







1. PPO 的背景与动机
PPO 是 OpenAI 在 2017 年提出的一种基于策略梯度(Policy Gradient)的强化学习算法,PPO的提出是为了解决传统策略梯度方法的高方差、低样本效率和更新步长敏感问题,同时避免TRPO的计算复杂性。通过Clipping目标函数和重要性采样,PPO实现了:
- 稳定训练:限制策略更新幅度,避免策略崩溃。
- 高效数据利用:复用旧策略数据,支持多轮更新。
- 易用性:仅需一阶优化,适合大规模分布式训练。
PPO 通过引入截断目标函数(Clipped Objective)和重要性采样(Importance Sampling),在保证训练稳定性的同时简化了实现。
| 维度 | 策略梯度(PG) | PPO |
|---|---|---|
| 稳定性 | 高方差,易崩溃 | 通过Clipping限制更新幅度,稳定性强 |
| 样本效率 | 低(每步需新数据) | 高(复用数据,支持多轮更新) |
| 实现复杂度 | 简单,但需精细调参 | 简单,无需二阶优化,仅需一阶梯度 |
| 适用场景 | 简单任务 | 复杂、高维状态/动作空间任务(如机器人控制) |
2. 核心思想
PPO 的核心是限制策略更新的幅度,避免因单次更新过大导致策略性能崩溃。具体通过以下两个关键设计实现:
(1) 重要性采样(Importance Sampling)
- 目标:利用旧策略(old policy)收集的数据来更新新策略(new policy),提高样本效率。
- 概率比(Probability Ratio):
r t ( θ ) = π θ ( a t ∣ s t ) π θ old ( a t ∣ s t ) r_t(\theta) = \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} rt(θ)=πθold(at∣st)πθ(at∣st)
其中, π θ \pi_\theta πθ 是新策略, π θ old \pi_{\theta_{\text{old}}} πθold 是旧策略。
(2) 截断目标函数(Clipped Objective)
-
原始目标函数:策略梯度方法的目标是最大化期望回报:
L PG ( θ ) = E t [ r t ( θ ) A t ] L^{\text{PG}}(\theta) = \mathbb{E}_t \left[ r_t(\theta) A_t \right] LPG(θ)=Et[rt(θ)At]
其中 A t A_t At 是优势函数(Advantage Function),衡量动作的好坏。 -
PPO 的改进:通过截断概率比 r t ( θ ) r_t(\theta) rt(θ),限制策略更新的幅度:
L CLIP ( θ ) = E t [ min ( r t ( θ ) A t , clip ( r t ( θ ) , 1 − ϵ , 1 + ϵ ) A t ) ] L^{\text{CLIP}}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right] LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)] -
ϵ \epsilon ϵ 是截断超参数(通常取 0.1 或 0.2)。
-
当 A t > 0 A_t > 0 At>0(动作优于平均),限制 r t ( θ ) ≤ 1 + ϵ r_t(\theta) \leq 1+\epsilon rt(θ)≤1+ϵ;
-
当 A t < 0 A_t < 0 At<0(动作劣于平均),限制 r t ( θ ) ≥ 1 − ϵ r_t(\theta) \geq 1-\epsilon rt(θ)≥1−ϵ。
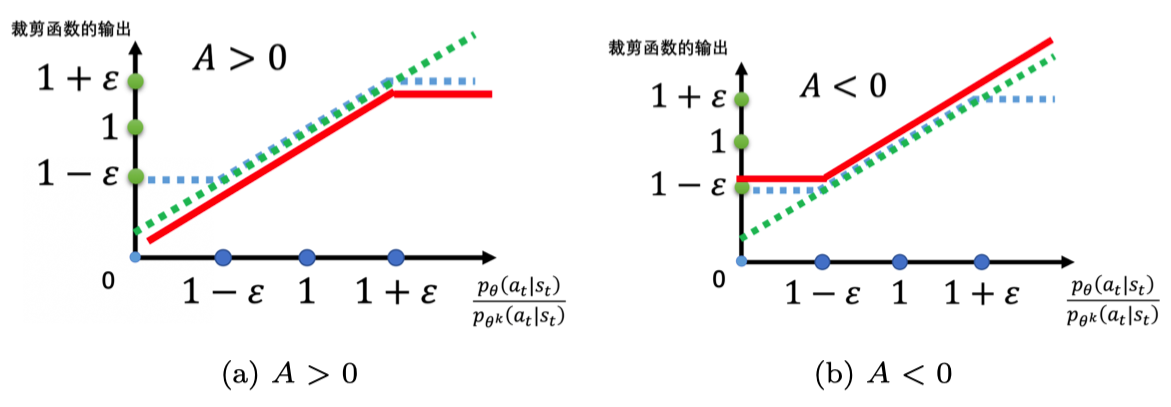
这种设计确保策略更新幅度不会过大,同时保留优化方向。
3. PPO 的算法流程
PPO 的实现通常分为以下步骤:
步骤 1:数据收集
- 使用当前策略 π θ old \pi_{\theta_{\text{old}}} πθold 与环境交互,收集一批轨迹(trajectories)。
步骤 2:计算优势函数
- 通过广义优势估计(Generalized Advantage Estimation, GAE)计算每个时间步的优势值
A
t
A_t
At:
A t = ∑ k = 0 T − t ( γ λ ) k δ t + k A_t = \sum_{k=0}^{T-t} (\gamma \lambda)^k \delta_{t+k} At=k=0∑T−t(γλ)kδt+k
其中 δ t = r t + γ V ( s t + 1 ) − V ( s t ) \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) δt=rt+γV(st+1)−V(st), γ \gamma γ 是折扣因子, λ \lambda λ 是 GAE 的超参数。
步骤 3:优化目标函数
- 通过随机梯度上升(SGD)最大化截断目标函数 L CLIP ( θ ) L^{\text{CLIP}}(\theta) LCLIP(θ),通常进行多轮(如 3-10 轮)小批量更新。
步骤 4:更新策略
- 用优化后的参数 θ \theta θ 更新旧策略: θ old ← θ \theta_{\text{old}} \leftarrow \theta θold←θ。
4. PPO 的变体
PPO 有两种主要实现形式:
- PPO-Clip:直接使用截断目标函数(最常用)。
- PPO-Adaptive KL Penalty:通过自适应 KL 散度惩罚项限制策略更新,但效果不如 Clip 稳定。
5. PPO 的优点
- 实现简单:无需计算二阶导数,适合大规模分布式训练。
- 稳定性强:截断机制有效防止策略崩溃。
- 样本效率高:通过重要性采样复用旧策略数据。
- 适应性广:适用于连续和离散动作空间。
6. 数学推导(简化版)
假设我们希望最大化以下目标函数:
L
(
θ
)
=
E
t
[
π
θ
(
a
t
∣
s
t
)
π
θ
old
(
a
t
∣
s
t
)
A
t
]
L(\theta) = \mathbb{E}_t \left[ \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} A_t \right]
L(θ)=Et[πθold(at∣st)πθ(at∣st)At]
为了限制更新幅度,引入截断函数:
L
CLIP
(
θ
)
=
E
t
[
min
(
r
t
(
θ
)
A
t
,
clip
(
r
t
(
θ
)
,
1
−
ϵ
,
1
+
ϵ
)
A
t
)
]
L^{\text{CLIP}}(\theta) = \mathbb{E}_t \left[ \min\left( r_t(\theta) A_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) A_t \right) \right]
LCLIP(θ)=Et[min(rt(θ)At,clip(rt(θ),1−ϵ,1+ϵ)At)]
通过梯度上升更新参数 (\theta),确保策略更新在可控范围内。
7. 代码实现要点
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
from collections import deque
import gym
# 定义策略网络
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim, hidden_dim=64):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, action_dim)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return F.softmax(self.fc3(x), dim=-1)
def act(self, state):
state = torch.FloatTensor(state).unsqueeze(0)
probs = self.forward(state)
dist = torch.distributions.Categorical(probs)
action = dist.sample()
return action.item(), dist.log_prob(action)
# 定义价值网络
class ValueNetwork(nn.Module):
def __init__(self, state_dim, hidden_dim=64):
super(ValueNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.fc3 = nn.Linear(hidden_dim, 1)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
return self.fc3(x)
# 计算 GAE 优势函数
def compute_gae(rewards, masks, values, gamma=0.99, tau=0.95):
"""
计算 GAE 优势函数。
参数:
rewards (list): 每个时间步的奖励,形状为 [T]。
masks (list): 每个时间步的终止标志(1 表示未终止,0 表示终止),形状为 [T]。
values (list): 每个时间步的状态值函数估计,形状为 [T + 1]。
gamma (float): 折扣因子,默认为 0.99。
tau (float): GAE 参数,控制偏差和方差的权衡,默认为 0.95。
返回:
advantages (torch.Tensor): 每个时间步的优势函数,形状为 [T]。
"""
# 初始化优势函数和 GAE
advantages = torch.zeros_like(rewards) # 形状为 [T]
gae = 0 # 初始化 GAE
# 从后向前计算 GAE
for t in reversed(range(len(rewards))):
# 计算 TD 误差
delta = rewards[t] + gamma * values[t + 1] * masks[t] - values[t]
# 更新 GAE
gae = delta + gamma * tau * masks[t] * gae
# 存储当前时间步的优势函数
advantages[t] = gae
return advantages
# PPO2 算法
class PPO2:
def __init__(self, state_dim, action_dim, hidden_dim=64, lr=3e-4, gamma=0.99, epsilon=0.2, epochs=10, batch_size=64):
self.policy = PolicyNetwork(state_dim, action_dim, hidden_dim)
self.value = ValueNetwork(state_dim, hidden_dim)
self.optimizer = optim.Adam(list(self.policy.parameters()) + list(self.value.parameters()), lr=lr)
self.gamma = gamma
self.epsilon = epsilon
self.epochs = epochs
self.batch_size = batch_size
def update(self, states, actions, log_probs_old, returns, advantages):
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions)
log_probs_old = torch.FloatTensor(log_probs_old)
returns = torch.FloatTensor(returns)
advantages = torch.FloatTensor(advantages)
for _ in range(self.epochs):
for idx in range(0, len(states), self.batch_size):
# 获取当前 batch
batch_states = states[idx:idx + self.batch_size]
batch_actions = actions[idx:idx + self.batch_size]
batch_log_probs_old = log_probs_old[idx:idx + self.batch_size]
batch_returns = returns[idx:idx + self.batch_size]
batch_advantages = advantages[idx:idx + self.batch_size]
# 计算新策略的概率
probs = self.policy(batch_states)
dist = torch.distributions.Categorical(probs)
log_probs_new = dist.log_prob(batch_actions)
# 计算概率比
ratios = torch.exp(log_probs_new - batch_log_probs_old)
# 裁剪目标函数
surr1 = ratios * batch_advantages
surr2 = torch.clamp(ratios, 1 - self.epsilon, 1 + self.epsilon) * batch_advantages
policy_loss = -torch.min(surr1, surr2).mean()
# 计算价值函数损失
values = self.value(batch_states).squeeze()
value_loss = F.mse_loss(values, batch_returns)
# 更新参数
self.optimizer.zero_grad()
loss = policy_loss + value_loss
loss.backward()
self.optimizer.step()
# 训练 PPO2
def train_ppo2(env_name='CartPole-v1', hidden_dim=64, lr=3e-4, gamma=0.99, epsilon=0.2, epochs=10, batch_size=64, num_steps=2048, max_episodes=1000):
env = gym.make(env_name)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.n
ppo = PPO2(state_dim, action_dim, hidden_dim, lr, gamma, epsilon, epochs, batch_size)
for episode in range(max_episodes):
states, actions, log_probs, rewards, masks = [], [], [], [], []
state = env.reset()
done = False
# 收集数据
for _ in range(num_steps):
action, log_prob = ppo.policy.act(state)
next_state, reward, done, _ = env.step(action)
states.append(state)
actions.append(action)
log_probs.append(log_prob)
rewards.append(reward)
masks.append(1 - done)
state = next_state
if done:
state = env.reset()
# 计算回报和优势函数
values = ppo.value(torch.FloatTensor(states)).squeeze().detach().numpy()
returns = np.zeros_like(rewards)
advantages = compute_gae(rewards, masks, values, gamma)
# 更新模型
ppo.update(states, actions, log_probs, returns, advantages)
# 打印训练信息
if (episode + 1) % 10 == 0:
print(f"Episode: {episode + 1}, Reward: {np.sum(rewards)}")
# 运行训练
train_ppo2()
8. 应用场景
- 游戏 AI(如 Dota 2、星际争霸)
- 机器人控制
- 自然语言生成(对话策略优化)
总结
PPO 通过截断目标函数和重要性采样,在保证训练稳定性的同时简化了实现,成为目前最主流的强化学习算法之一。其核心思想是限制策略更新的幅度,避免因单次更新过大导致策略性能崩溃。



















 5633
5633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











