







背景
最近一段时间在做企业分类的实验,给定一个企业信息表,利用关键词从企业名称和经营范围中筛选相关企业。
情况一:企业名称和经营范围任何一个包含关键词;
情况二:企业名称和经营范围同时都包括关键词;
实战
以下述虚假的企业信息表为例子,完成上述关键词任务的筛选
companies_info = [
["氢能未来科技有限公司", "开发和制造氢燃料电池"],
["氢能解决方案公司", "提供氢能储存和运输服务"],
["绿色创新公司", "生产绿色氢气和氢气生成设备"],
["氢能动力系统有限公司", "设计和销售氢能发电设备"],
["纯氢实验室公司", "氢能研究和开发新材料"],
["蓝氢能源公司", "提供氢能基础设施建设服务"],
["氢动企业公司", "销售氢燃料电池车辆和相关配件"],
["生态公司", "绿色能源生产及其工业应用"],
["氢流技术公司", "能源管道和分配系统设计与维护"],
["无限氢能公司", "开发综合氢能解决方案,包括发电和储能"]
]
df = pd.DataFrame(companies_info, columns=["企业名称","经营范围"])
情况一
企业名称和经营范围任何一个包含关键词;
def filter_by_keyword1(
df_: pd.DataFrame,
cols: Union[List[str], str],
keyword: Union[List[str], str]
) -> pd.DataFrame:
if isinstance(cols, str):
cols = [cols]
if isinstance(keyword, str):
keyword = [keyword]
# 使用正则表达式模式匹配所有关键字(可选,但仅当关键字数量很大时可能更有效)
# pattern = '|'.join(r'\b{}\b'.format(re.escape(kw)) for kw in keyword)
# 直接在选定的列上应用str.contains,并使用any沿行方向聚合结果
mask = df_[cols].apply(
lambda row: row.astype(str).str.contains('|'.join(keyword), na=False).any(),
axis=1
)
return df_[mask]
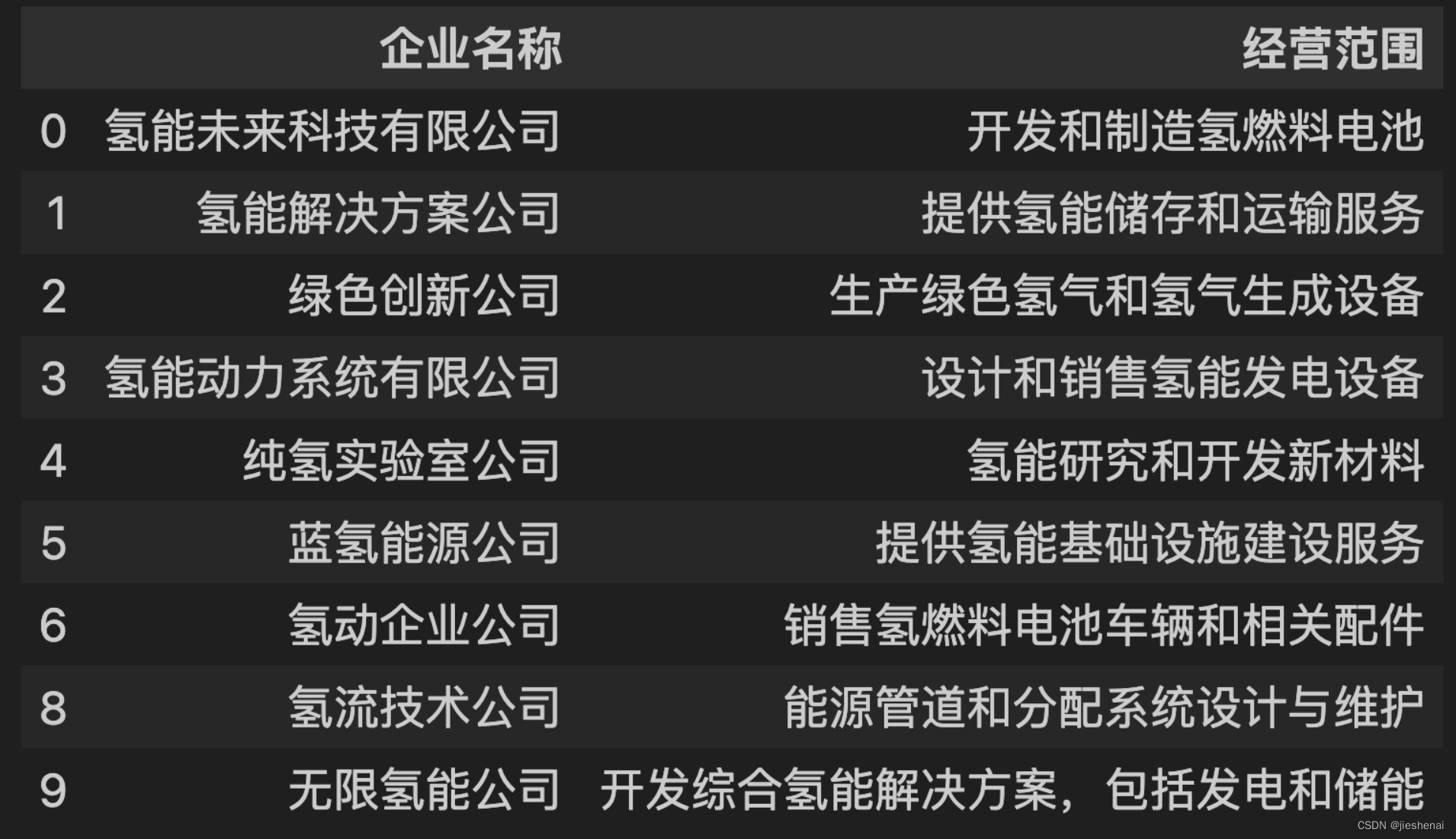
filter_by_keyword1(df, ["企业名称", "经营范围"], "氢")
下述筛选出的企业,企业名称和经营范围,任何一个包含“氢”都会被筛选出来。
也可以只查看企业名称或经营范围包含关键词的企业:
filter_by_keyword1(df, "企业名称", "氢")
filter_by_keyword1(df, "经营范围", "氢")
情况二
企业名称和经营范围同时都包括关键词;
def filter_by_keyword2(
df_: pd.DataFrame, cols: Union[list, str], keyword: str) -> pd.DataFrame:
if isinstance(cols, str):
cols = [cols]
for col in cols:
df_ = df_[df_[col].str.contains(keyword, na=False)]
return df_
可以注意到filter_by_keyword2与filter_by_keyword1的写法不同。
filter_by_keyword1:每次都保留Bool值的下标;
filter_by_keyword2:由于是“与”操作,每次根据Bool值 index 筛选一遍企业,可以减少后续过滤的计算量;
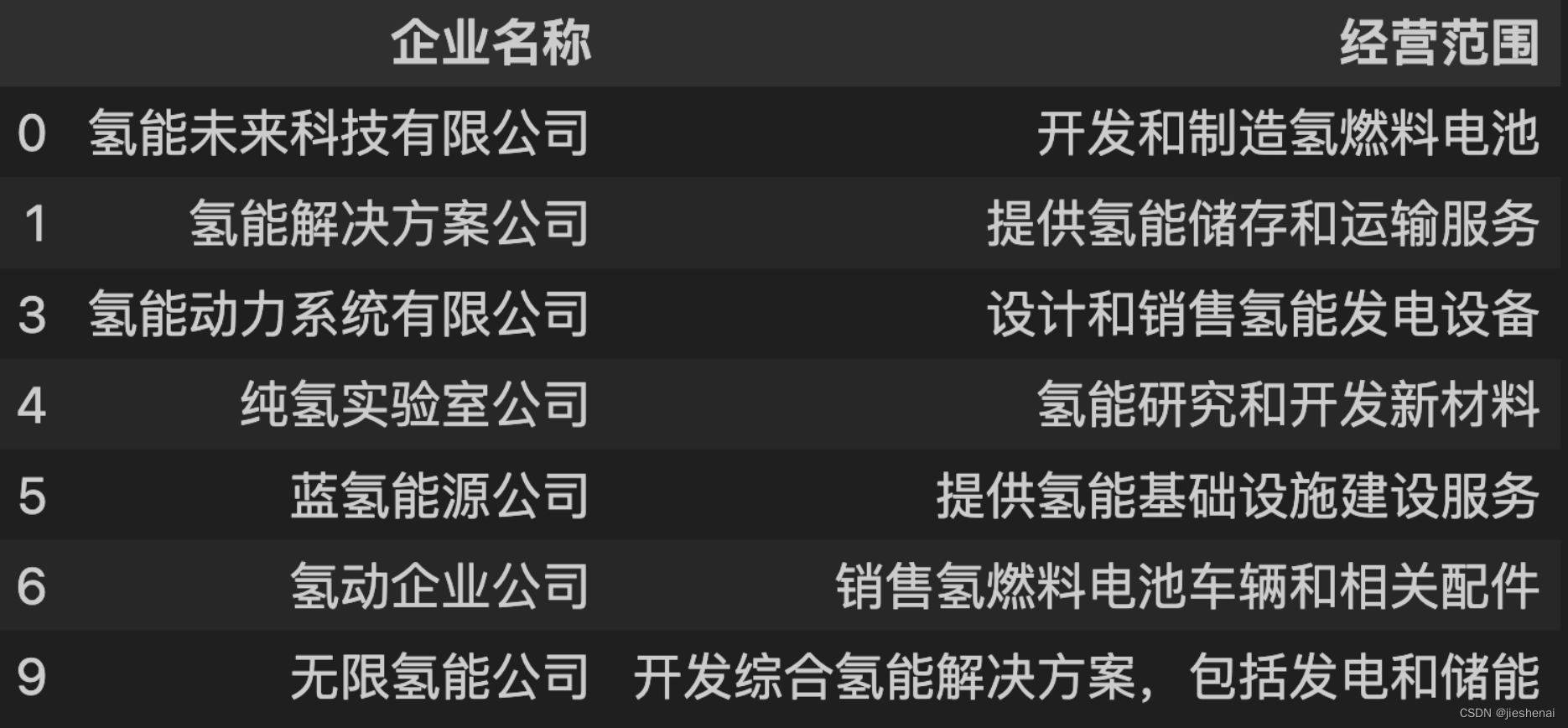
filter_by_keyword2(df, ["企业名称", "经营范围"], "氢")
企业名称或经营范围 必须同时包含“氢”才会被筛选出来。
















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











