






关于机器学习必须要了解的几个要点
(A Few Useful Things to Know about Machine Learning)
本文翻译自华盛顿大学Pedro Domingos的文章《A Few Useful Things to Know about Machine Learning》,非专业翻译,因兴趣而做,如有误解请指正!原文链接:
http://homes.cs.washington.edu/~pedrod/papers/cacm12.pdf
以下是正文:
摘要
机器学习算法可以通过推广示例来完成很多重要的任务。这种灵活、高效的特点是手工编写程序来完成任务所不具备的。数据越多,机器学习就能够解决更加复杂的问题,所以它被广泛应用于计算机科学和众多领域。然而,想要成功开发出实用的机器学习算法,需要很多书本中没有提到的技巧。本文列出了机器学习行家从经验中总结的十二个要点。这些要点包括了一些需要避免的陷阱,需要关注的问题以及一些常规问题的解答。
简介
机器学习算法自动地从数据中学习,过去的几十年里,它被广泛应用于各个领域。其中就包括了网络信息检索,垃圾邮件分类,推荐系统,广告投放,信用评分,诈骗检测,股票交易,药物设计,等等。最近McKinsey Global Institute声明,机器学习将会带来下一波科技进步的浪潮。如今,已经有不少介绍机器学习算法的优秀书籍,可是这些书中并没有介绍那些对于成功实现机器学习应用非常重要的“通俗知识”。结果是,人们在开发机器学习相关项目的时候,花了太多不必要的时间,却没有得到最理想的效果。这就是本文的出发点。
机器学习算法可以有很多种分类,但是为了方便介绍我的观点,本文中我主要关注在广泛应用的一类机器学习算法:分类算法(classification)。然而,我在文中讨论的各种观点同样适用于其他类型的机器学习算法。所谓分类算法指的是在一个系统中,系统的输入是一个连续或者离散的向量,而输出是单个的离散值,这个离散值就是分类结果(class)。例如,在垃圾邮件分类系统中,垃圾邮件可以被分为两类:垃圾邮件和非垃圾邮件。该系统的输入是一个布尔类型的向量 x=(x1,...,xj,...,xd) ,其中,如果邮件中出现了字典中第j个词,那么 xj=1 ,否则 xj=0 。给学习器输入训练数据, (xi,yi) ,其中 xi=(xi,1,...,xi,d) 是输入的特征, yi 是对应的输出。学习器可以通过训练,得到一个分类器。要测试学习器好不好,就要把测试数据输入到分类器,然后计算分类误差(有多少比例的垃圾邮件被正确地分类)。
学习=表示+评价+优化
假设你想通过机器学习算法在你的项目中得到比较好的效果,首要的问题是,有太多的机器学习算法,到底应该选择哪一个?毫不夸张地讲,如今已经有上千种算法,每年还会有上百种新的算法出现。防止自己迷失在算法中的关键,是要记住,任何算法都只是以下三个部件的组合:
- 表示
- 一个分类器一定能够表示成计算机可以看懂的语言。选择学习器的表示方法,就等同于选择了一系列分类器,从中我们可以通过学习得到最终的分类器。这个分类器的集合就叫学习器的假设空间。如果一个分类器不在假设空间中,那么它就不可能通过学习得到。这与另一个问题–输入特征的选择有关,我们将在之后的部分讨论。
- 评价
- 评价函数是用来从一堆分类器中挑选出好的分类器。通常为了方便优化,我们实际使用的评价函数与真实的评价函数有一定的差别,关于这一点,在下一部分会讲到。
- 优化
- 最终,我们需要有一个方法,从众多的分类器中找出那个评分最高的分类器。优化算法是学习器执行效率的关键,而且还可以用来判断分类器是否存在不止一个最优解。初学者可以先使用成熟的优化算法,熟悉流程之后,再根据需要进行定制。
表1展示的是上述三个部件的例子。比如,k近邻通过寻找k个最接近的训练样本,对样本中的主要成分进行分类。 基于超平面的方法对于每一类进行特征线性组合,然后根据这些组合进行分类。决策树在其中的每一个节点上测试一种特征,树枝代表了不同的特征值范围,决策树的决策结果就在树叶上。算法1展示了决策树的训练流程,其中用到了信息增益和贪婪搜索。信息增益
InforGain(xj,y)
也就是特征
xj
和类y的互信息。函数
MakeNode(x,c0,c1)
的返回值是一个用于检测特征x的节点,对于x=0的特征,其子节点对应的训练集是
TS0
,对于x=1的特征,其子节点对应的训练集是
TS1
。
当然了,并不是说表1中任意三个部件的组合都能构成有价值的算法。例如,用离散变量表示的模型,就要用组合优化算法;而用连续变量表示的模型,则需要用连续优化算法。不过,许多学习器既有连续的也有连续的,也许不远的未来,表1中的任何一种组合方式组合出来的学习方法,都是有意义的。
大部分的教材,都主要是在介绍表示方式,这很容易让人忽略其他两个重要的部件(评价和优化),然而这三个部件是同等重要的。如何选择每个部件,没有诀窍。不过下一部分我们将介绍一些选择的原则。并且,从接下来的内容中,我们可以知道,在完成机器学习任务的过程中,我们的某些选择远比算法本身重要。
泛化
机器学习最基本的价值所在,就是我们可以将其用于训练样本之外的其他数据,也就是泛化。这是因为,不论我们拥有多少数据,都很难将所有可能出现的数据用于训练(比如说,在垃圾邮件中,可能出现的单词一共有10000个,那么垃圾邮件中出现单词的组合,就有
210000
种可能)。在训练集上获得好的结果很容易(最直接的方法就是让学习算法记住所有的训练样本)。机器学习初学者常犯的错误就是,以为在训练集上得到好结果就万事大吉了。可是一旦将这些分类器用于其他数据,你会发现分类结果与随机猜测的结果差别不大。所以如果你请别人帮你设计分类器,请记得将你的数据集中的一部分作为训练集,用来测试他给你的分类器是否好用。反过来讲,如果有人请你来设计分类器,请在一开始就从数据集中划分出来一部分留作测试数据,在你利用其余的数据训练并且得到了分类器之后,再把这些数据拿出来使用。
用一些隐蔽的方法,你可以把测试数据混合进你的分类器中,比如说在调参的过程中使用测试集的数据进行拟合(机器学习中有很多类似的小把戏,这种事情时有发生,所以对于这些细节我们必须更加注意)。当然了,采用保留一部分数据作为测试集的方法,会导致用于训练的数据减少。我们可以采用“交叉验证”的方式进行弥补。“交叉验证”的过程如下:首先随机将整个数据集分为十份,每一次训练,将其中的九份用于训练,剩下一份用于测试。这样进行十次,把十次的结果取平均,就可以知道你用的学习算法好不好了。
在早期,机器学习过程中将训练集和测试集分开并没有被广泛接受,这是因为当时的学习器能够拟合出的超平面维度有限,这样很难完全将样本区分开,这就导致了在训练集和测试集上的结果差不多,当时的人们也就认为没有这么做的必要了。但是随着机器学习研究的深入,学习器越来越复杂、易变(比如决策树),甚至是线性分类器在使用了大量特征之后也有了这样的特性,此时训练集与测试集分离也就成了必须。
如果将泛化作为目标,那么就会导致一个很有意思的结果。这不像其他的优化问题,因为我们不知道我们的优化函数是什么。在训练过程中,我们不得不假定训练误差就是测试误差,然而这存在潜在的问题。如何解决这个问题,我们将在接下来的部分中讲到。让我们积极地考虑这个问题,优化函数仅仅是我们对于真实情况的假定,实际情况是,我们并不一定要彻底地按照优化函数来。事实上,有时候通过贪婪搜索得到的局部最优解甚至会比全局最优解更好。
数据
将泛化作为目标,带来了另一个问题:不论用了多少数据,都是不够的。这样想想吧:我们想要对100个变量进行拟合,使用了一百万个数据样本,那么我们至少有
2100−26
的数据没有包含在样本中。这种情况下,我们怎么才能知道剩下的这些数据是属于哪一类呢?由于没有多余的信息,我们也就只能瞎猜了。200年前哲学家David Hume首先观察到了这个问题,然而这么多年后的今天,仍有人在使用机器学习算法时因为忽略了这个问题而犯错。为了能够泛化,任何学习器都会或多或少地包含一些训练数据并没有告诉它的信息。Wolpert在他著名的“没有免费的午餐”的理论中,以另一种方式说出了这个道理:没有任何一个这样的学习器,其针对所有可能的优化函数学出的分类器,都可以瞎猜的方式更好。
(译者:在这个问题上表现好的算法,用在另一个问题上就可能表现很差,任何算法在统计意义上都差不多,所以只有合适某个特定问题的算法,没有所谓的最好算法能够在各种问题上都比其他算法好。关于此理论可以查看资料:
https://en.wikipedia.org/wiki/No_free_lunch_theorem
http://blog.sciencenet.cn/blog-286797-446192.html
)
这似乎是个令人沮丧的答案:既然如此,那我们搞机器学习还有什么意义呢?瞎猜就好了嘛!幸运的是,在现实世界里,我们遇到的问题所需的优化函数并不是均匀分布的。事实上,很多通用的假设,比如平滑性、相似的数据更有可能属于同一个类、数据之间有限的相关性、有限的复杂度等等,都能带来很好的效果。这也就是机器学习被广泛使用的原因。归纳演绎是一种获得知识的手段:它可以让你通过少量的信息获得大量的额外信息。归纳法比演绎法更加强大,它只需要很少的知识就可以得到有用的结果,不过,为了能够得到正确的结果,还是需要给它足够的信息的。不管我们用任何一种手段来获得额外的知识,我们给它的信息越多,我们能够从中获得的知识也就越多。
从上面的论述我们可以得到一个结论:在机器学习中,选择表示方法的标准在于,利用这种表示方法,能够传达出什么样的信息。比如,如果我们知道在我们的问题中样本有哪些共同点,此时采用从实例出发的方法就是一个很好的选择。如果我们知道数据的概率相关性,选择图模型就很合适。如果我们知道在何种前提下,样本会归为哪一类,就可以选择“If… Then… ”的判别方法。从这个角度上讲,最有用的学习器并不是生拉硬拽一些假设进来,而是其用到的各种假设可以准确地表述出其中的道理,各种假设各有特点各不相同,而且可以有机地结合在一起。
在机器学习中需要额外的知识,这并不奇怪。因为机器学习不是魔法,它不可能在什么都不知道的情况下就给你想要的结果。它的作用是,从有限的知识中扩充出更多的有用知识。工程总是有这样的特点,就像编程需要大量的努力才能从底层建立起整个系统。而机器学习就好像种地,很多工作都是自然地发生的。种地的时候,我们要把种子种在地里,然后施肥。机器学习则是利用已有的知识,再结合上数据,得到更多的知识。
过拟合
如果我们手中拥有的知识和数据并不足以让我们得到理想的分类器怎么办?这种情况下,我们很可能得到的是一个幻想中的分类器,与真实情况相去甚远,它把数据中的巧合当真了。这就是过拟合,也是困扰机器学习的一件事情。如果你的学习器可以在训练集中得到100%的准确率,但是只能在测试集中得到50%的准确率,而在理想情况下它不论在训练集还是测试集中都应该获得75%的准确率,此时就发生了过拟合。
在机器学习领域,每个人都听说过过拟合,但是它会以多种形式出现而且有时候并没有那么容易被发现。一种理解过拟合的方式是把泛化误差分解为偏置(bias)和方差(variance)。偏置是指学习器总是反同样的错误,而方差是指学习器做出的决断与输入信号无关,是随机的。图1就展示了这个问题。
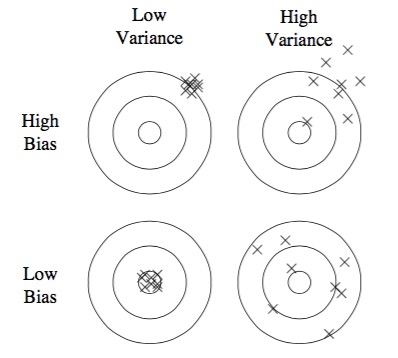
如果线性分类器无法完全制造分割两类的超平面,就会出现偏置。决策树模型就不会有这样的问题,因为它理论上来说可以产生任意超平面的划分,但是从另一个角度来看,它通常有较大的方差。由同样的现象引出的问题,在不同的数据集上训练,决策树模型会得到完全不同的结果,而理论上来说,它们应该是一样的。基于相似的道理,在选择优化算法时,束搜索比贪婪搜索有更低的偏置,但有更高的方差,因为它用到了更多的假设。因此,与我们的直觉相反,真正优秀的分类器不一定要比差的分类器表现更好。
正如图2展示的,即使真实情况是:分类器是一系列的判决组成的,在训练样本不到1000个的时候,朴素贝叶斯分类器比判决分类器精确度更高。
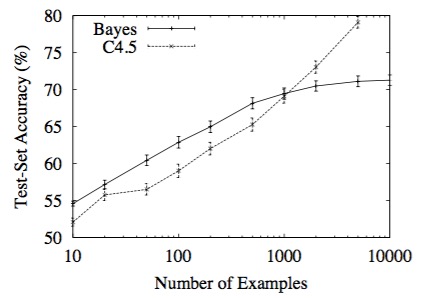
在机器学习中,这样的情况时有发生,较强的错误假设会比较弱的正确假设表现更好,这是因为后者需要更多的数据来避免过拟合。交叉验证有助于减弱过拟合,比如可以将决策树设定到合适的大小。然而这并不是万能的,因为如果我们人为的设定了过多的参数,模型本身就一定会发生过拟合。
除了交叉验证之外,还有其他各种方式来预防过拟合。其中最常用的方法是在评价函数中加入正则项。这样可以对于过于复杂的模型进行处罚,因而系统更容易产生结构简单的模型。另外一种方式是在加入新的结构之前通过卡方验证来检验统计显著性,以此来判断加入此结构是否有助于提升效果。当数据不足时,这些方法非常有用。然而,如果有谁生成某种方法可以完全“解决”过拟合问题,你应当持怀疑态度。因为很容易就从过拟合变成欠拟合。想要同时做到避免过拟合和欠拟合需要设计出完美的分类器,然而根据“天下没有免费的午餐”原理,在没有足够知识的前提下,没有任何一个分类器能够在各种情况下都表现最好。
一个关于过拟合的误解是,认为它是噪声造成的,比如说训练样本的标签标错了。这确实会让过拟合加重,因为这会让学习器产生出变换反复的决策面,以满足这些样本的标定。但是在没有噪声的情况下, 也可能发生严重的过拟合。例如,假设我们有一个布尔型分类器需要把训练集中的正样本找出来(换句话说,分类器以析取范式的方式,将训练集中样本的特征结合起来)。这个分类器将训练集中的样本正确分类,而将测试集中的正样本全部错误分类,无论训练集中有没有噪声。
多重假设检验与过拟合十分相关。标准的统计检验一次只能检验一种假设,而学习器可以同时检验百万种。结果是,看上去很重要的假设也许实际上并没有多重要。例如,如果有一家信托基金公司连续十年业绩领先于业内,你会觉得它很厉害,但是如果仔细一想,如果每年任何一家公司都会有50%的概率领先,那么它就有可能很幸运地连续十年领先。这个问题可以通过加入一系列的假设,做显著性测试来判断,但同样会带来欠拟合的问题。一种更加有效的方式是控制错误接受的比例,也称为错误发现率。
高维度
除了过拟合,机器学习中最大的问题就要数维度的诅咒了。这种表述在1961年由Bellman提出,主要是想说明如下事实:很多在低维度处理时非常有效的算法,一旦输入换成高维度输入,算法就无法得到理想的结果。不过在机器学习领域,维度的诅咒这个词还有更多的含义。正确地泛化随着维度的升高指数级地越变越难,这是因为固定数目的训练集只包含了整个空间中很小的一部分。甚至一个中等维度的训练集(比如100维),有很大数量的训练样本(比如10亿个样本),其只覆盖了全空间中样本数量的大概
1/1018
。这也是机器学习很重要但是也很难得原因。
更为要命的是,机器学习依赖的基于相似度的推理,也随着维度升高而变差。我们来看一个以Hamming距离作为度量的最近邻聚类模型,并且假设其特征只有
x1,x2
。如果样本中不包含无关的特征,这本身是一个很简单的问题。但是如果样本特征还有
x3,...,x100
,其噪声足以扰乱
x1,x2
的信息,这就会导致最近邻聚类模型做随机的分类。
更加令人烦恼的是,即使说这100个特征是相关的,最近邻模型依然会遇到问题。这是因为,高纬度下所有的样本看上去都差不多。 比如说样本在规则网格中分布,我们可以考虑一个测试样本
xt
。如果这个规则网络是d维的,那么
xt
的2-d最近邻离它的距离都是相等的,但是随着维度增加,越来越多的样本成为
xt
的最近邻,使得最近邻的选择(也就是这个类)变得随机。
==========================
未完待续。。。
==========================
本Markdown编辑器使用StackEdit修改而来,用它写博客,将会带来全新的体验哦:
- Markdown和扩展Markdown简洁的语法
- 代码块高亮
- 图片链接和图片上传
- LaTex数学公式
- UML序列图和流程图
- 离线写博客
- 导入导出Markdown文件
- 丰富的快捷键
快捷键
- 加粗
Ctrl + B - 斜体
Ctrl + I - 引用
Ctrl + Q - 插入链接
Ctrl + L - 插入代码
Ctrl + K - 插入图片
Ctrl + G - 提升标题
Ctrl + H - 有序列表
Ctrl + O - 无序列表
Ctrl + U - 横线
Ctrl + R - 撤销
Ctrl + Z - 重做
Ctrl + Y
Markdown及扩展
Markdown 是一种轻量级标记语言,它允许人们使用易读易写的纯文本格式编写文档,然后转换成格式丰富的HTML页面。 —— [ 维基百科 ]
使用简单的符号标识不同的标题,将某些文字标记为粗体或者斜体,创建一个链接等,详细语法参考帮助?。
本编辑器支持 Markdown Extra , 扩展了很多好用的功能。具体请参考Github.
表格
Markdown Extra 表格语法:
| 项目 | 价格 |
|---|---|
| Computer | $1600 |
| Phone | $12 |
| Pipe | $1 |
可以使用冒号来定义对齐方式:
| 项目 | 价格 | 数量 |
|---|---|---|
| Computer | 1600 元 | 5 |
| Phone | 12 元 | 12 |
| Pipe | 1 元 | 234 |
定义列表
-
Markdown Extra 定义列表语法:
项目1
项目2
- 定义 A
- 定义 B 项目3
- 定义 C
-
定义 D
定义D内容
代码块
代码块语法遵循标准markdown代码,例如:
@requires_authorization
def somefunc(param1='', param2=0):
'''A docstring'''
if param1 > param2: # interesting
print 'Greater'
return (param2 - param1 + 1) or None
class SomeClass:
pass
>>> message = '''interpreter
... prompt'''脚注
生成一个脚注1.
目录
用 [TOC]来生成目录:
数学公式
使用MathJax渲染LaTex 数学公式,详见math.stackexchange.com.
- 行内公式,数学公式为: Γ(n)=(n−1)!∀n∈N 。
- 块级公式:
更多LaTex语法请参考 这儿.
UML 图:
可以渲染序列图:
或者流程图:
离线写博客
即使用户在没有网络的情况下,也可以通过本编辑器离线写博客(直接在曾经使用过的浏览器中输入write.blog.csdn.net/mdeditor即可。Markdown编辑器使用浏览器离线存储将内容保存在本地。
用户写博客的过程中,内容实时保存在浏览器缓存中,在用户关闭浏览器或者其它异常情况下,内容不会丢失。用户再次打开浏览器时,会显示上次用户正在编辑的没有发表的内容。
博客发表后,本地缓存将被删除。
用户可以选择 把正在写的博客保存到服务器草稿箱,即使换浏览器或者清除缓存,内容也不会丢失。
注意:虽然浏览器存储大部分时候都比较可靠,但为了您的数据安全,在联网后,请务必及时发表或者保存到服务器草稿箱。
浏览器兼容
- 目前,本编辑器对Chrome浏览器支持最为完整。建议大家使用较新版本的Chrome。
- IE9以下不支持
- IE9,10,11存在以下问题
- 不支持离线功能
- IE9不支持文件导入导出
- IE10不支持拖拽文件导入
- 这里是 脚注 的 内容. ↩















 2442
2442

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









