







感知器是一种简单的线性分类器
对于一组数据X=(
x1,x2,...,xn
),其中每一个
xi
代表了一个属性值,那么这个属性值所代表的属性的重要程度可能是不同的,我们用一组权重的向量代表每个属性的重要程度,
W=(x1,w2,...,wn)
这样对每一组数据我们可以计算出一个得分score,他可能代表了一些具体含义,比如某客户的信用额度。那么当score与某一临界值作比较时,分类器就产生了。具体来说:
为什么要乘以1呢
这里是为了化简,如果把1看作 x0 把threshold看作 w0 那么
由此可以看出感知器就是一条直线, wT 就是法向量,那么这种直线有成千上万条,我们如何确定一条最好的直线,即确定一个向量 w
PLA—–感知机学习算法
这里我们假设最开始的时候手里有随便一条曲线
wn
,这条曲线应用到已知的训练数据集中,那么会有错误的划分
(xn,yn)
这时候我们去纠正我们的曲线
wn+1=wn+ynxn

具体算法:
- for t = 1,2,…
- 找到 错误划分节点
(xn(t),yn(t))
- 即 sign(wtxn(t))≠yn
- 修正
wt
- wt+1=wt+xnyn
- 找到 错误划分节点
(xn(t),yn(t))
- 直到没有错误节点 返回 wt
那么对于线性可分的数据,为什么感知机可以找到一条线呢:
假设 wf 是最好的直线
7.18日补充:这里还是大致说一下证明吧
我们要证明说存在
wf
是最好的分割线首先就要证明说每一次迭代
wt+1
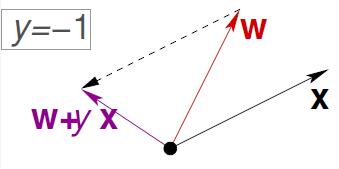
都在向着最优直线靠拢,那这个怎么证明,用向量的内积,内积越大越接近。
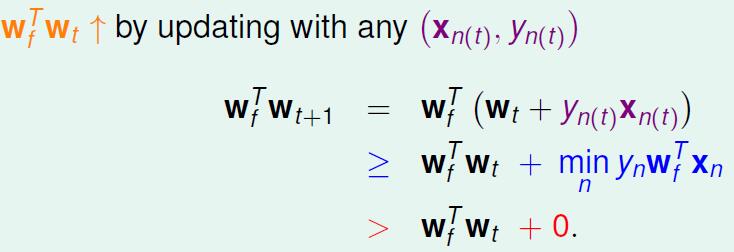
有了这个还不够,因为有可能是数值变大导致的内积变大呢,那怎么办?我们想用一个标准的步长说明 wt 每次迭代的步长变化都不大。也就是每次长度没有太大的变化不会影响到内积。

最后那个式子是怎么证明出来的呢。
因为
wt
从0开始迭代的,所以有
组合起来有了下面的式子。
具体证明就不写了,可以证明出
也就是任意直线 wt 不断向最优直线靠拢,T为迭代次数。
但是我们可能不确定数据集是否是线性可分的,这时候我们希望求得一条直线,这条直线犯的错误最少
口袋算法-pocket algorithm
这是一种贪婪算法。
我们每求得一个w就去看这个w犯的错误的个数,并且与之前的w作比较,如果更好则替换这个w

那么如果一个数据集确实是线性可分的,然而我们采用了pocket算法,那么事实上他的速度要比PLA慢,因为pocket不仅仅要存w,而且比较的时候要遍历所有数据集来找出划分错误的点进行比较。















 153
153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









