







Factor VAE模型详解
论文链接:https://arxiv.org/abs/1802.05983
FactorVAE是一种旨在提升潜在变量解耦能力的生成模型,通过显式地减少潜在变量间的依赖性来实现。以下从背景、原理、损失函数推导及与Beta-VAE的对比进行详细说明。
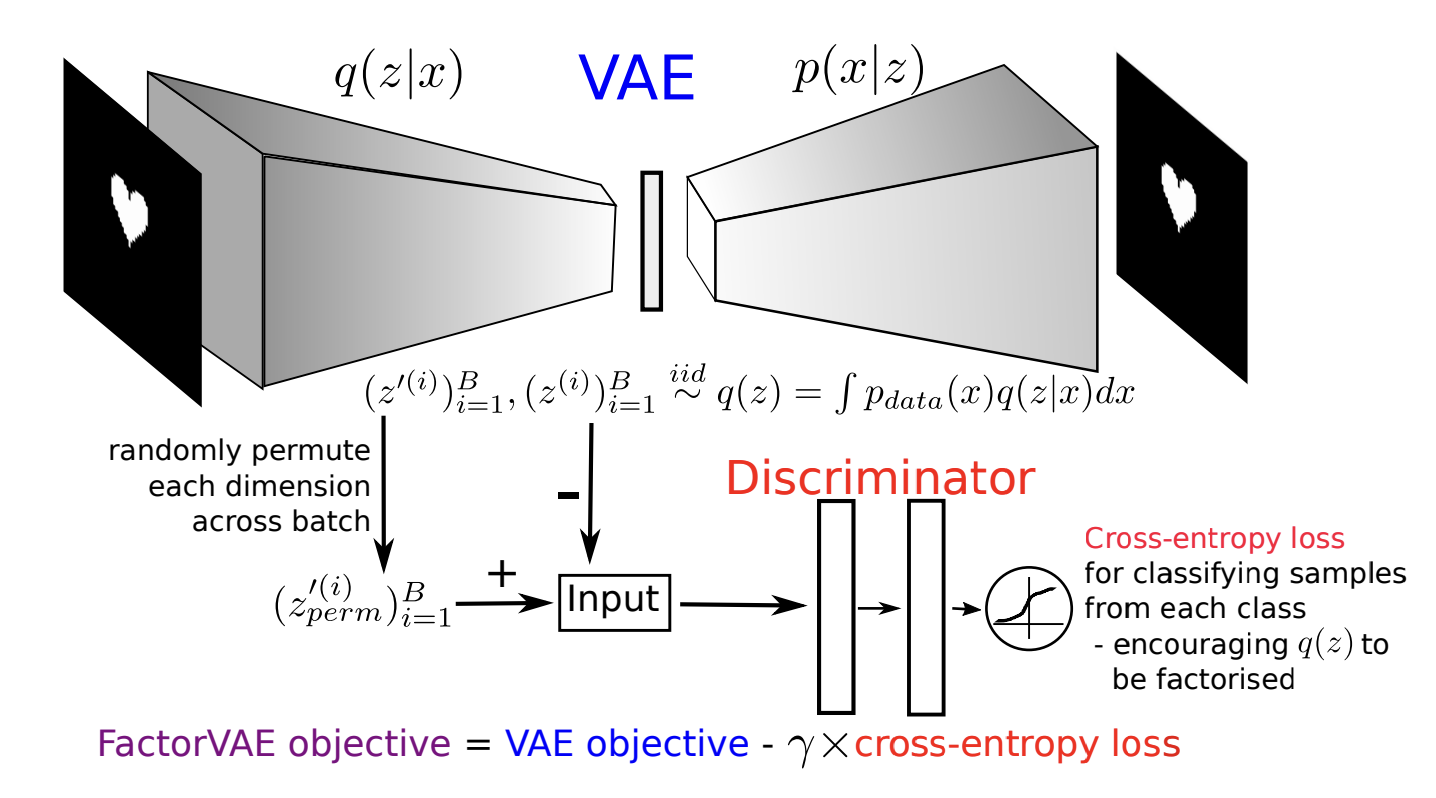
一、 FactorVAE模型背景
传统变分自编码器(VAE)通过最大化证据下界(ELBO)学习数据的潜在表示,但其潜在变量可能存在纠缠(entanglement),即单个变量控制多个特征。Beta-VAE 通过增大 KL 散度权重 β \beta β间接惩罚总相关性(TC)以实现解耦,但这种方式存在两个主要问题:
- 信息丢失:过大的
β
\beta
β不仅抑制 TC,还会压缩索引码互信息
I
q
(
z
;
x
)
I_q(z;x)
Iq(z;x),导致潜在变量丢失重要数据信息。
- 解耦效率低:Beta-VAE 隐式控制 TC,无法直接优化变量间的独立性,解耦效果受限。
FactorVAE 的改进: - FactorVAE 显式地惩罚总相关性(TC),在保持重构能力的同时,更高效地促进潜在变量独立,解决了 Beta-VAE 的信息丢失问题。
二、 FactorVAE原理
2.1. 总相关(TC)的定义
TC是多变量间依赖性的度量,定义为联合分布与边缘分布乘积的KL散度:
TC
(
q
(
z
)
)
=
K
L
(
q
(
z
)
∥
∏
i
q
(
z
i
)
)
\text{TC}(q(z)) = KL\left( q(z) \parallel \prod_{i} q(z_i) \right)
TC(q(z))=KL(q(z)∥i∏q(zi))
最小化TC可促使潜在变量相互独立。
2.2. KL散度的分解
VAE的KL散度项可分解为:
K
L
(
q
(
z
∣
x
)
∥
p
(
z
)
)
=
TC
(
q
(
z
)
)
⏟
变量间依赖
+
∑
i
K
L
(
q
(
z
i
)
∥
p
(
z
i
)
)
⏟
维度独立KL散度
+
I
q
(
z
;
x
)
⏟
索引码互信息
KL(q(z|x)\parallel p(z)) = \underbrace{\text{TC}(q(z))}_{\text{变量间依赖}} + \underbrace{\sum_i KL(q(z_i)\parallel p(z_i))}_{\text{维度独立KL散度}} + \underbrace{I_q(z;x)}_{索引码互信息}
KL(q(z∣x)∥p(z))=变量间依赖
TC(q(z))+维度独立KL散度
i∑KL(q(zi)∥p(zi))+索引码互信息
Iq(z;x)
FactorVAE显式惩罚TC项,而Beta-VAE整体缩放整个KL项。
三、 损失函数推导
FactorVAE的损失函数在ELBO基础上加入TC正则项:
L
FactorVAE
=
E
q
(
z
∣
x
)
[
log
p
(
x
∣
z
)
]
−
∑
i
K
L
(
q
(
z
i
∣
x
)
∥
p
(
z
i
)
)
−
γ
⋅
TC
(
q
(
z
)
)
\mathcal{L}_{\text{FactorVAE}} = \mathbb{E}_{q(z|x)}[\log p(x|z)] - \sum_i KL(q(z_i|x)\parallel p(z_i)) - \gamma \cdot \text{TC}(q(z))
LFactorVAE=Eq(z∣x)[logp(x∣z)]−i∑KL(q(zi∣x)∥p(zi))−γ⋅TC(q(z))
其中:
- 第一项为重构损失,保证生成质量。
- 第二项确保各潜在变量与先验分布(如标准正态)匹配。
- 第三项(γ > 0)惩罚变量间依赖性,γ控制解耦强度。
3.1. TC的估计
直接计算TC困难,FactorVAE通过密度比估计Density Ratio Estimation来近似估计:
引入判别器
D
(
z
)
D(z)
D(z)区分联合样本
z
∼
q
(
z
)
z\sim q(z)
z∼q(z)和独立样本
z
∼
Π
i
=
1
d
q
(
z
i
)
z\sim \Pi_{i=1}^dq(z_i)
z∼Πi=1dq(zi),通过对抗训练估计密度比,当判别器
D
(
z
)
D(z)
D(z)最优时,判别器的输出等于
q
(
z
)
Π
d
=
1
d
q
(
z
i
)
\frac{q(z)}{\Pi_{d=1}^dq(z_i)}
Πd=1dq(zi)q(z)
T
C
=
E
q
(
z
)
log
q
(
z
)
Π
d
=
1
d
q
(
z
i
)
=
E
q
(
z
)
log
D
(
z
)
\begin{aligned} TC&=\mathbb{E}_q(z)\log \frac{q(z)}{\Pi_{d=1}^dq(z_i)}\\ &=\mathbb{E}_{q(z)}\log D(z) \end{aligned}
TC=Eq(z)logΠd=1dq(zi)q(z)=Eq(z)logD(z)
- 采样策略:从联合分布 q ( z ) q(z) q(z)采样真实样本 z z z,并通过打乱各维度生成近似独立样本 z ~ ∼ ∏ i q ( z i ) \tilde{z} \sim \prod_i q(z_i) z~∼∏iq(zi)。
- 训练鉴别器
D
D
D:区分真实样本
z
z
z与打乱样本
z
~
\tilde{z}
z~,损失函数为:
L D = E z ∼ q ( z ) [ log D ( z ) ] + E z ~ ∼ ∏ q ( z i ) [ log ( 1 − D ( z ~ ) ) ] \mathcal{L}_D = \mathbb{E}_{z \sim q(z)}[\log D(z)] + \mathbb{E}_{\tilde{z} \sim \prod q(z_i)}[\log (1-D(\tilde{z}))] LD=Ez∼q(z)[logD(z)]+Ez~∼∏q(zi)[log(1−D(z~))] - 估计TC:利用鉴别器输出计算:
TC ≈ E z ∼ q ( z ) [ log D ( z ) 1 − D ( z ) ] \text{TC} \approx \mathbb{E}_{z \sim q(z)}\left[\log \frac{D(z)}{1-D(z)}\right] TC≈Ez∼q(z)[log1−D(z)D(z)]
四、 FactorVAE vs. Beta-VAE
4.1 区别
| 特性 | Beta-VAE | FactorVAE |
|---|---|---|
| 正则化目标 | 整体缩放KL散度( β ⋅ K L ( q ( z ∣ x ) ∣ ∣ p ( z ) ) ) \beta·KL(q(z|x)||p(z))) β⋅KL(q(z∣x)∣∣p(z))) | 显式惩罚TC项( γ ⋅ T C ( q ( z ) \gamma\cdot TC(q(z) γ⋅TC(q(z))) |
| 解耦控制 | 间接,隐式通过增大 β \beta β间接影响 TC,可能影响各变量与先验的匹配 | 显式优化TC作为独立正则项,直接针对变量间依赖,保留各变量独立性 |
| 重构质量 | 高 β \beta β值易导致重构模糊 | 更优平衡,解耦与重构质量兼顾 |
| 实现复杂度 | 简单,仅需调整 β \beta β | 复杂,需额外训练判别器估计 TC |
4.2 FactorVAE优势
- 解耦效果更强:显式优化TC,直接减少变量间依赖,在解耦指标(如MIG)上表现更优。
- 灵活调控: γ \gamma γ独立控制TC项,不影响各变量与先验的匹配(如Beta-VAE中 β \beta β增大会强制所有变量趋近先验)。
- 生成质量保留:避免过度约束KL散度,重构图像更清晰。
五、 总结
FactorVAE通过分解KL散度并显式惩罚总相关,在解耦表示学习中实现了更精细的控制。相比Beta-VAE,其优势在于直接针对变量间依赖性进行优化,避免了全局KL缩放带来的信息损失,从而在解耦能力和生成质量间达到更优平衡。
六、代码
import torch
import torch.nn as nn
import torch.nn.functional as F
# 超参数
latent_dim = 64 # 潜在空间维度
gamma = 10.0 # TC 正则项权重
alpha = 1.0 # KL 散度权重
# 编码器(同 Beta-VAE)
class Encoder(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(3, 32, 4, 2, 1), # 64x64 → 32x32
nn.ReLU(),
nn.Conv2d(32, 64, 4, 2, 1), # 32x32 → 16x16
nn.ReLU(),
nn.Conv2d(64, 128, 4, 2, 1),# 16x16 → 8x8
nn.ReLU(),
nn.Conv2d(128, 256, 4, 2, 1), # 8x8 → 4x4
nn.ReLU(),
nn.Flatten()
)
self.fc_mu = nn.Linear(256*4*4, latent_dim)
self.fc_logvar = nn.Linear(256*4*4, latent_dim)
def forward(self, x):
h = self.conv(x)
return self.fc_mu(h), self.fc_logvar(h)
# 解码器(同 Beta-VAE)
class Decoder(nn.Module):
def __init__(self):
super().__init__()
self.fc = nn.Linear(latent_dim, 256*4*4)
self.conv = nn.Sequential(
nn.Unflatten(1, (256, 4, 4)),
nn.ConvTranspose2d(256, 128, 4, 2, 1), # 4x4 → 8x8
nn.ReLU(),
nn.ConvTranspose2d(128, 64, 4, 2, 1), # 8x8 → 16x16
nn.ReLU(),
nn.ConvTranspose2d(64, 32, 4, 2, 1), # 16x16 → 32x32
nn.ReLU(),
nn.ConvTranspose2d(32, 3, 4, 2, 1), # 32x32 → 64x64
nn.Tanh()
)
def forward(self, z):
h = self.fc(z)
return self.conv(h)
# TC 判别器(估计密度比)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1)
)
def forward(self, z):
return self.model(z)
# FactorVAE 主模型
class FactorVAE(nn.Module):
def __init__(self):
super().__init__()
self.encoder = Encoder()
self.decoder = Decoder()
self.discriminator = Discriminator()
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
mu, logvar = self.encoder(x)
z = self.reparameterize(mu, logvar)
x_recon = self.decoder(z)
return x_recon, mu, logvar
def loss_function(self, x, x_recon, mu, logvar, z):
# 重构损失
recon_loss = F.mse_loss(x_recon, x, reduction='sum')
# KL 散度(各维度独立)
kl_loss = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
# 估计 TC(通过判别器)
log_qz = self.discriminator(z)
permuted_z = z[:, torch.randperm(z.size(1))] # 打乱维度,近似 q(z_i)
log_qz_product = self.discriminator(permuted_z)
tc_loss = (log_qz - log_qz_product).mean()
# 总损失
total_loss = recon_loss + alpha * kl_loss + gamma * tc_loss
return total_loss, recon_loss, kl_loss, tc_loss
# 训练示例
if __name__ == "__main__":
model = FactorVAE()
optimizer_G = torch.optim.Adam(list(model.encoder.parameters()) + list(model.decoder.parameters()), lr=1e-4)
optimizer_D = torch.optim.Adam(model.discriminator.parameters(), lr=1e-4)
# 假设 dataloader 已定义
for epoch in range(100):
for x, _ in dataloader:
# 训练生成器(编码器+解码器)
x_recon, mu, logvar = model(x)
z = model.reparameterize(mu, logvar)
total_loss, recon_loss, kl_loss, tc_loss = model.loss_function(x, x_recon, mu, logvar, z)
optimizer_G.zero_grad()
total_loss.backward(retain_graph=True) # 保留计算图
optimizer_G.step()
# 训练判别器
with torch.no_grad():
permuted_z = z[:, torch.randperm(z.size(1))]
log_qz = model.discriminator(z)
log_qz_product = model.discriminator(permuted_z)
d_loss = 0.5 * (F.binary_cross_entropy_with_logits(log_qz, torch.ones_like(log_qz)) +
F.binary_cross_entropy_with_logits(log_qz_product, torch.zeros_like(log_qz_product)))
optimizer_D.zero_grad()
d_loss.backward()
optimizer_D.step()
代码实现细节
- log_qz:判别器对原始潜在变量 z z z(来自联合分布 q ( z ) q(z) q(z))的输出。
- log_qz_product:判别器对维度打乱后的潜在变量 z p e r m u t e d z_{permuted} zpermuted(近似来自乘积分布 Π i = 1 d q ( z i ) \Pi_{i=1}^d q(z_i) Πi=1dq(zi))的输出。
- TC Loss:通过以下公式近似:
T C L o s s = E q ( z ) log q ( z ) Π i = 1 d q ( z i ) ≈ ( l o g _ q z − l o g _ q z _ p r o d u c t ) . m e a n ( ) \begin{aligned} TC Loss&=\mathbb{E}_{q(z)}\log \frac{q(z)}{\Pi_{i=1}^d q(z_i)}\\ &\approx(log\_qz-log\_qz\_product).mean() \end{aligned} TCLoss=Eq(z)logΠi=1dq(zi)q(z)≈(log_qz−log_qz_product).mean() - 在PyTorch中,二元交叉熵损失函数 F.binary_cross_entropy_with_logits 内部已包含Sigmoid激活,因此
-
判别器输出无需额外激活:直接输出logits(未归一化的分数),函数内部会自动应用Sigmoid。
-
数值稳定性:直接使用logits计算损失比手动应用Sigmoid更稳定(避免数值溢出)。
-



















 2603
2603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











