 一型一码 |
| 运算符 | 算数运算符,关系运算符,逻辑运算符 | 一词一码或一型一码 |
| 界限符 | ; () = {}等 | 一词一码 |
1.3、词法分析后的结果
进行词法分析完后会得到token序列,格式为:
<种别码,属性值>
例如,词法分析完后出现一个100,这是一个常量,表示为:<CONST,100>
二、词法分析器
先了解一下编译器的结构,如下图所示:
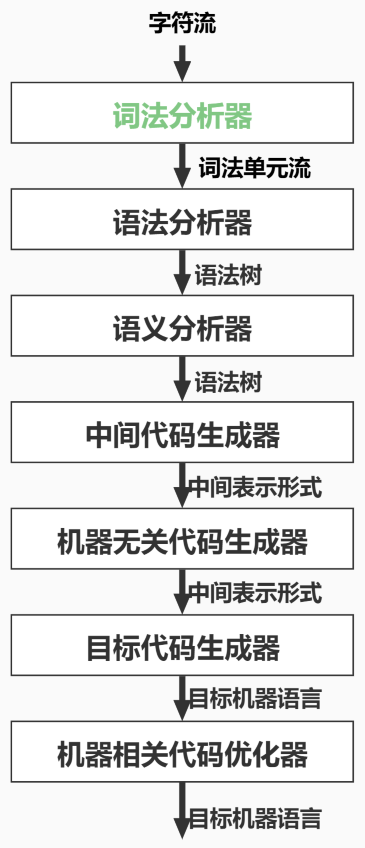
在编译器的结构中,最开始的部分就是词法分析器(上图绿色部分),字符流通过词法分析器处理之后,得到语法单元流。
1.1、Flex介绍
Flex是一个生成词法分析器的工具,它可以利用正则表达式来生成匹配相应字符串的C语言代码,其语法格式基本同Lex相同。
FLEX的输入文件称为LEX源文件,它内含正规表达式和对相应模式处理的C语言代码。LEX源文件的扩展名习惯上用.l表示。FLEX通过对源文件的扫描自动生成相应的词法分析函数int yylex(),并将之输出到名规定为lex.yy.c的文件中。使用时,可改名为lexyy.c。FLEX的输入是文件或输入设备,这些输入中的信息以正则表达式和C代码的形式组成,这些形式被称为规则。当可执行文件被执行时,其分析输入中可能存在的符合规则的内容,当找到任何一个正则表达式相匹配内容时,相应的C代码将被执行。FLEX的输入文件由3段组成,用一行中只有%%来分隔。
FLEX输入文件格式:
定义(definition)
%%
规则(rules)
%%
用户代码(code)
1.2、流程
①、创建.l文件
安装好vim软件,用来创建文件,当然也可以用其他的软件。
sudo apt install vim
大概需要等待几分钟,完成后直接cd到桌面或者你需要的文件路径下,创建文件我以code1.l为例,文件名和后缀根据自己实际需求进行修改。
vim code1.l
创建完成后需要对这个vim文件进行操作,需要先了解一些vim的命令操作。
可参考如下博客:https://blog.csdn.net/jisuanji198509/article/details/86690617
我这里列举一些最常用的。
模式切换
vim有命令模式和插入模式。
通过Esc键进行两种模式的切换
写入字符
i 进入插入模式,即可输入字符
o代表在下一行的开头开始插入
保存文件与退出
先输入 : ,然后:
输入 w 回车,保存,意思是 write
输入 q 回车,退出,意思是 quit
输入 q!不保存退出
输入 wq保存退出
创建好code1.l文件后会进入如下界面:
输入:wq后就可创建了,方法很多,也可以直接在桌面点击新建文件,重命名改后缀即可,也可用其工具。
同理创建一个main.c文件
②、下载安装flex
执行以下命令
sudo apt-get install flex
③、代码编写
安装完成后就可以进行代码编写了,在code1.l文件下编写如下程序(例子):
%{
#include <stdlib.h>
#include <stdio.h>
#define NUM 201612345
int num_chars = 0;
int num_ids=0;
int num_lines=1;
%}
delim [ ]
letter [A-Za-z]
digit [0-9]
number {digit}+
id {letter}+
%%
\n {num_lines++;printf("\n");}
{number} {int r=atoi(yytext);if(r==NUM) printf("夏天的鼻涕怪 ");
else printf("%s ",yytext);
num_ids++;
}
{delim} {printf(" ");}
{id} {printf("%s ",yytext);num_chars+=yyleng;num_ids++;}
%%
main()
{
yylex();
printf("\n# of ids = %d ,# of chars = %d ,# of lines = %d ",num_ids , num_chars,num_lines);
}
在main.c文件下编写下列代码
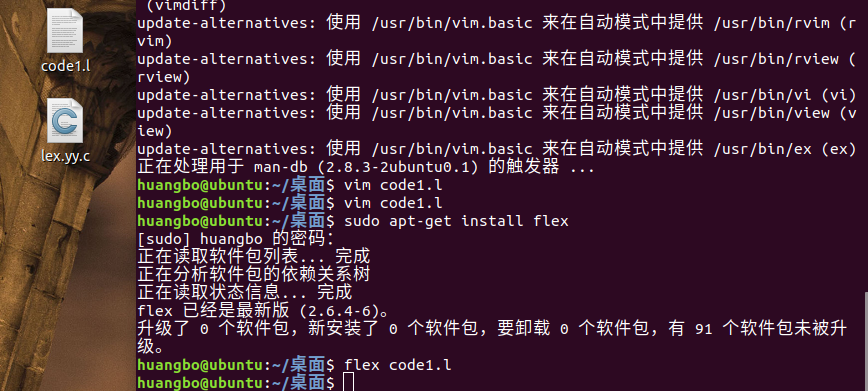
④、编译code1.l文件
输入:
flex code1.l
就可在code1.l同目录下产生lex.yy.c文件了
⑤、编译.c文件
输入:
gcc lex.yy.c
会生成一个a.out文件
⑥、进行词法分析
输入:
./a.out <test.txt> output.txt
test.txt为需要执行的文件,最终结果会保存在output.txt中。
1.3、代码编写
①、代码结构
Flex 源代码文件包括三个部分,由“%%”隔开,如下所示:
{definitions}
%%
{rules}
%%
{user subroutines}
②、定义部分
此部分是给某些后面可能经常用到的正则表达式取一个别名,从而简化词法规则的书写。
格式:
name definition //name 是名字,definition 是任意的正则表达式
例,下面的这段代码定义了两个名字:digit 和 letter,前者代表 0 到 9 中的任意一个数字字符,后者则代表任意一个小写字母、大写字母或下划线:
digit [0-9]
letter [_a-zA-Z]
③、规则部分
由正则表达式和相应的响应函数组成,格式为:
pattern {action} //pattern 为正则表达式,其书写规则与前面的定义部分的正则表达式相同。action则为将要进行的具体操作,可以用一段 C 代码表示。
Flex 将按照这部分给出的内容依次尝试每一个规则,尽可能匹配最长的输入串。如果有些内容不匹配任何规则,Flex默认只将其拷贝到标准输出,想要修改这个默认行为的话只需要在所有规则的最后加上一条“.”(即匹配任何输入)规则,然后在其对应的 action 部分书写想要的行为。
④、用户自定义代码部分
此部分代码会被原封不动地拷贝到 lex.yy.c 中,以方便用户自定义所需要执行的函数。如果用户想要对这部分所用到的变量、函数或者头文件进行声明,可以在定义部分之前使用“%{”和“%}”符号将要声明的内容添加进去。被“%{”和“%}”所包围的内容也会一并拷贝到 lex.yy.c 的最前面。
1.4、正则表达式书写
①、符号 “.” 匹配除换行符 “\n” 之外的任何一个字符。
②、符号 “[” 和 “]” 共同匹配一个字符类,方括号之内只要有一个字符被匹配上了,那么方括号括起来的整个表达式都被匹配上了。例如,[0123456789]表示 0~9 中任意一个数字字符,[abcABC]表示 a、b、c 三个字母的小写或者大写。方括号中还可以使用连字符“-”表示一个范围,例如[0123456789]也可以直接写作[0-9],而所有小写字母字符也可直接写成[a-z] 。如果方括号中的第一个字符是“^”,则表示对这个字符类取补,即方括号之内如果没有任何一个字符被匹配上,那么被方括号括起来的整个表达式就认为被匹配上了。例如[ ^_0-9a-zA-Z]表示所有的非字母、数字以及下划线的字符。
③、符号“^”用在方括号之外则会匹配一行的开头,符号“$”用于匹配一行的结尾,符号“<< EOF >>”用于匹配文件的结尾。
④、符号“{”和“}”。如果花括号之内包含了一个或者两个数字,则代表花括号之前的那个表达式需要出现的次数。例如,A{5}会匹配 AAAAA,A{1,3}则会匹配 A、AA 或者 AAA。如果花括号之内是一个在 Flex 源代码的定义部分定义过的名字,则表示那个名字对应的正则表达式。例如,在定义部分如果定义了 letter 为[a-zA-Z],则{letter}{1,3}表示连续的一至三个英文字母。
⑤、符号 “*” 为 Kleene 闭包操作,匹配零个或者多个表达式。例如{letter}表示零个或者多个英文字母。
⑥、符号 “+” 为正闭包操作,匹配一个或者多个表达式。例如{letter}+表示一个或者多个英文字母
⑦、符号“?”匹配零个或者一个表达式。例如表达式-?[0-9]+表示前面带一个可选的负号的数字串。无论是、+还是?,它们都只对其最邻近的那个字符生效。例如 abc+表示 ab后面跟一个或多个 c,而不表示一个或者多个 abc。如果你要匹配后者,则需要使用小括号“(” 和“)” 将这几个字符括起来:(abc)+。
⑧、 符号“|”为选择操作,匹配其之前或之后的任一表达式。例如,faith | hope | charity 表示这三个串中的任何一个。
⑨、符号“\”用于表示各种转义字符,与 C 语言字符串里“\”的用法类似。例如,“\n”表示换行,“\t”表示制表符,“*” 表示星号,“\”
⑩、符号 “"”(英文引号)将逐字匹配被引起来的内容(即无视各种特殊符号及转义字符)。例如,表达式"…"就表示三个点而不表示三个除换行符以外的任意字符。
shi符号 “/” 会查看输入字符的上下文,例如,x/y 识别 x 仅当在输入文件中 x 之后紧跟着 y,0/1 可以匹配输入串 01 中的 0 但不匹配输入串 02 中的 0。
⑪、符号 “/” 会查看输入字符的上下文,例如,x/y 识别 x 仅当在输入文件中 x 之后紧跟着 y,0/1 可以匹配输入串 01 中的 0 但不匹配输入串 02 中的 0。
⑫、任何不属于上面介绍过的有特殊含义的字符在正则表达式中都仅匹配该字符本身。
1.5、Flex高级特性
①、yylineno
作用:记录行号
每行结束后自动+1
默认状态下开放给用户使用。如果我们想要读取 yylineno 的值,则需要在 Flex 源代码的定义部分加入语句“%option yylineno”。需要说明的是,虽然 yylineno 会自动增加,但当我们在词法分析过程中调用 yyrestart()函数读取另一个输入文件时它却不会重新被初始化,因此我们需要自行添加初始化语句yylineno = 1。
②、input库函数
Flex 库函数 input()可以从当前的输入文件中读入一个字符,这有助于不借助正则表达式来实现某些功能。
如下代码:发现双斜线“//”后,将从当前字符开始一直到行尾的所有字符全部丢弃掉:
"//" {
char c = input();
while (c != '\n') c = input();
}
三、词法分析器实战
1、完整代码
不分三段进行详细讲解了,代码蛮容易理解的,直接看代码。
%{
#include<string.h>
int charCounter=0;
int column =0,line=1;
char right[100][100];
char error[100][100];
int biaor=0;
int biaoe=0;
int flag=0;
void addLine(int);
void addColumn(int);
void clearColumn();
void addChar(int);
void ShowError();
%}
digit [0-9]
int [0-9][0-9]*
float {digit}*(\.{digit}+)?(e|E[+\-]?{digit}+)?
semi [;]
comma [,]
assignop [=]
reloop [>]|[<]|[>][=]|[<][=]|[=][=]|[!][=]
plus [+]
minus [-]
siar [*]
div [/]
and [&][&]
or [|][|]
dot [.]
not [!]
leixing "int"|"float"
return "return"
if "if"
else "else"
while "while"
reserveword "break"|"main"|"continue"|"for"|"void"
operator "#"
lp \(
rp \)
lb \[
rb \]
lc \{
rc \}
STRUCT "struct"
T [ \t]+
id [a-zA-Z_][a-zA-Z_0-9]*
%%
{digit}
{
sprintf(right[biaor],"digit: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{int} {
sprintf(right[biaor],"INT: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{float} {
sprintf(right[biaor],"FLOAT: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{semi} {
sprintf(right[biaor],"SEMI: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{comma} {
sprintf(right[biaor],"COMMA: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{assignop} {
sprintf(right[biaor],"ASSIGNOP: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{reloop} {
sprintf(right[biaor],"RELOP: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{plus} {
sprintf(right[biaor],"PLUS: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{minus} {
sprintf(right[biaor],"MINUS: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{siar} {
sprintf(right[biaor],"STAR: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{div} {
sprintf(right[biaor],"DIV: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{and} {
sprintf(right[biaor],"AND: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{or} {
sprintf(right[biaor],"OR: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{dot} {
sprintf(right[biaor],"DOT: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{not} {
sprintf(right[biaor],"NOT: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{leixing} {
sprintf(right[biaor],"TYPE: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{lp} {
sprintf(right[biaor],"LP: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{rp} {
sprintf(right[biaor],"RP: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{lb} {
sprintf(right[biaor],"LB: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{rb} {
sprintf(right[biaor],"RB: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{lc} {
sprintf(right[biaor],"LC: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{rc} {
sprintf(right[biaor],"RC: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{STRUCT} {
sprintf(right[biaor],"STRUCT: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{id} {
sprintf(right[biaor],"ID: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{return} {
sprintf(right[biaor],"RETURN: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{if} {
sprintf(right[biaor],"IF: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{else} {
sprintf(right[biaor],"ELSE: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{while} {
sprintf(right[biaor],"WHIL: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{reserveword} {
sprintf(right[biaor],"reserveword: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{leixing} {
sprintf(right[biaor],"TYPE: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{operator} {
sprintf(right[biaor],"operator: %s\n",yytext);
biaor++;
addChar(yyleng);
}
{T} {
}
. {
addChar(1);
addLine(1);
ShowError();
}
\n {
addChar(1);
addLine(1);
clearColumn();
}
%%
int main(void)
{
yylex();
if(flag==0)
{
for(int i=0; i<biaor;i++){
printf("%s",right[i]);
}
}
else{
for(int i=0; i<biaoe;i++){
printf("%s",error[i]);
}
}
return 0;
}
int yywrap() {
return 1;
}
void addLine(int cnt) {
line += cnt;
}
void addColumn(int cnt) {
column += cnt;
}
void clearColumn() {
column = 0;
}
void addChar(int leng) {
charCounter += leng;
}
void ShowError()
{
flag=1;
sprintf(error[biaoe],"Error type A at Line %d: Mysterious characters \'%s\'\n",yylineno, yytext);
biaoe++;
}
四、思考与总结
完成这份代码花了蛮长时间,主要是卡在了一个点卡了几个小时,不能使用win10上的创建的cpp文件拖拽到vm上进行测试,否则会出莫名奇妙的错误。会出现乱码那些,最终找到的解决办法是把代码定义为一个txt文件,直接编辑,不会产生相应错误。具体原因不太清楚,也可能是我按照了vim编辑器的原因,只要用cpp文件就会出现问题,txt文件没有问题。收获还是蛮多的,学到了很多新的东西。

















 5180
5180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











