







我们已经知道了对于线性可分的数据的分类问题,但是有些问题可能不是线性的分类器可以解决的。
Nonlinear Transform
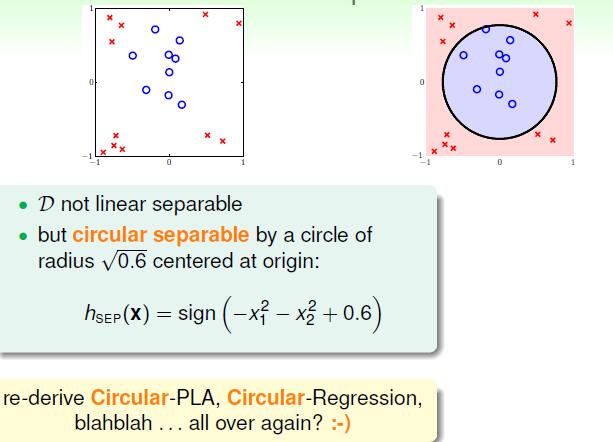
如上图所示的数据,一条直线无法分割的数据我们可以用圆来分割。圆圈外的点是叉叉而圆圈内部的点是圈圈。那么我们来看,我们可以对上述的分类函数做一个转换,使得其变成线性函数。
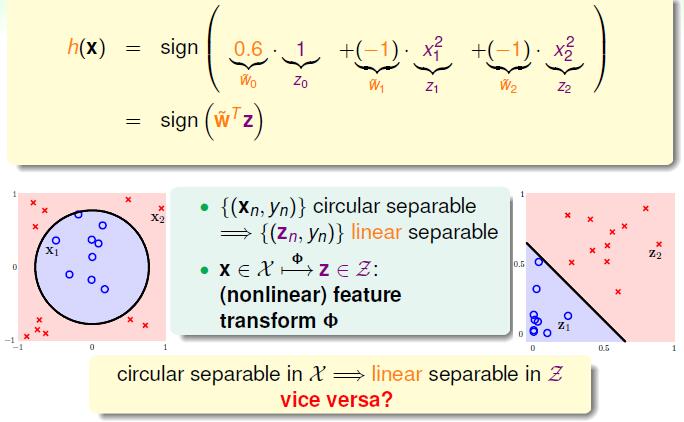
我们将 x21 映射为 z1 将 x22 映射为 z2 , 1映射为 z0 ,这样实际上有是一个线性分割,只不过不在是在原始的资料上了,而是对原始资料做了一个 ϕ(x) 的映射,将原始的点投影到新的空间,在这个空间上各个点是线性可分的。
那么反过来呢,对于之前的映射 ϕ(x) ,映射后的空间我们姑且用 Z 来表示,在这个空间中的每条直线在原始空间 X 中代表了什么呢。我们来看下图。

在对应的 ϕ(x) 映射下, Z 平面下的不同直线(这里对应了 w^=(w0^,w1^,w2^) 的不同取值)代表了原空间中不同的线,可能是圆,可能是椭圆,双曲线等等。但是 Z 平面中的所有直线对应不了所有原始平面 X 下的各种二次曲线,比如说圆,只能对应原始平面中圆心在原点的圆。这是由映射函数 ϕ(x) 决定的,如果我们想对应原始平面 X 中的所有二次曲线,那么我们需要原始平面维度下的所有二次项。

如上图所示,这时候对应的 ϕ(x)=(1,x1,x2,x21,x1x2,x22) ,在这个六维空间上的每一个超平面对应了原始空间的各种二次曲线。也就是对于线性不可分的数据,将它映射到高维空间就可能变成线性可分。
那么通过线性转换我们就可以把一些不可分数据映射到高维空间,然后在选用一种线性分类的算法得到分类器。 g(x)=sign(w^Tϕ(x)) 具体步骤如下:
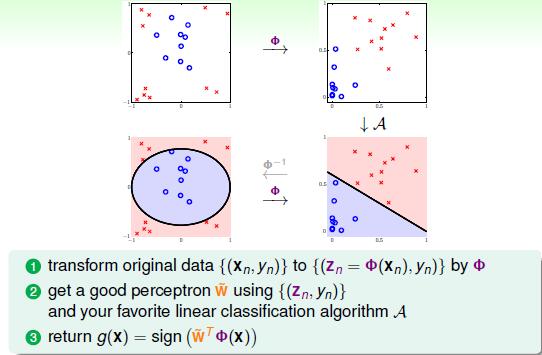
那么我们这里是用二次曲线去做的,现实中我们怎么知道应该用几次曲线呢,那么我们怎么知道我们需要哪些项呢,因为对于三次曲线我们的映射就会变成 ϕ(x)=(1,x31,x21x2,...,x32) ,而且这种映射有什么问题呢,难道曲线次数越多越好么?
Price of Nonlinear Transform
我们先看一下转换前后维度的变化。

对于之前d维的向量,转换之后变成了 (Q+dd) 维,这样才能代表原来空间的所有Q次曲线(面),这就影响了存储或者运行效率。
当然最大的问题在于VC维变大了,VC dimension 是近似等于 特征数量也就是维度的,按照之前讲的VC dimension的理论,VC维越大, Ein,Eout 差距就越大。
Structured Hypothesis Sets

我们讲对于d维数据不同次数多项式映射是互相包含的,为什么这么说,比如
ϕ2(x)
当所有二次项系数都是0剩下的就是
ϕ1(x)
,那么就有了下图的关系。
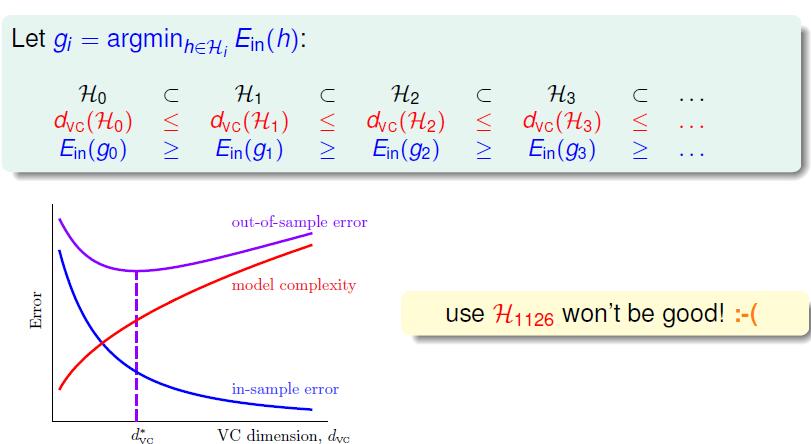
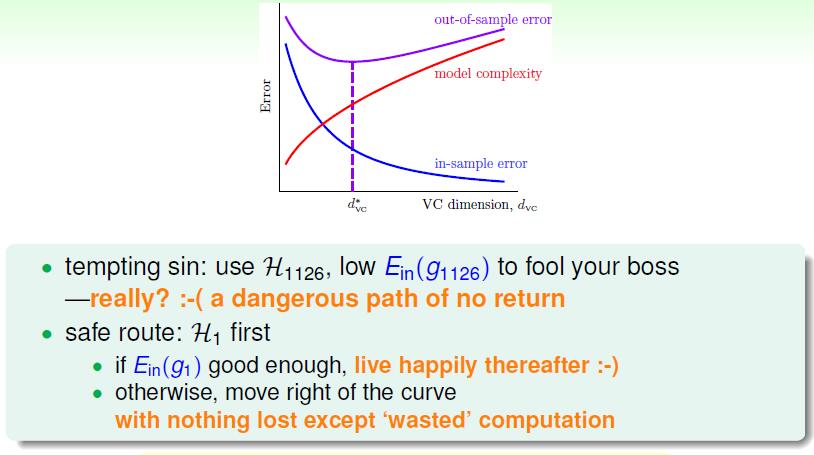
dvc 越来越大,代表了模型复杂度越来越复杂,可选空间越来越多,我们越有可能选择出一个较好的hypothesis, 那么 Ein 会越来越小,但是与 Eout 的差距会越来越大。
所以说,映射的维度越高可能会导致一个较小的 Ein ,但是可能 Eout 会很高。那么安全的做法是什么呢,我们应该从较小的 dvc 做起如果可以得到一个较小的 Ein 那么很好,我们就可以选择这个分类器g, 如果不行,我们在增加维度,也就是在往稍稍的高维映射去做。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









