






第一章
数据规模驱动了深度学习的发展

图中的数据指的是带有标签的数据
除了数据规模,还有计算能力的提升和算法的创新(sigmoid,RElu)
第二章 LR实现
2.1 识别猫咪
- 将红蓝绿的像素值取出放入特征向量x中,y为标签

- 训练集和测试集的表示符号

2.2 逻辑回归(Logistic Regression, LR)
-
输入x,得到概率值y

由于y需要在[0, 1],如果简单地进行线性回归处理,wT + b有时候会大于一或为负数 -
为避免上述情况,所以将wT + b输入sigmoid函数中,将其对应到[0, 1]

3. 关于w和b的符号约定

2.3 LR cost function
Loss(error) function 单个训练样本上的表现
一般不用
L
(
y
^
,
y
)
=
1
2
(
y
^
−
y
)
2
\mathscr{L}(\hat{y}, y)=\frac{1}{2}(\hat{y}-y)^{2}
L(y^,y)=21(y^−y)2这样的算是函数
因为在梯度下降时,这种损失函数很容易产生很多局部最优解
L
(
y
^
,
y
)
=
−
(
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
)
\mathscr{L}(\hat{y}, y)=-(y \log \hat{y}+(1-y) \log (1-\hat{y}))
L(y^,y)=−(ylogy^+(1−y)log(1−y^))是一个较好的损失函数(logloss)

注意
y
^
\hat{y}
y^也是属于零一之间
Cost function 全体训练样本上的表现
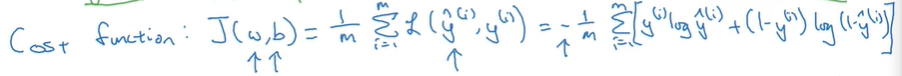
梯度下降

logloss是一个convex function(凸函数)可以找到局部最优解
使用梯度下降计算局部最优解

2.4 LR中单个样本的梯度下降



2.5 m个样本的梯度下降
分别对m个样本的w1,w2,b求偏导,取均值


采用向量化(vectorization)的数据形式来代替显式for循环可以保证处理数据的效率
2.6 向量化(vectorization)
向量化编程和非向量化编程的对比

向量化编程速度是非向量化编程的近480倍

所以尽量避免使用for循环
一些其他向量化的例子

2.7 向量化LR

2.8 向量化LR的梯度输出

2.9 python中的广播
Exapmle1

注意 * 和np.dot()是不一样的,np.dot()才是平时说的矩阵相乘,乘号只是对应位置上相乘
Exapmle2

总结

第三章 神经网络
3.1 约定表达

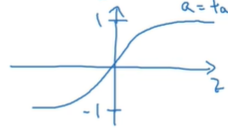
3.2 激活函数
a = t a n h ( z ) a = tanh(z) a=tanh(z)
a
=
tanh
(
z
)
=
e
z
−
e
−
z
e
z
+
e
−
z
a=\tanh (z)=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}}
a=tanh(z)=ez+e−zez−e−z
因为tanh可以让输出的均值更接近零,从而让下一层的学习更加方便。所以tanh通常能得到比sigmoid更好的学习效果
除了二分类的输出用sigmoid,其他情况一般使用tanh更好
激活函数上的上标表示在第几层
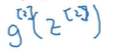
sigmoid和tanh的缺点
当z很大或很小时,激活函数的斜率趋于0,从而会导致模型无法收敛
RElU a = m a x ( 0 , z ) a = max(0, z) a=max(0,z)
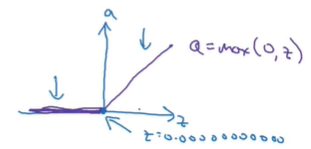
ReLU虽然在原点不可微,但在实际使用中很少会有z = 0求导的情况,或者可以在z = 0时给导数赋值1或是0
LEAKY ReLU a = m a x ( 0.01 z , z ) a = max(0.01z, z) a=max(0.01z,z)

一般用ReLU而很少使用tanh或者sigmoid,因为ReLU不会因为z过大或过小而影响学习速率
3.3 为什么神经网络需要非线性的激活函数
因为没有经过非线性的激活函数处理,从输入到输出无论有多少隐藏层,只不过是把输入重新组合了一遍
最后化简实际和一层隐藏层的效果是一样的,那么多个隐藏层就没有意义

除了输出层,其他层一般都是使用非线性的激活函数

3.4 正向传播与反向传播


3.5 随机初始化
同一层的神经元存在对称性,如果将同一层的所有神经元的参数都初始化为零,则训练后该层所有神经元都是相同的
所以需要随机初始化

通常将参数初始化为较小的值,因为如果初始化的参数较大,得到的z也较大。在使用sigmoid或者tanh时对应激活函数的梯度就会很小。
第四章 深层神经网络
4.1 需要用到的符号

4.2 前向和反向传播
反向传播的单个样本和m个样本的向量形式

三层神经网络示意图

4.3 各矩阵的维数
结论:w[l] = (n[l], n[l-1])
b[l] = (n[l], 1)
n为隐藏单元数
输入x,输出z都是列向量,图中x1和x2组成一个向量,多个输出是进列左右扩展

m个样本的向量形式

在第二维上进行扩展
4.4 参数和超参数
参数(模型学习):w, b
超参数(人为调节): 学习率α,迭代次数iterations,隐藏层L,隐藏单元数n[1], n[2], 激活函数的选择
4.5 Building your Deep Neural Network - Step by Step
- 初始化L层网络的参数W和b
initialize_parameters_deep(layer_dims)
返回一个含有2 * L个参数的字典 - 前向传播
linear_forward(A, W, b)
进行线性计算Z = np.dot(W, A) + b,得到Z
将三个参数(当前层的W,b以及上一层传进来的A)放入cache中
返回Z和cache
linear_activation_forward(A_prev, W, b, activation)
调用linear_forward(A, W, b) 得到Z和cache
将Z放入激活函数中,得到A和cache,cache是输入Z
将linear_forward得到的linear_cache(包含preA,W,b)和激活函数返回的activation_cache(Z)放入一个元组cache中
返回经过激活函数得到的A和cahce
-
前向传播model
由L - 1层relu和1层sigmoid构成
先经过一个L层的for循环,通过linear_activation_forward(A_prev, W, b, activation = ‘relu’)得到A和cache。A用于下一层的输入,cache保存在caches中。
最后经过sigmoid激活函数,得到最终的输出结果AL和cache,同样将cache加入caches中。 -
计算损失函数
用logloss计算AL和Y的损失 -
反向传播
linear_backward(dZ, cache)
利用激活函数反向传过来的dZ和cache中的A_pre, W, b计算dW, db, dA
linear_activation_backward(dA, cache, activation)
先从sigmoid_backward或是relu_backward将后一层的dA转换为dZ
在调用linear_backward(dZ, cache)计算得到dW, db, dA
- 反向传播model
对logloss求导带入AL和Y的到dAL
在将dAL传入linear_activation_backward(dA, cache, activation = ‘sigmoid’)中得到dW, db, dA
将当前层算得的dW, db, dA存入字典grads中
再通过L - 1次for进行反向传播,重复调用linear_activation_backward(dA, cache, activation = ‘relu’),并保存计算得到的梯度在grads中
- 更新参数
用L层for通过保存的grads来更新parameters中的参数
第五章
5. 1 数据划分
- 训练集,验证集(dev),测试集
- 深度学习中,如果数据量很大,那么验证集和测试集的数据不需要占总数据量特别多

- 验证集和测试集最好服从同一分布
- 测试集是对所构建的神经网络进行无偏评估。如果不需要对模型进行评估,那么也可以不用设置测试集(有的人可能在没有设置测试集时,会将验证集称为测试集)
5.2 偏差和方差(bias and variance)

偏差是预测值和标签值的偏差,过大则欠拟合
方差是预测值的方差,过大则过拟合


在训练模型时
- 先考虑bias是否过大,如果过大,则需要用更大的神经网络或者其他算法
- 再考虑var是否过大,如果过大,可以用更多的数据进行训练或者采用正则化
5.3 正则化
- L2正则化
在损失函数J后加上L2范数

b可以省略,因为w是一个高维的参数向量,足以表达高偏差问题 - L1正则化
在损失函数J后加上L1范数

L2比L1更常用
L2范数在多个参数下变成Frobenius范数,即矩阵各个位置的数的平方之和

将加上L2范数的损失函数J对参数W求导得到dW,在用dW更新W时,相当于对原有的W乘了一个(1 - αλ / m)再减去原有梯度下降的部分
相当于减小了原有参数W的权重,从而降低过拟合

5.4 为什么正则化可以减小过拟合
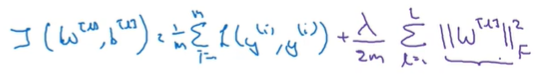
如果λ足够大,模型为了减小损失J,就会把W设置的很小,接近0
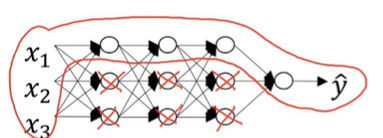
如果将很多W都设置为接近0,那么相当于这些神经元对输出值的影响会很小,从而消除了部分神经元对输出值的影响。
由此简化了神经网络的结构,使得模型从高方差(variance)向高偏差转移(bias)。但存在一个中间值使得模型处于“just right”的状态。
副作用
如果λ设置的很大,那么W会很小,使得Z = WA + b也会很小
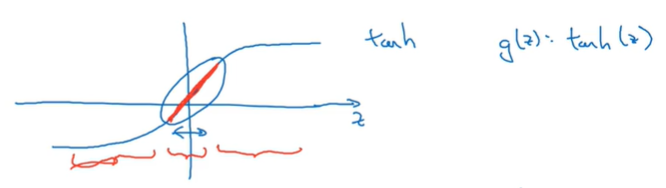
但在一些激活函数中,如tanh。Z在0附近的区间几乎是线性的。我们知道如果网络中的变换都是线性的,整个网络也会呈线性,那么会非常不适合复杂模型的构建。
5.5 dropout正则化

对于每一层,随机舍弃一部分神经元,最后的到一个精简的神经网络用于训练。对多个样本进行多次舍弃,多次训练。
Inverted dropout(目前最常用)
先随机生成一个和输出A形状相同的0-1矩阵D,再将A与D的的各个元素相乘
从而达到舍弃部分结果的目的

假设仅保留keep-prob=0.8的参数,那么矩阵A在与矩阵D相乘后,各个元素都要除以keep-prob=0.8
因为要保持A的期望值不变,否则在测试阶段平均值会变得越来越复杂(因为测试阶段不需要进行dropout,这样可以保持训练和测试时输出结果的一致性)
dropout和L2正则化都有压缩权重的作用,dropout是舍弃部分权重参数.L2是压缩整个W
使用dropout的缺点是很难去检查梯度下降的过程
其他正则化方法 - Adam爆内存直接没了…没保存
第七章
7.1 常见需要调整的超参数
α > β,hidden units,mini-batch size>layers,learing rate delay
- 尽量随机选择超参数

- 如果发现某几个点的取值较好,可以缩小范围在这几个点周围取值

例:为α选择适合的值

假如要在0.0001~1之间选取一个学习率,使用均匀分布那么在0.0001-0.1之间的概率是10%,0.1-1之间的概率是90%,这显然是不合理的

更合理的选择方法如下图:

在指数函数上选择
例:为β选择适合的值
用上述方法在指数级别上选择1-β

7.2 Batch Normalization
和归一化输入类似,将训练时的中间参数A进行归一化后在输入下一层
一般不是归一化A,而是Z。因为一般先进行BN,在传入激活函数

但是有时不希望归一化处理的Z的均值和方差为0和1,因为这样会不利于一些激活函数的处理
所以引入两个新的变量γ和β
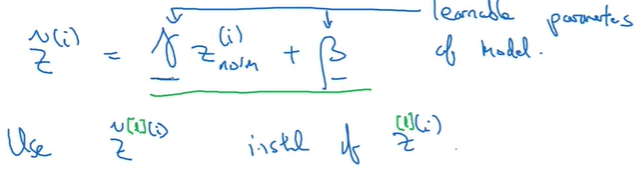
总之,目的是使得各层的所有隐藏单元的输出Z都有固定的均值和方差
具体流程

注意每一次的γ和β可以不一样















 912
912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









